资源规划
| 组件 | bigdata-node1 | bigdata-node2 | bigdata-node3 |
|---|---|---|---|
| OS | centos7.6 | centos7.6 | centos7.6 |
| JDK | jvm | jvm | jvm |
| HDFS | NameNode/SecondaryNameNode/DataNode/JobHistoryServer/ApplicationHistoryServer | DataNode | DataNode |
| YARN | ResourceManager/NodeManager | NodeManager | NodeManager |
安装介质
版本:hadoop-2.7.2.tar.gz
下载:http://archive.apache.org/dist/hadoop/core
环境准备
安装CentOS
参考:《基于Vagrant的CentOS7.6》
安装JDK
SSH免密
参考:《CentOS7.6-SSH免密》
集群配置
# 设置主机名(集群所有节点)sudo vi /etc/hosts
配置如下:
# 127.0.0.1 localhost# 注意:务必注释# 127.0.1.1 ${HOST_NAME}# 本机内网IP建议配置与第一行(多个域名情况下)192.168.0.101 bigdata-node1192.168.0.102 bigdata-node2192.168.0.103 bigdata-node3
安装Hadoop
先在节点bigdata-node1上安装,之后分发到bigdata-node2、bigdata-node3。
cd /sharetar -zxvf hadoop-2.7.2.tar.gz -C ~/modules/# 清理安装介质rm -rf ~/modules/hadoop-2.7.2/share/docrm -rf ~/modules/hadoop-2.7.2/*/*.cmdrm -rf ~/modules/hadoop-2.7.2/*/*/*.cmd
(1).HDFS单机部署
创建相关目录
mkdir ~/modules/hadoop-2.7.2/tmp ## hadoop临时目录,core-site.xml的hadoop.tmp.dir属性相关sudo chmod -R a+w ~/modules/hadoop-2.7.2/tmp
hdfs配置
1.配置hadoop-env.sh。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
配置如下:
export JAVA_HOME=/home/vagrant/modules/jdk1.8.0_221
2.配置core-site.xml。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
配置如下:
<!--默认文件系统的名称(uri's的authority部分用来指定host, port等。默认是本地文件系统。)--><property><name>fs.defaultFS</name><value>hdfs://bigdata-node1:9000</value></property><!--WEB UI访问数据使用的用户名 --><property><name>hadoop.http.staticuser.user</name><value>vagrant</value></property><!-- Hadoop的临时目录,服务端参数,修改需重启。NameNode的Image/Edit目录依赖此配置 --><property><name>hadoop.tmp.dir</name><value>/home/vagrant/modules/hadoop-2.7.2/tmp</value></property>
3.配置hdfs-site.xml。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
配置如下:
<!--解决内部网络和外部网络访问的问题 --><property><name>dfs.http.address</name><value>0.0.0.0:50070</value></property><property><name>dfs.namenode.secondary.http-address</name><value>bigdata-node1:50090</value></property><!-- HDFS数据副本数,默认3副本:本节点+同机架节点+其他机架节点,一般不大于datanode的节点数,建议默认3副本--><property><name>dfs.replication</name><value>1</value></property><!-- HDFS中启用权限检查配置--><property><name>dfs.permissions.enabled</name><value>false</value></property>
格式化**NameNode**
格式化HDFS用于初始化NameNode管理的镜像和操作日志文件。
# 清理logs和tmprm -rf ~/modules/hadoop-2.7.2/logs/*rm -rf ~/modules/hadoop-2.7.2/tmp/*cd ~/modules/hadoop-2.7.2/bin/hdfs namenode -format
出现下列提示表示格式化成功。
INFO common.Storage: Storage directory /*/*/tmp/dfs/name has been successfully formatted.
