什么是Redis集群
当Redis容量不够的时候,可以通过多几台机器解决。
当Redis写操作,高并发时,怎么分摊压力呢?可以多弄几台服务器,把这些并发分摊到不同的服务器上。
怎么分配到不同的服务器呢,弄一个代理服务器,请求去访问代理服务器,代理服务器去分发这些请求到其他的服务器进行处理。
如下图: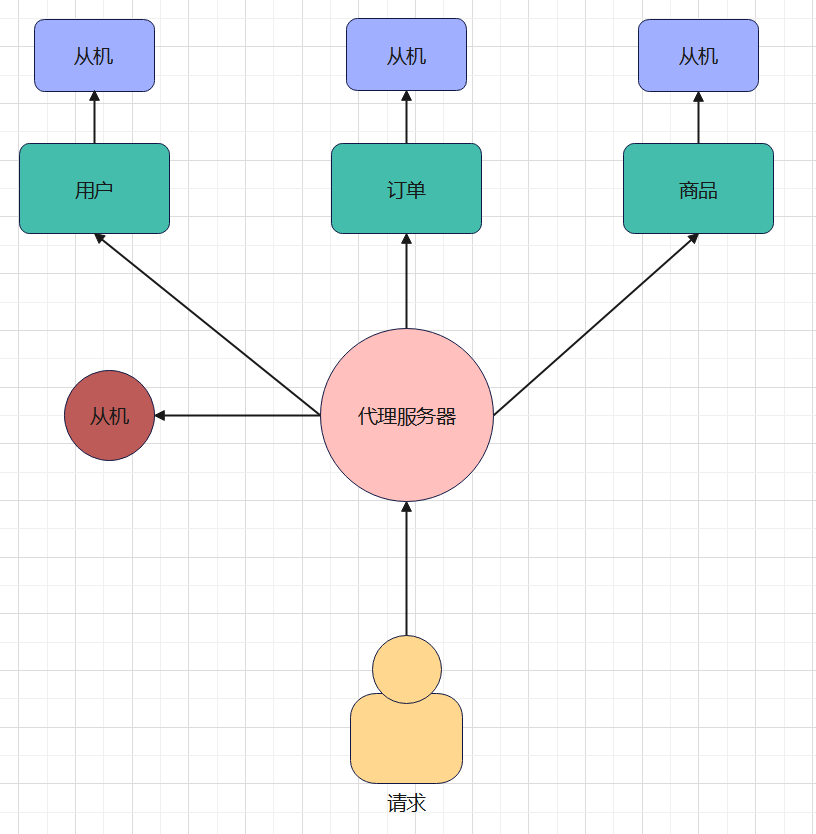
Redis支持无中心化集群。没有代理服务器,任何一台服务器都可以作为集群的入口,如果这台服务器不是处理这个请求的,就传给指定的服务器。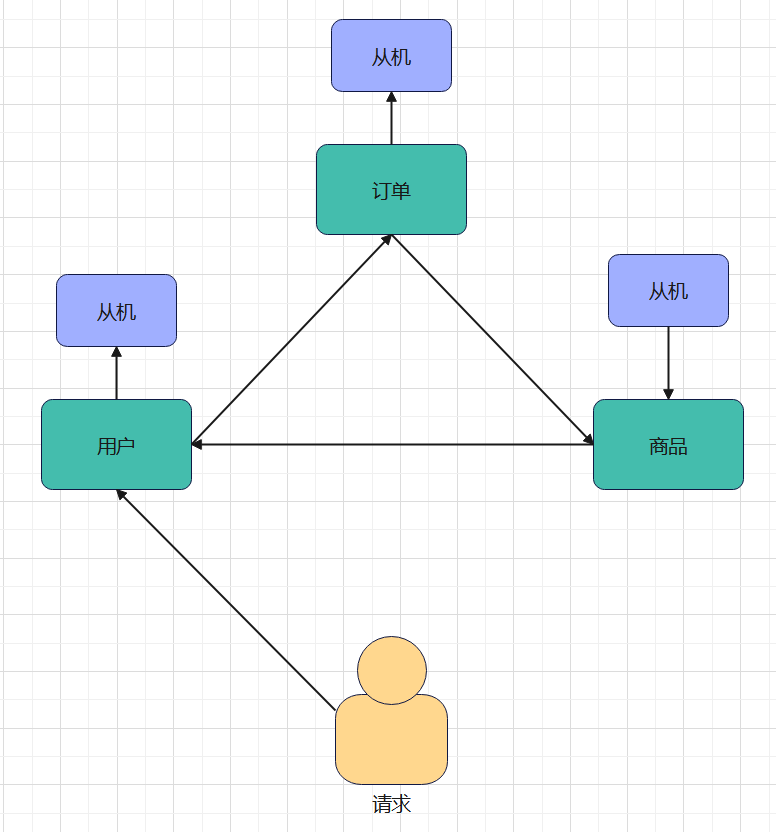
Redis 集群(包括很多小集群)实现了对 Redis 的水平扩容,即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N,即一个小集群存储 1/N 的数据,每个小集群里面维护好自己的 1/N 的数据。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
该模式的 redis 集群特点是:分治、分片。
搭建Redis集群
我们模拟搭建一个6台机的集群,在/myredis目录里面创建6个配置文件,设置不同的端口,
每个配置文件都进行配置,端口号要该,每个文件对应。
include /myredis/redis.confpidfile "/var/run/redis_6001.pid"port 6001dbfilename "dump6001.rdb"masterauth 