TinyLog
以列文件的形式将数据存储到磁盘上,缺点是不支持索引,没有并发控制,生产环境不用。
Memory
数据以未压缩的原始格式存储在内存中,缺点是重启数据会丢失,不支持索引,但是读写没有阻塞操作,在数据量不大且简单查询具有非常高的性能。
MergeTree
mergetree是经常用到的表引擎,建表时使用示例如下:
create table if not exists student(id int,name String,age UInt8,create_time DateTime) ENGINE MergeTreepartition by toYYYYMMDD(create_time)primary key(id)order by (id, age)insert into student(`id`, `name`, `age`, `create_time`)VALUES (100, 'ma', 10, '2021-08-06'),(101, 'ma', 10, '2021-08-07')
该sql将会创建一个名称为student的表,指定表引擎为MegerTree.
<font style="color:#F5222D;">partition by</font> 表分区字段,该语句中,是根据日期进行分区,可选项
分区会将数据保存在不同的目录下,一个分区一个目录,如果建表的时候不写分区,那就使用<font style="color:#F5222D;">all</font>分区,即不进行分区如:

分区名称格式为:分区值 + 最小区块编号 + 最大区块编号 + 合并次数,由于刚刚创建表时使用的是create_time进行分区,所以会有20210806 和 20210807的分区,出现有两个20210807分区的原因是因为,刚刚创建的数据,clickhouse并不会马上进行分区合并,而是需要等待10-15分钟才会自动进行分区合并,合并后的分区名是20210807_8_9_1,也可以使用命令**OPTIMIZE TABLE **student** FINAL**进行分区合并,但是分区合并后的原数据不会马上进行删除,依然要等clickhouse进行清理,如下图:

<font style="color:#F5222D;">primary key</font> 主键索引,在clickhouse中,主键是一级索引,主键不会添加唯一约束,主键是一个稀疏索引,可选项
比如:在数据库再插入一条id=100的记录
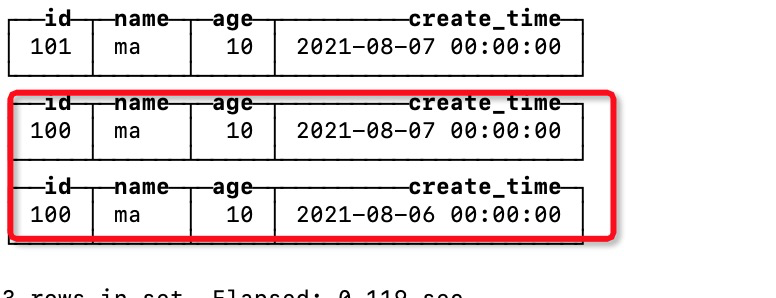
order by 排序字段,必填项,在本例中order by(id,age),那么主键必须是id 或者 id,age中的一个
的

若有收获,就点个赞吧
0 人点赞
