背景
知识学习
- 发展演进
- 专有名词
开源项目
研究项目先从开源项目开始,找一个想了解或熟悉的业务方向。
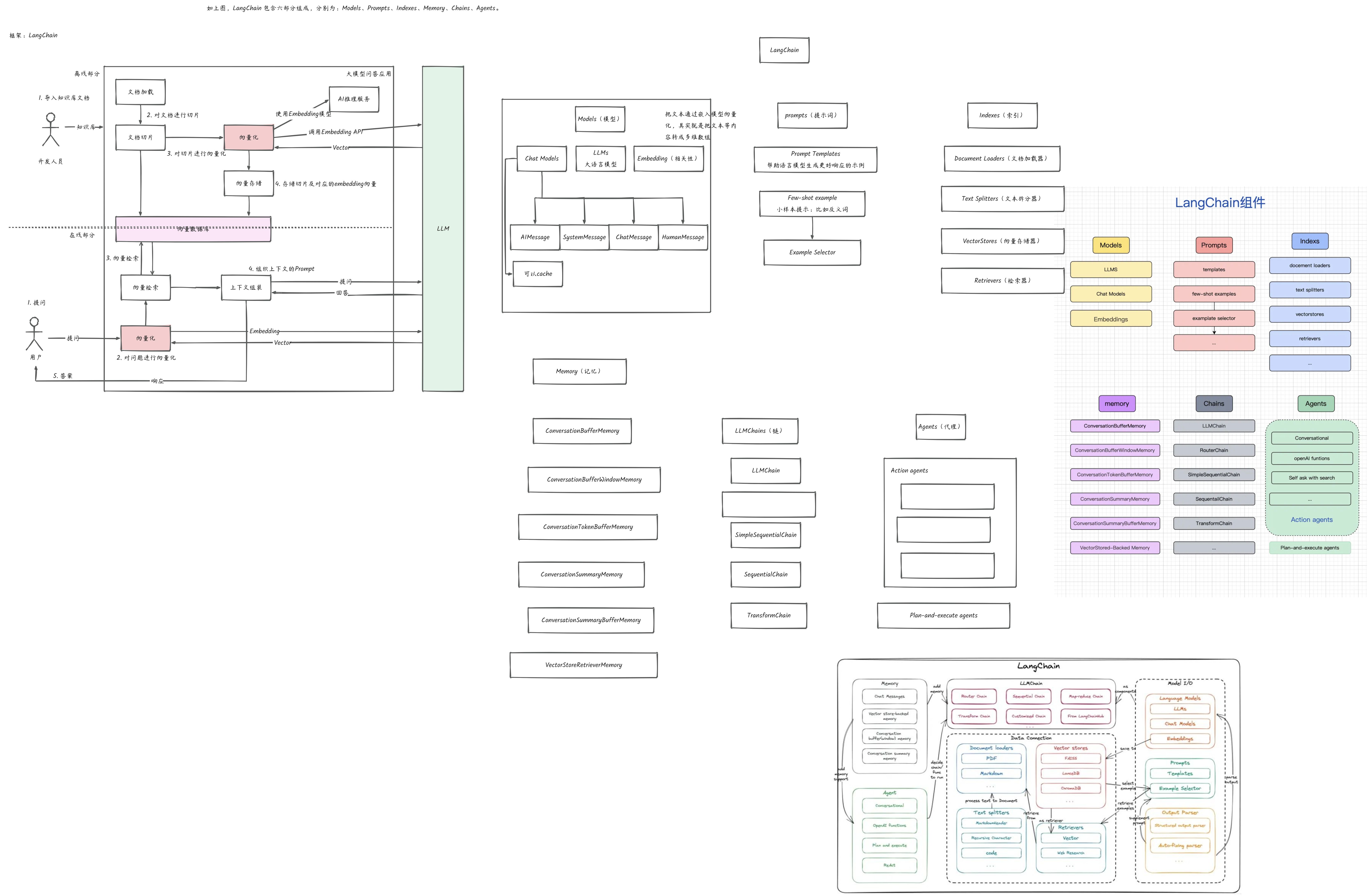
目前市面上通用大模型已经很多而且也比较成熟,但是相较于通用大模型而言很多企业或者个人都需要建立私域数据知识库问答业务。而目前如果想要搭建私域知识问答业务通常有两种方式。 一种是用私域数据在开源模型上进行训练微调;一种是结合向量检索,将专业领域知识和原始提问转化为向量,再使用通用大语言模型进行回答。 