123456requirepass 123456#打开集群cluster-enabled yes#设定节点配置文件名cluster-config-file nodes-6001.conf#设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换cluster-node-timeout 15000
启动这6个Redis服务
启动了redis服务,会生成如下文件,组合集群必须要有这些配置文件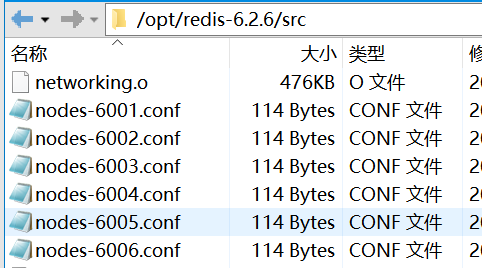
组合redis集群:
首先要确保开启的redis数据库里面没有数据,不然会失败,如果有密码,需要在最后加上 -a 密码
进入cd /opt/redis-6.2.6/src目录(redis解压目录)下执行下面的这段命令
—cluster-replicas 表示从机数量,1表示从机数量就是1
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 -a 123456
执行上面命令后,他会告诉你,怎么分配这些redis服务,谁是主谁是从,输入yes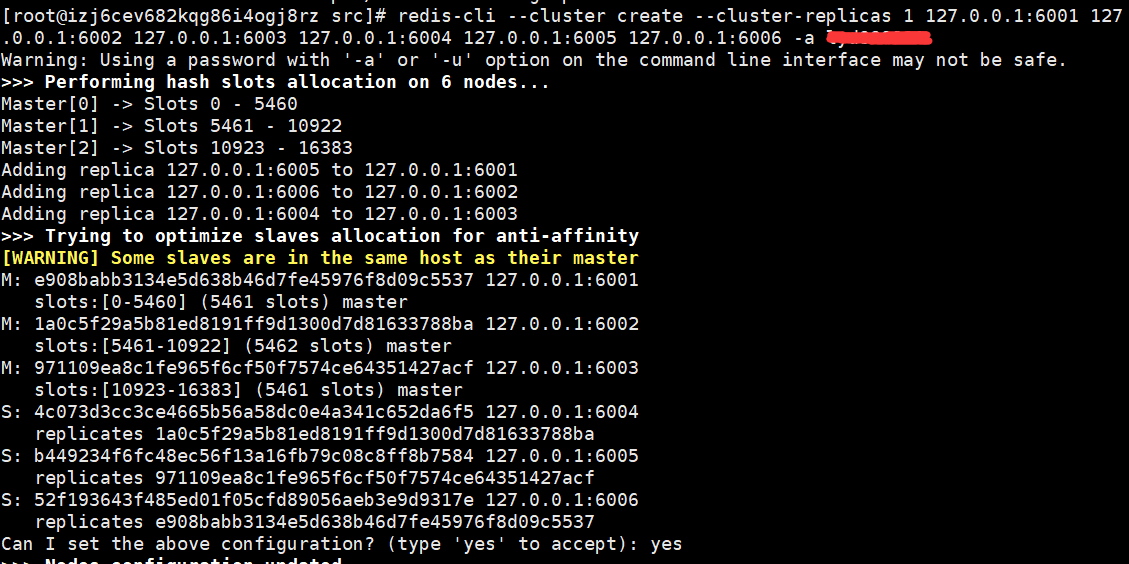
最后成功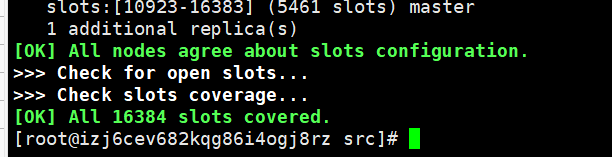
连接集群
-c采用集群策略链接,设置数据会自动切换到相应的写主机。
无中心化集群,连接任何一个主机都可以,需要在连接的时候就设置密码
redis-cli -c -p 6001 -a 密码
