对于开发人员来说,除了日常的编程语言外,因业务需要,我们会去学习或者设计一门在某一业务领域使用的语言,也就是我们经常看到的 DSL(领域特定语言,Domain Specific Language)。如小程序 DSL 等。
对于解析 DSL,我们可以考虑使用支持该 DSL 的现有库,或者手动构建自己的解析器,也可以使用生成解析器的工具或库。今天我们来看下如何使用 Chevrotain 来生成 DSL 的解析器。
Chevrotain 是极快且功能丰富的解析器,可以在 JavaScript 中构建多种解析器。它可以通过对各种用例从简单的配置文来构建完整的编程语言的解析器/编译器/解释器。
在本文中,我们将逐步学习如何使用 Chevrotain 来构建控制虚构的智能灯泡平台的 DSL。
alias green #00ff00alias blue #0000ffalias delay 600brightness 75onwait delaycolor greenwait delaycolor bluewait delayoff
如果你想先查看源码:https://codesandbox.io/s/intelligent-curie-nu3xu?file=/src/parse.js
整体流程
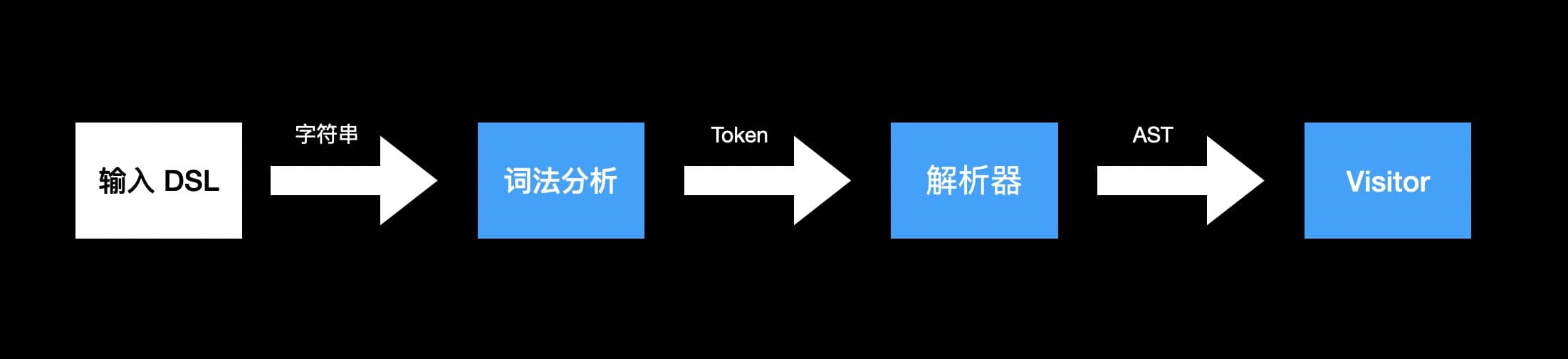
安装
任意新建一个目录,通过 npm 引入即可使用。
npm: npm install chevrotain
const chevrotain = require(`chevrotain`)const { Lexer, CstParser } = chevrotain;
引入 chevrotain ,并导出 Lexer 、 CstParser 。
词法分析定义
接下来,我们需要定义我们的词法分析器。词法分析器的作用是获取输入并将其拆分为解析器可以使用的 Token。为此,我们要为语言中允许的每个字符串创建标记定义。首先创建一个用于保存 Token 的数组,然后创建一个辅助函数,创建新的 Token 并保存到数组中。
const allTokens = [];const createToken = (options) => {const token = chevrotain.createToken(options);allTokens.push(token);return token;};
现在,我们可以定义 DSL 所允许的所有符号了,对于当前的 DSL 而言,空格并不重要。由于 Token 是有词法分析器按顺序处理的,因此添加令牌以首先标识和跳过空格将使我们的词法分析器更加高效。
我们可以先大概浏览下 ITokenConfig 的定义。
export interface ITokenConfig {name: stringcategories?: TokenType | TokenType[]label?: stringpattern?: TokenPatterngroup?: stringpush_mode?: stringpop_mode?: booleanlonger_alt?: TokenTypeline_breaks?: booleanstart_chars_hint?: (string | number)[]}
创建一个空格 Token。
const WhiteSpace = createToken({name: `WhiteSpace`,pattern: /\s+/,group: Lexer.SKIPPED});
根据参数定义,传入名称,正则表达式模式和(可选)组。键字标记以 UpperCamelCase 命名形式。Lexer.SKIPPED 是一个特殊的组,表示该 Token 直接跳过无需处理。
接下来,我们可以用我们的语言定义所有关键字:
const On = createToken({name: `On`,pattern: /on/})const Off = createToken({name: `Off`,pattern: /off/})const Brightness = createToken({name: `Brightness`,pattern: /brightness/})const Color = createToken({name: `Color`,pattern: /color/})const Wait = createToken({name: `Wait`,pattern: /wait/})const Alias = createToken({name: `Alias`,pattern: /alias/})
上面我们定义了 DSL 中的开关、文字值、添加的数字和颜色等标记定义,以及用于 alias 关键字的标识符标记:
const NUMBER = createToken({name: `NUMBER`,pattern: /\d+/})const HEX_COLOR = createToken({name: `HEX_COLOR`,pattern: /#[a-fA-F0-9]{6}/})const IDENTIFIER = createToken({name: `IDENTIFIER`,pattern: /[a-zA-Z]+/})
截至目前,词法分析定义已经完成,我们在用 Chevrotain 提供的 Lexer 创建一个词法分析器的实例。
const LightLexer = new Lexer(allTokens)
解析器
上面对 DSL 的解析已经定义好了,那么还需要定义个解析器。Chevrotain 在 CstParser 类中提供了为此所需的几乎所有内容,因此要获得有效的解析器,我们需要做的就是提供一组规则,这些规则定义了我们语言中有效语句的语法。我们在解析器中需要做的所有事情都发生在构造函数中,因此,我们将从扩展 CstParser 类并为其构造函数添加一些初始逻辑开始。
class LightParser extends Parser {constructor () {super(allTokens)// 此处注意!!!const $ = this$.performSelfAnalysis()}}
最后 $.performSelfAnalysis() 的执行,表示开始应用我们定义的规则。