这两种方式各有利弊,基于开源模型训练微调存在成本高,包括机器成本和人力成本,另外时效性也较差,但是数据安全性更高;而第二种基于向量检索的形式,工程上需要做的工作比较多,需要文档切片,向量存储,向量检索等技术,同时需要跟通用大模型进行交互,所以会有一些数据安全风险以及一些 Token 额度的消耗。 目前业界使用的方式较多的是第二种,下面是大概的整体流程。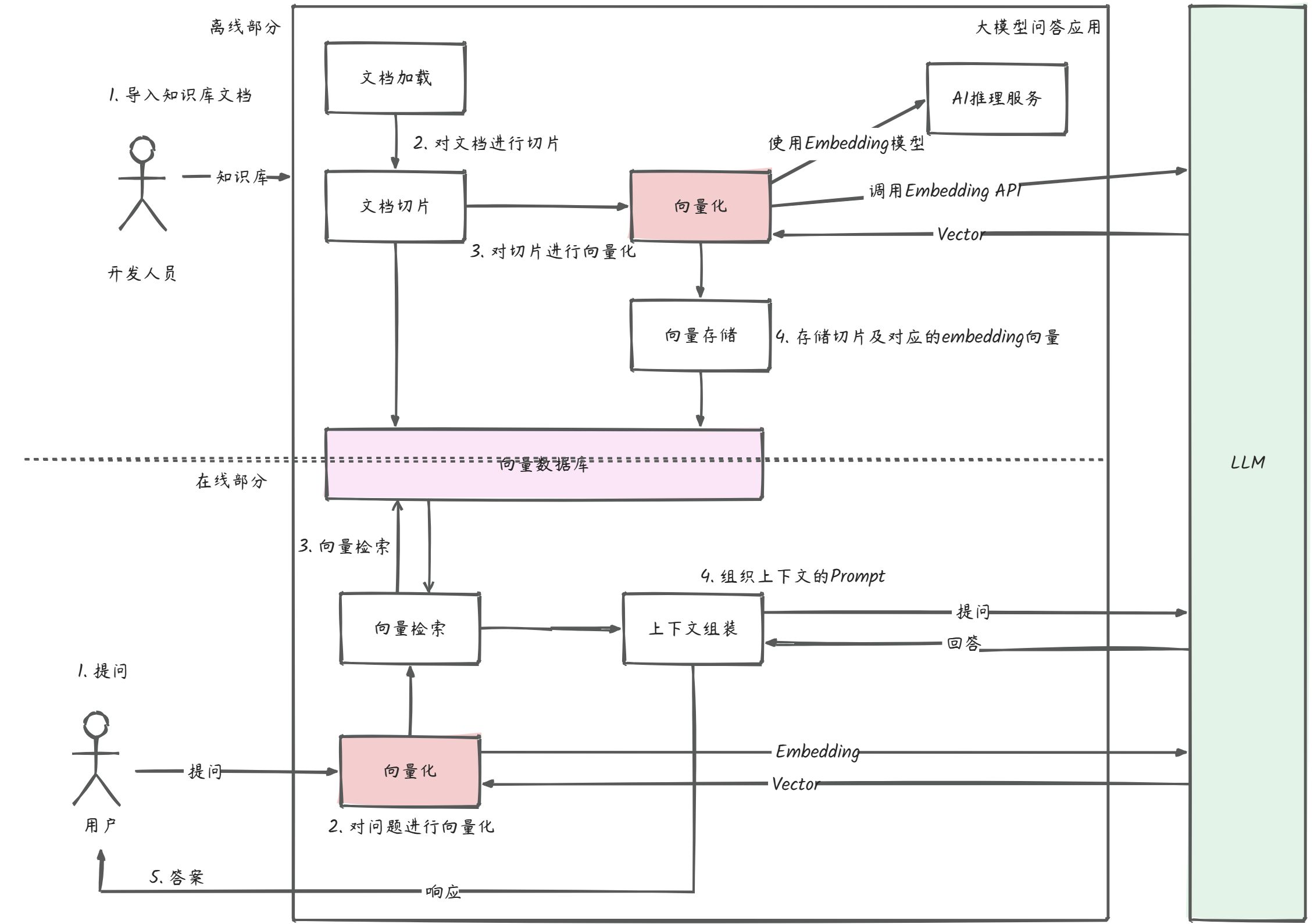