使用cluster nodes命令查看集群信息,能看到谁主谁从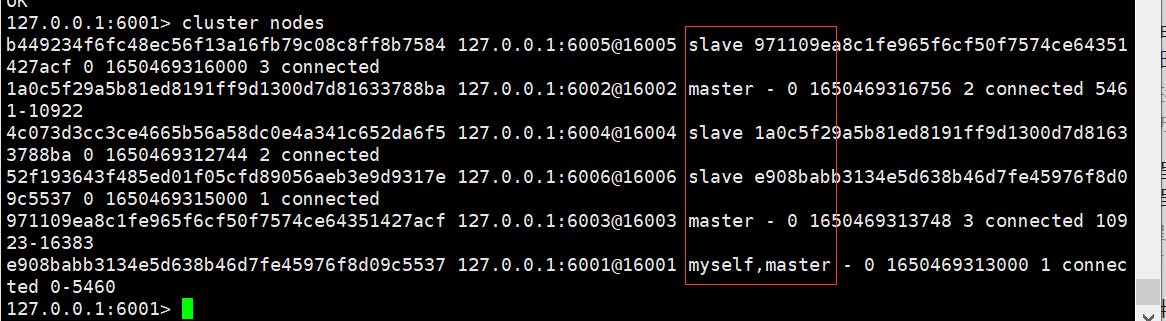
集群分配原则
一个集群至少要有3个主节点
分配原则尽量保证每个主库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
什么是 slots
一个 Redis 集群包含 16384 个插槽(hash slot),数据库中的每个键都属于这 16384 个插槽的其中一个。集群使用公式 CRC16 (key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16 (key) 语句用于计算键 key 的 CRC16 校验和 。
用cluster nodes查看集群,你会发现3个主机后面都跟着一个范围,这就是当前主机的插槽范围
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 6001 负责处理 0 号至 5460 号插槽。
节点 6002 负责处理 5461 号至 10922 号插槽。
节点 6003 负责处理 10923 号至 16383 号插槽。
在集群中设置值
使用redis-cli -c -p 6001 -a 密码进入6001这个主机,我现在设置一个键k1,经过计算,k1的插槽值是12706,在6003的管辖范围,然后重定向到6003。把这个值设置到了6003。
我在6003这个主机的时候设置了一个k2,经过计算k2的插槽值449在6001主机的范围,又重定向到6001.