让我们考虑一下我们语言的语法,并为解析器定义第一个规则。输入的最高级别单位是什么?答案将是一个程序,输入的所有部分的总和。程序由什么组成?一个程序可以说是由一系列语句组成的。在 Chevrotain 解析器定义中,可以这样表示(显示解析器规则的所有示例代码应理解为定义在新的 LightParser 的 constructor 中,并且必须在 $.performSelfAnalysis() 调用之前进行定义):
$.RULE(`program`, () => {$.MANY(() => {$.SUBRULE($.statement)})})
在这里,我们定义了一个名为的规则 program,其中包含许多(零个或多个)子规则 statement。什么是 statement?我们的语言可以理解为一系列命令,因此可以说是其中的任何一条语句:
$.RULE(`statement`, () => {$.OR([{ALT: () => $.SUBRULE($.onStatement)},{ALT: () => $.SUBRULE($.offStatement)},{ALT: () => $.SUBRULE($.colorStatement)},{ALT: () => $.SUBRULE($.brightnessStatement)},{ALT: () => $.SUBRULE($.waitStatement)},{ALT: () => $.SUBRULE($.aliasStatement)}])})
请注意,$.OR 采用对象数组。ALT 传递给该对象的属性是一个正常的解析器规则块,可以包含任意数量的解析器类方法调用,尽管在这种情况下,我们只是调用许多互斥子规则。
现在我们需要为我们为 statement 规则声明的每个子规则定义规则。前两个 on 和 off 是非常简单的:
$.RULE(`onStatement`, () => {/*** On 即上面定义的词法 Token:**
- const On = createToken({
- name:
On, - pattern: /on/
- })
``` */
$.CONSUME(On) })
$.RULE(offStatement, () => {
$.CONSUME(Off) })
这里第一次用到 `$.CONSUME` ,它表示此规则期望遇到的特定 Token。我们前面的两个规则(`program` 和 statement)是非终止规则,因为它们每个都调用子规则。onStatement 和 offStatement(以及语法中的其余语句)是终端规则,因为它们消耗 Token 而没有调用任何其他子规则(并且在结果语法树中未创建任何子节点)。其余规则与 onStatement 和 offStatement 相似,但是每个规则都连续使用多个 Token ,并且对于某些已消耗的令牌,可能允许该令牌为多种类型:```javascript$.RULE(`colorStatement`, () => {$.CONSUME(Color)$.OR([{ALT: () => $.CONSUME(HEX_COLOR)},{ALT: () => $.CONSUME(IDENTIFIER)}])})$.RULE(`brightnessStatement`, () => {$.CONSUME(Brightness)$.OR([{ALT: () => $.CONSUME(NUMBER)},{ALT: () => $.CONSUME(IDENTIFIER)}])})$.RULE(`waitStatement`, () => {$.CONSUME(Wait)$.OR([{ALT: () => $.CONSUME(NUMBER)},{ALT: () => $.CONSUME(IDENTIFIER)}])})$.RULE(`aliasStatement`, () => {$.CONSUME(Alias)$.CONSUME(IDENTIFIER)$.OR([{ALT: () => $.CONSUME(HEX_COLOR)},{ALT: () => $.CONSUME(NUMBER)}])})
最后,我们添加了所有规则并对 CstParser 类进行了扩展,我们创建一个解析器的实例,使用词法分析器接受 DSL 输入并获得结果,将词法分析结果作为解析器的输入。通过调用解析器的入口 program(在本例中为)来创建语法树,并执行一些基本的错误处理:
const parser = new LightParser()const lexed = LightLexer.tokenize(`alias green #00ff00alias blue #0000ffalias delay 600brightness 75onwait delaycolor greenwait delaycolor bluewait delayoff`);if (lexed.errors.length) {console.log(`Lexer error!`)console.log(lexed.errors)throw new Error()}parser.input = lexed.tokensconst cst = parser.program()if (parser.errors.length) {console.log(`Parser error!`)console.log(parser.errors)throw new Error()}
Visitor/Interpreter
截止目前,通过 parser 已经可以得到一个表示程序结构的语法树了,如果我们希望能够对此做一些事情。Chevrotain 提供了一个我们可以扩展的类 BaseCstVisitor ,以创建特定于解析器的访问者类。我们首先从解析器中获取一个基类并进行扩展。我们还将在其构造函数中为模拟灯泡设置状态。
const BaseCstVisitor = parser.getBaseCstVisitorConstructor()class LightInterpreter extends BaseCstVisitor {constructor () {super()this.light = {on: false,brightness: 100,color: `#ffffff`}this.scope = {}this.validateVisitor()}}