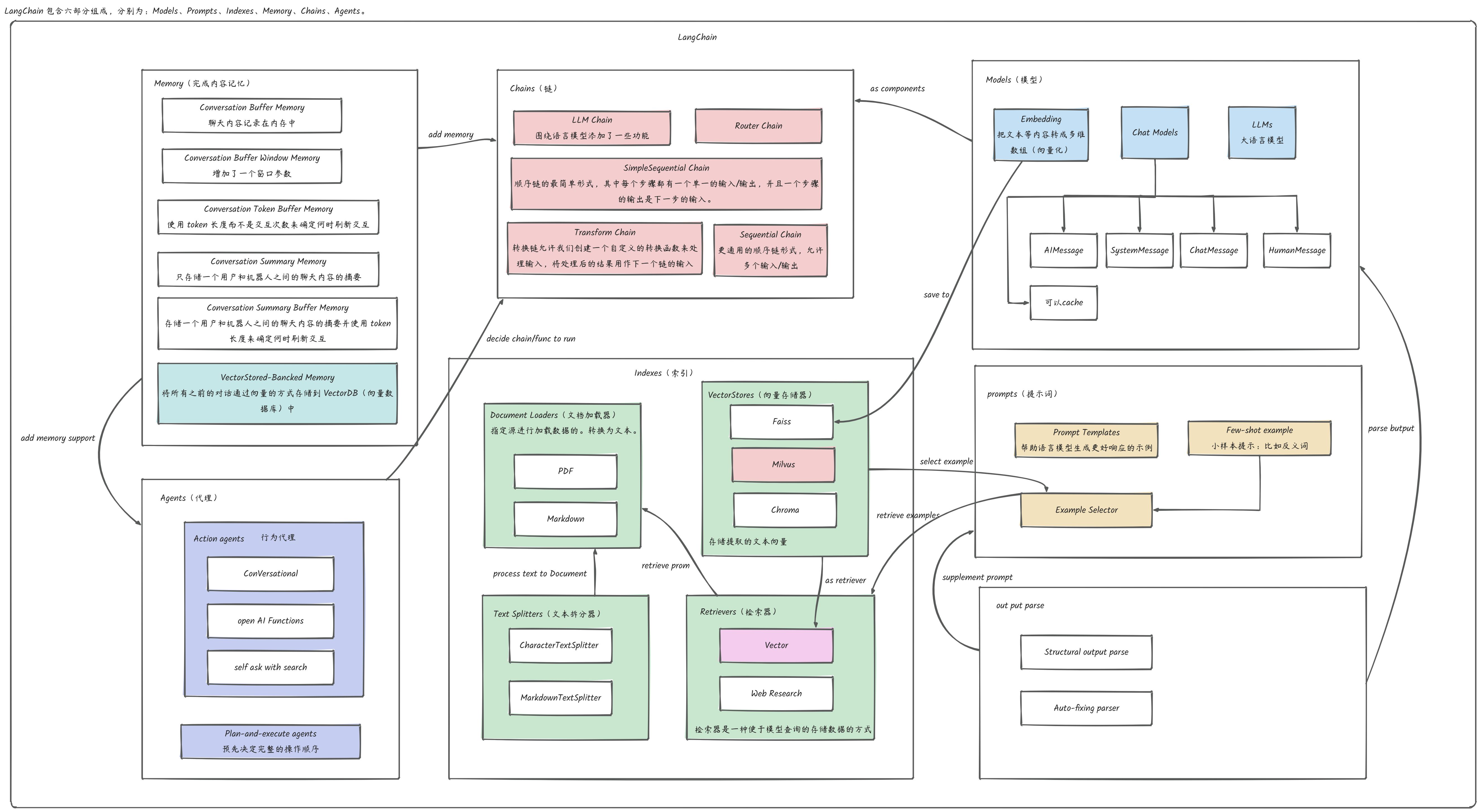
LangChain
不懂的标颜色,依次查看是什么意思- MilVus
- Vector
Lindorm
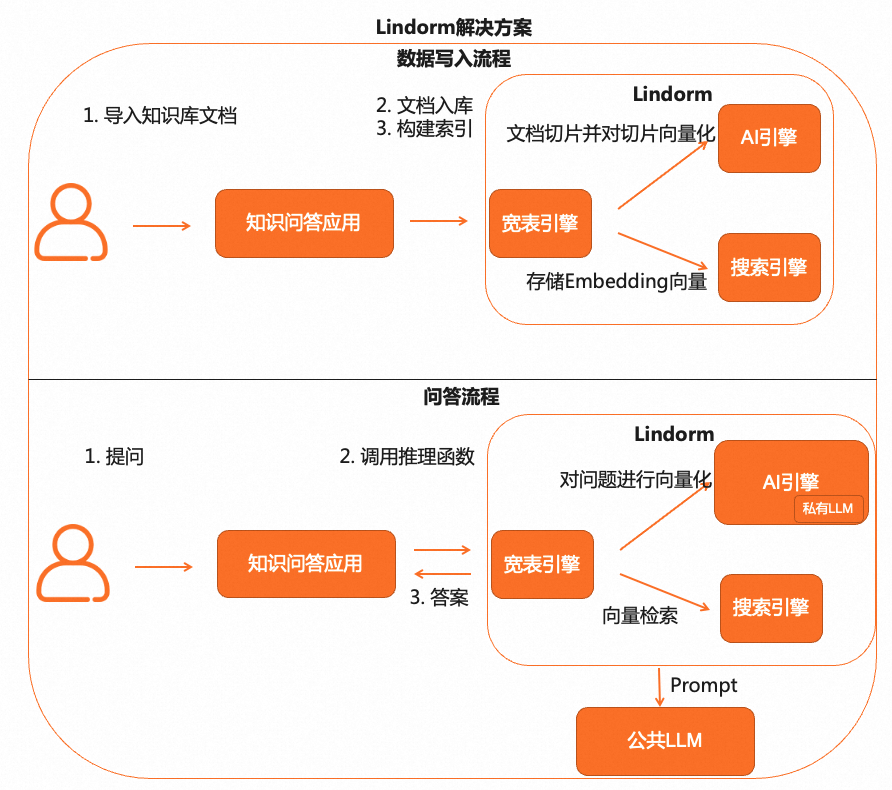
Lindorm 是阿里云的一款多模数据库产品,针对私有知识库问题,云原生多模数据库 Lindorm 推出一站式私域数据知识问答 