我又在6001这个主机查询k1,得到k1的插槽值12706,又重定向到6003取出值。
不能同时设置多个键,非要同时设置多个键的话,每个键后面跟一个大括号,里面写一个组名,把这些key全部放到一个组里面,就可以整个组一起插入了。
一些cluster命令
cluster keyslot <key>,查询key在集群中的插槽值cluster countkeysinslot <插槽值>,查询该插槽值下有几个key,当前执行命令的主机得插槽范围一定要在包含这个<插槽值>,否则查不到cluster getkeysinslot <插槽值> <键数量>,返回该插槽值下指定数量的键故障恢复
模拟一下故障,这是当前的集群信息
我把6003挂了,然后上6001,下面是集群配置,6003挂了,6006从机上位。
如果我连上6003,6003就成了6006的从机。
如果所有某一段插槽的主从节点都宕掉,redis 服务是否还能继续?
如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为 yes ,那么整个集群都挂掉。
如果某一段插槽的主从都挂掉,而 cluster-require-full-coverage 为 no ,那么,该插槽数据全都不能使用,也无法存储。
cluster-require-full-coverage在redis.conf里面
Java操作Redis集群
遇到的坑参考
注意本文上面的【搭建Redis集群】里面的这句命令
redis-cli --cluster create --cluster-replicas 1 外网ip:6001 外网ip:6002 外网ip:6003 外网ip:6004 外网ip:6005 外网ip:6006 -a 123456
- 搭建集群的时候,ip要输入服务器外网的ip不要输入127.0.0.1
- 这里的端口6001——6006,需要都在服务器开启这些端口,还要开启端口+10000的端口,比如6001和16001,6002,16002等。6001叫通信端口,16001叫总线端口。

如果没有开放端口+10000的总线端口,搭建redis集群的时候就会一直 Waiting for the cluster to join
- redis配置文件中,bind 127.0.0.1这个要注释掉
- redis配置文件中,protected-mode no
SpringBoot整合操作Redis集群
搭建成功后,修改SpringBoot的配置文件 ```yaml
spring: redis:
#Redis服务器的地址#host: xxx.xxx.xxx.xxx#端口#port: 6379cluster:nodes:- 服务器ip:6001- 服务器ip:6002- 服务器ip:6003- 服务器ip:6004- 服务器ip:6005- 服务器ip:6006#密码password: 123456#数据库索引,默认是0database: 0#链接超时时间(毫秒)timeout: 1800000#连接池最大连接数(使用负值表示没有限制)lettuce:pool:max-active: 20#连接池中的最大空闲连接max-idle: 5#连接池中最小空闲链接min-idle: 0#最大阻塞等待时间(负数表示没有限制)max-wait: -1
测试```javapackage com.example.demo2;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;import redis.clients.jedis.*;import java.util.LinkedHashSet;import java.util.Set;@SpringBootTestclass Demo2ApplicationTests {@Autowired@Qualifier("redisTemplate")private RedisTemplate redisTemplate;@Testvoid t2(){redisTemplate.opsForValue().set("kk1","vv1");String kk1 = (String)redisTemplate.opsForValue().get("kk1");System.out.println(kk1);}}
Jedis操作Redis集群
@Testvoid contextLoads() {//创建集群对象//即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。//无中心化主从集群,无论从哪台主机写的数据,其他主机都能读取到数据Set<HostAndPort> nodes = new LinkedHashSet<>();nodes.add(new HostAndPort("服务器ip",6001));nodes.add(new HostAndPort("服务器ip",6002));nodes.add(new HostAndPort("服务器ip",6003));nodes.add(new HostAndPort("服务器ip",6004));nodes.add(new HostAndPort("服务器ip",6005));nodes.add(new HostAndPort("服务器ip",6006));JedisCluster jedisCluster = new JedisCluster(nodes,3000,1000,100,"密码",new ConnectionPoolConfig());//进行相关的操作jedisCluster.set("b1","vb1");String b1 = jedisCluster.get("b1");System.out.println(b1);}

若有收获,就点个赞吧
0 人点赞