单机启动**hdfs**
core-site.xml,这里配哪一台(bigdata-node1),哪一台启动namenode。
cd ~/modules/hadoop-2.7.2/# 启动NameNodesbin/hadoop-daemon.sh start namenode# 启动DataNodesbin/hadoop-daemon.sh start datanode
启动完成后,输入jps查看进程,如果看到以下进程,表示NameNode节点基本ok了。
jps**** DataNode**** NameNode
Web UI验证:http://bigdata-node1:50070
单机停止**hdfs**
cd ~/modules/hadoop-2.7.2/# 停止NameNodesbin/hadoop-daemon.sh stop namenode# 停止DataNodesbin/hadoop-daemon.sh stop datanode
(2).YARN单机部署
yarn__配置
1.配置mapred-env.sh。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/mapred-env.sh
配置如下:
export JAVA_HOME=/home/vagrant/modules/jdk1.8.0_221
2.配置mapred-site.xml。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2cp ${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template ${HADOOP_HOME}/etc/hadoop/mapred-site.xmlvi ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
配置如下:
<!-- 配置MapReduce运行环境 ,yarn/yarn-tez --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 日志查看IPC及WEB UI配置--><property><name>mapreduce.jobhistory.address</name><value>bigdata-node1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>bigdata-node1:19888</value></property>
3.配置yarn-env.sh。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/yarn-env.sh
配置如下:
export JAVA_HOME=/home/vagrant/modules/jdk1.8.0_221
4.配置yarn-site.xml。
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
配置如下:
<!-- ResourceManager节点 --><property><name>yarn.resourcemanager.hostname</name><value>bigdata-node1</value></property><!--解决内部网络和外部网络访问的问题 --><property><name>yarn.resourcemanager.webapp.address</name><value>0.0.0.0:8088</value></property><!--日志聚合到HDFS提供给WEB UI查看 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>10000</value></property><!-- NodeManager上运行的附属服务,用于提升Shuffle计算性能。mapreduce_shuffle/spark_shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 如果没配置ApplicationMaster入口无法使用 --><property><name>yarn.resourcemanager.webapp.address</name><value>bigdata-node1:8088</value></property>
单机启动__YARN
yarn-site.xml,这里配哪一台(bigdata-node1),哪一台启动ResourceManager。
cd ~/modules/hadoop-2.7.2/## 启动resourcemanagersbin/yarn-daemon.sh start resourcemanager## 启动nodemanagersbin/yarn-daemon.sh start nodemanager## 启动log服务,默认日志路径:/tmp/hadoop-yarn/staging/historysbin/mr-jobhistory-daemon.sh start historyserver
输入jps查看进程,如果看到以下进程,表示ResourceManager节点基本ok了。
jps**** ResourceManager**** NodeManager**** JobHistoryServer
Web UI验证:http://bigdata-node1:8088
单机停止__YARN
cd ~/modules/hadoop-2.7.2/sbin/yarn-daemon.sh stop resourcemanagersbin/yarn-daemon.sh stop nodemanagersbin/mr-jobhistory-daemon.sh stop historyserver
(3).HDFS集群部署
第一次启动前,清除各节点tmp目录,并重新格式化NameNode。
## 清理logs和tmprm -rf ~/modules/hadoop-2.7.2/logs/*rm -rf ~/modules/hadoop-2.7.2/tmp/*cd ~/modules/hadoop-2.7.2/bin/hdfs namenode -format
配置__slaves
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/slaves
配置如下:
bigdata-node1bigdata-node2bigdata-node3
环境变量设置
vi ~/.bashrc # :$到达行尾添加
配置如下:
export HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