与解析器一样,我们必须在构造函数的顶部调用 super ,并且还需要调用this.validateVisitor()。我们的灯泡有几个状态,我们还向实例添加了一个属性 scope,以存储 alias 关键字创建的所有属性。对于在解析器中定义的每个规则,解释器类将具有一个实例方法。每个方法都可以获取它们所在的语法树节点的当前值 context,并且可以返回一个值。与解析器一样,我们可以从 program 和 statement 开始:
program (context) {for (const statement of context.statement) {this.visit(statement)}}statement (context) {if (context.onStatement) {this.visit(context.onStatement)} else if (context.offStatement) {this.visit(context.offStatement)} else if (context.colorStatement) {this.visit(context.colorStatement)} else if (context.brightnessStatement) {this.visit(context.brightnessStatement)} else if (context.waitStatement) {this.visit(context.waitStatement)} else if (context.aliasStatement) {this.visit(context.aliasStatement)}}
解析器的语法表明,一个程序包含许多语句,因此我们的 program 访问者遍历其子语句(从context.statement)并访问每个子语句(在每个子节点上调用 visitor 方法)。请注意,如果存在任何子节点,则该子节点始终为数组(否则为 null );即使语法定义 program 为包含 single statement, context.statement 与 program 仍将是具有单个元素的数组。我们可以查看其中任何一个都不为 null 的表达式,并访问该表达式。在 this.visit 节点数组上调用第一个表达式。
接下来的声明中,将简单的定义 onStatement 和 offStatement visitor。当调用这些语句时,我们要适当地更改灯泡的状态。对于所有更改灯泡状态的语句,可以打印 log 以查看发生了什么:
onStatement (context) {console.log(`turning light on (light was ${this.light.on ? `on` : `off`})`)this.light.on = true}offStatement (context) {console.log(`turning light off (light was ${this.light.on ? `on` : `off`})`)this.light.on = false}
接下来的语句也会影响灯泡的状态,但是按照我们的语法定义,参数标识符通过 alias 定义。所以我们可以检查是否存在标识符,并使用存储在 this.scope 中的值(如果存在)或使用传入的文字值。请注意,每个子节点都有一个 image 属性,其中包含已处理成 Token 的文字字符串。
colorStatement (context) {const color = context.IDENTIFIER ? this.scope[context.IDENTIFIER[0].image] : context.HEX_COLOR[0].imageconsole.log(`setting color to ${color} (color was ${this.light.color})`)this.light.color = color}brightnessStatement (context) {const value = context.IDENTIFIER ? this.scope[context.IDENTIFIER[0].image] : parseInt(context.NUMBER[0].image, 10)console.log(`brightness was ${this.light.brightness}`)console.log(`setting brightness to ${value}`)this.light.brightness = value}waitStatement (context) {const value = context.IDENTIFIER ? this.scope[context.IDENTIFIER[0].image] : parseInt(context.NUMBER[0].image, 10)console.log(`waiting ${value}`)}
我们需要定义的最后一条语句是 aliasStatement ,其行为与其他语句非常相似,但是设置了一个属性 this.scope :
aliasStatement (context) {const identifier = context.IDENTIFIER[0].imageconsole.log(`setting ${identifier} to ${context.NUMBER ? context.NUMBER[0].image : context.HEX_COLOR[0].image}`)if (context.NUMBER) {this.scope[identifier] = parseInt(context.NUMBER[0].image, 10)} else {this.scope[identifier] = context.HEX_COLOR[0].image}}
最后,我们可以创建解释器的实例,并使其访问上一节中创建的语法树:
const interpreter = new LightInterpreter()interpreter.visit(cst)
至此,我们已经完成了一个新的 DSL 解析全过程。
相关资料

若有收获,就点个赞吧
0 人点赞