AIGC 解决方案,结合 Lindorm AI 引擎和内置的向量检索能力,实现仅通过一条 SQL 语句就能简单构建知识问答业务的功能,简化应用开发的工作。 简单来说就是 Lindorm 将文档切片,向量化,向量检索等操作全部封装到底层,用户只需要像操作数据库一样进行数据的插入和通过 SQL 语句来进行知识问答。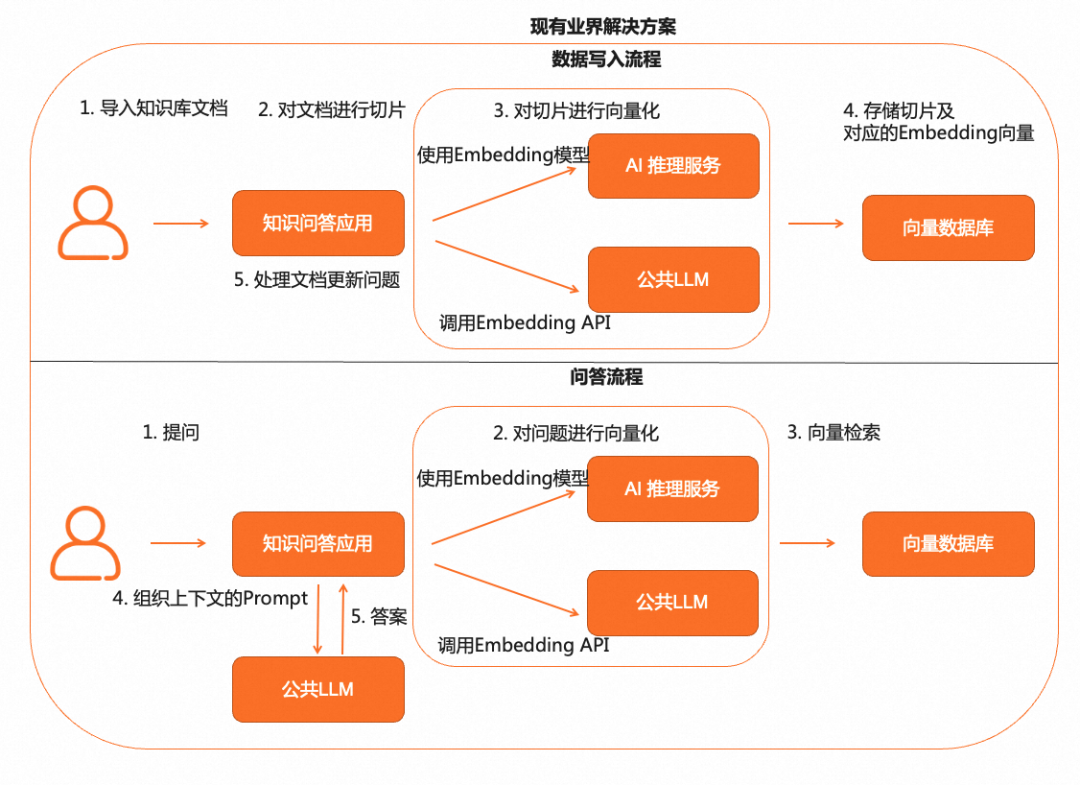

若有收获,就点个赞吧
0 人点赞