分发__Hadoop
scp -r ~/modules/hadoop-2.7.2 vagrant@bigdata-node2:~/modules/scp -r ~/modules/hadoop-2.7.2 vagrant@bigdata-node3:~/modules/scp ~/.bashrc vagrant@bigdata-node2:~/.bashrcscp ~/.bashrc vagrant@bigdata-node3:~/.bashrc
注:如果Hadoop临时目录(tmp)不在Hadoop包中,slaves上仍然要先手动创建并赋权。
环境变量生效:source ~/.bashrc
集群启动__hdfs
core-site.xml,这里配哪一台(bigdata-node1),哪一台启动namenode。
cd ~/modules/hadoop-2.7.2/sbin/start-dfs.sh
启动完成后,输入jps查看进程,如果看到以下进程,表示NameNode节点基本ok了。
jps**** DataNode**** NameNode**** SecondaryNameNode
Web UI验证:http://bigdata-node1:50070
集群停止__hdfs
cd ~/modules/hadoop-2.7.2/sbin/stop-dfs.sh
(4).YARN集群部署
集群启动__YARN
yarn-site.xml,这里配哪一台(bigdata-node1),哪一台启动ResourceManager。
cd ~/modules/hadoop-2.7.2/sbin/start-yarn.sh## 启动log服务,默认日志路径:/tmp/hadoop-yarn/staging/historysbin/mr-jobhistory-daemon.sh start historyserver
输入jps查看进程,如果看到以下进程,表示ResourceManager节点基本ok了。
jps**** ResourceManager**** NodeManager**** JobHistoryServer
Web UI验证:http://bigdata-node1:8088
集群停止__YARN
cd ~/modules/hadoop-2.7.2## 停止log服务sbin/mr-jobhistory-daemon.sh stop historyserversbin/stop-yarn.sh
MR__作业验证
cd ~/modules/hadoop-2.7.2## 创建MR输入目录bin/hdfs dfs -mkdir -p /tmp/input## bin/hdfs dfs -rm -r /tmp/output # 删除MR输出目录## 上传文件到input目录bin/hdfs dfs -put ~/modules/hadoop-2.7.2/etc/hadoop/core-site.xml /tmp/inputbin/hdfs dfs -ls /tmp/inputbin/hdfs dfs -text /tmp/input/core-site.xml## hadoop jar按mr1或mr2(yarn)运行job,决定是否配置yarn;yarn jar按yarn方式运行job。bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /tmp/input /tmp/outputbin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /tmp/input /tmp/output## 查看job结果bin/hdfs dfs -cat /tmp/output/part*
注意:MR输出目录不要提前建立,如果存在则删除或者修改为别的输出路径。
WorldCount案例
插件安装(选做)
在eclipse上安装Hadoop-Eclipse-Plugin插件,则可以查看hdfs目录结构,上传数据文件。
版本:hadoop-eclipse-plugin-2.7.3.jar or hadoop-eclipse-plugin-2.6.4.jar
安装:https://blog.csdn.net/qq_38709565/article/details/82768659
WorldCount原理
MapReduce采用分而治之的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是“任务的分解和结果的汇总”。
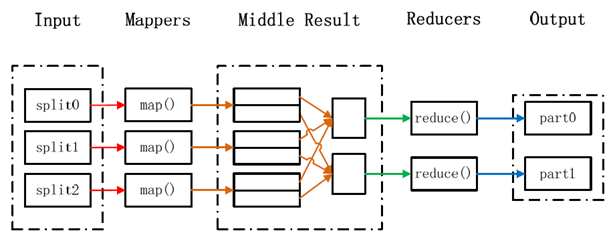
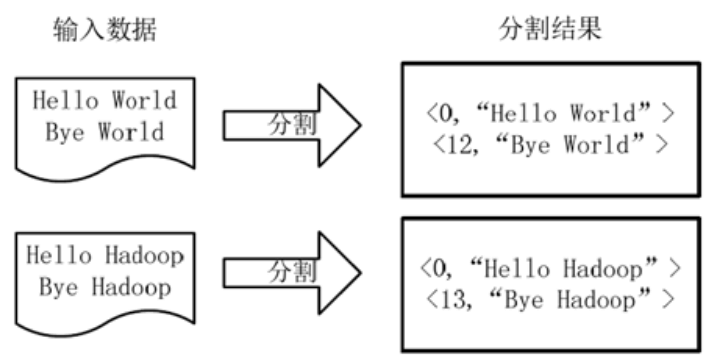
WordCount(单词计数)是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello world.”,其主要完成的功能是:统计一系列文本文件每个单词出现的次数。WordCount具体计算流程如下:(1).分割
将文件拆分成 splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成
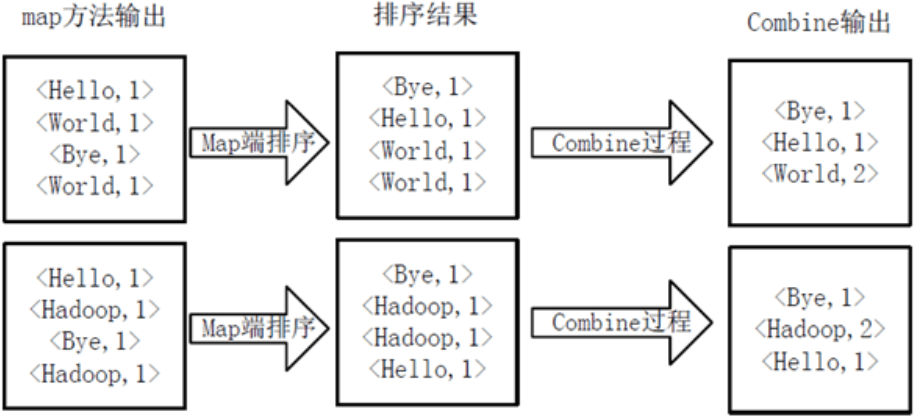
(2).Map
将分割好的

(3).Combine
得到map方法输出的
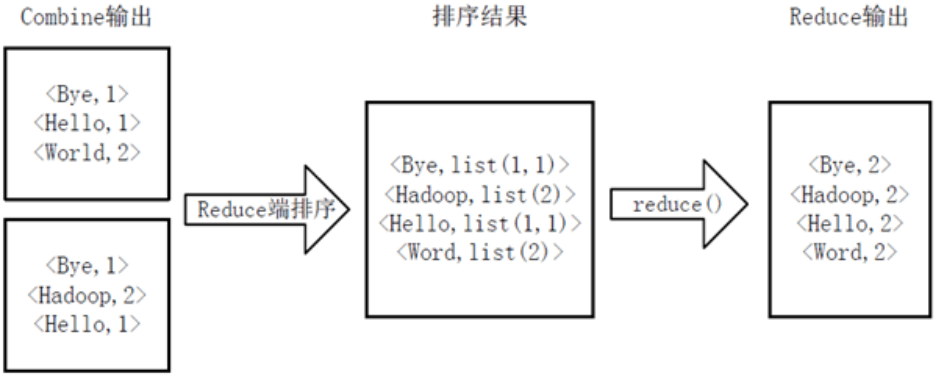
(4).Reduce
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的
MR编程实现
参考1:https://blog.csdn.net/u010416101/article/details/89050203
参考2:https://blog.csdn.net/chunfenxiaotaohua/article/details/100073912
代码:BigData_Demo_20200510.zip# windows打包编译,之后将jar包拷贝至vagrant共享目录share即可mvn clean package -DskipTests -Dfast
运行MR程序:
cd ~/modules/hadoop-2.7.2## 删除MR输出目录bin/hdfs dfs -rm -r /tmp/outputbin/yarn jar /share/bigdata_demo.jar## 查看job结果bin/hdfs dfs -cat /tmp/output/part*
说明:代码有更新,可支持windows本地开发测试,入口类为:*DriverLocal.java。

若有收获,就点个赞吧
0 人点赞
