- es6数组扁平化
- 去重方法
- 如何解决数字精度丢失的问题
- this指向
- 函数的三种定义方式和六种调用
- es6之扩展运算符 三个点(…)
- es6箭头函数
- 数据类型检测
- 常用数组操作
- 浅拷贝和深拷贝的区别和实现方式
- promise
- async和await
- undefined和null的区别
- for in和for of的区别
- forEach和map区别是什么
- DOM操作和BOM操作
- 虚拟DOM与真实DOM的区别
- 如何实现图片懒加载
- const定义的数据可以修改吗
- 本地储存localStorage, sessionStorage,cookie
- 闭包
- 浏览器兼容性问题
- JS中继承的几种方式总结以及原型的理解
- 函数的防抖和节流
- keep-alive
- vue组件之间的数据传递
- $route和$router的区别
- ref和$refs的使用
- v-show和v-if的区别
- v-for和v-if一起使用处理方式
- v-model原理
- vue生命周期函数
- $nextTick
- vue-router的next()方法
- vue渲染页面的时候出现闪烁问题的解决方法
- vue-router实现原理
- 路由守卫,编程式导航
- vue编程式的导航跳转传参的方式有哪些
es6数组扁平化
数组的成员有时还是数组,Array.prototype.flat()用于将嵌套的数组“拉平”,变成一维数组。该方法返回一个新数组,对原数据没有影响。
[1,2,[3,4]].flat() //=>输出[1,2,3,4]
原数组的成员里面有一个数组,flat()方法将子数组的成员取出来,添加在原来的位置。
flat()默认只会“拉平”一层,如果想要“拉平”多层的嵌套数组,可以将flat()方法的参数写成一个整数,表示想要拉平的层数,默认为1
[1,2,[3,[4,5]]].flat() //=>[1,2,3,[4,5]][1,2,[3,[4,5]]].flat(2) //=>[1,2,3,4,5]//参数为2,表示要拉平两层的嵌套数组
如果不管有多少层嵌套,都要转成一维数组,可以用Infinity关键字作为参数。
[1, [2, [3]]].flat(Infinity) //=> [1, 2, 3]
如果原数组有空位,flat()方法会跳过空位
[1,2, ,4,5].flat() //=>[1,2,4,5]
flatMap()方法对原数组的每个成员执行一个函数,相当于执行Array.prototype.map(),然后对返回值组成的数组执行flat()方法。该方法返回一个新数组,不改变原数组。
//相当于[[2,4], [3,6],[4,8]].flat()[2,3,4].flatMap((x) => [x, x * 2])//[2,4,3,6,4,8]
去重方法
利用ES6 Set去重
function unique(arr) {return Array.from(new Set(arr))}var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]console.log(unique(arr)arr)//[1, 'true', true, 15, false, undefined, null, NaN, 'NaN', 0, 'a', {}]
利用for嵌套for,然后splice去重
function unique(arr) {for(var i = 0; i < arr.length; i++) {for(var j = 0; j < arr.length; j++) {if(arr[i] == arr[j]) {arr.splice(j, 1);j--;}}}return arr;}var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}];console.log(unique(arr))//[1, "true", 15, false, undefined, NaN, NaN, "NaN", 'a', {……}, {……}]//NaN和{}没有去重,两个null直接消失了
利用indexOf去重
function unique(arr) {if(!Array.isArray(arr)) {console.log('type error')return}var array = [];for(var i = 0; i < arr.length; i++) {if(array.indexOf(arr[i]) === -1) {array.push(arr[i])}}return array}var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {……}, {……}]//NaN、{}没有去重
利用includes
function unique(arr) {if(!Array.isArray(arr)) {console.log('type error')return}var array = [];for(var i = 0; i < arr.length; i++) {if(!array.includes(arr[i])) {array.push(arr[i]);}}return array}var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]console.log(unique(arr))//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {……}, {……}]//{}没有去重
如何解决数字精度丢失的问题
理论上用有限的空间来存储无限的小数是不可能保证精确的,但可以处理一下得到期望的结果
例如:1.4000000000000001这样的数据要展示时,建议使用toPrecision凑整并parseFloat转成数字后再显示
parseFloat(1.4000000000000001.toPrecision(12)) === 1.4 //true
封装成的方法就是:
function strip(num, precision = 12) {return +parseFloat(num.toPrecision(precision))}
最后还可以使用第三方库,如Math.js、BigDecimal.js
this指向
在全局作用域
this指向window,this和window是同一块空间地址;
//直接在html文件中输出this,指向的windowconsole.log(this)//window//下面两个含义是一样的window.alert();this.alert();
给元素的事件绑定的函数中的this
指向了当前被点击的那个元素
<div id="box">点我</div><div id="box1">点我1</div><script>box.onclick = function(){//这里面的this : 是个对象;console.dir(this===box); // 空间地址相同;box.style.color="red";//给文字改变颜色this.style.color="red";//this=100;// this 不能放到等号的左边;}</script>
看函数执行前有没有’.’
如果要是没有,那么函数中的this指向window,如果有’.’,那么点前面是谁,this就指向谁
var obj = {m:1,fn:function(){console.log(this);}}var f = obj.fn;console.log(f==obj.fn);//trueobj.fn();//this==>objf();//this==>window
自执行函数中this永远指向window
(function(){console.log(this);// window})();var obj = {fn:(function(){console.log(this);// windowreturn function(){console.log(this); // window}})()}var f= obj.fn;f();
回调函数中的this一般指向window
setTimeout(function(){console.log(this);//window},1000);
var ary=[1,2,3,4]ary.map(function(){console.log(this);//会输出4个window})
构造函数中的this指向实例
call,apply,bind可以改变this指向
call方法
调用函数的方式,但是它可以改变this指向,经常做继承
function fun(x, y) {console.log(this); //this指向改变,指向objconsole.log(x + y);}var obj = {name: '小明'};//call()可以调用函数fun.call();// call() 可以改变这个函数的this指向 此时这个函数的this 就指向了obj这个对象fun.call(obj,10,20);
apply方法
调用函数的方式,但是它可以改变this指向;经常跟数组有关系
function fun(x, y) {console.log(this); //this指向改变,指向objconsole.log(x + y);}var obj = {name: '小明'};fun()//this指向windowfun.apply(obj,[10,20]) //this指向对象obj,参数使用数组方式传递
//借助数学对象实现数组最大值和最小值;var arr = [1, 10, 20, 15, 5];var max = Math.max.apply(Math, arr);var min = Math.min.apply(Math, arr);console.log(max, min);
bind方法
不会调用函数,但是能改变内部this指向,返回的是原函数改变的this之后产生的新函数,若只想改变this指向,并不想调用函数,就用bind()方法。
function fun(x, y) {console.log(this); //this指向改变,指向objconsole.log(x + y);}var obj = {name: '小明'};var ff = fun.bind(obj,10,20) ; //bind返回的是新函数//调用新函数ff(); //this指向的是对象obj,参数是逗号隔开
//点击按钮,就禁用这个按钮,3秒钟之后开启这个按钮<body><button>我最帅</button><button>我最帅</button><button>我最帅</button><button>我最帅</button><button>我最帅</button><script>var btns = document.querySelectorAll('button');for (var i = 0; i < btns.length; i++) {btns[i].onclick = function() {this.disabled = true;setTimeout(function() {this.disabled = false;}.bind(this), 3000);}}</script>
call,apply,bind的异同点
共同点
不同点
call和apply会调用函数,并且改变函数内部this指向
call和apply传递参数不同,call传递参数使用逗号隔开,apply使用数组传递
bind不会调用函数,可以改变函数内部this指向
函数的三种定义方式和六种调用
函数的定义
函数声明
function 关键字(命名函数) function fn() {}
函数表达式 (匿名函数)
new Function()
var fn = new Function('参数一', '参数二',... '函数体');//Function里面参数都必须是字符串格式,这种方式执行效率低,少用,所有函数都是Function的实例,函数也是对象
函数常见六种方式
//1.普通函数function fn(){console.log('我在努力学习js');}fn();//2.对象的方法var obj = {study: function(){console.log('我在努力学习js');}}obj.study();//3.构造函数function Person(){ };new Person()//4.绑定事件函数,点击按钮就可以调用这个函数btn.onclick = function(){ }//5.定时器函数,每隔2秒调用一次这个函数setInterval(function(){ },2000);//6.立即执行函数(function(){console.log('我在学习js');})();
es6之扩展运算符 三个点(…)
对象的扩展运算符
对象中的扩展运算符(…)用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中
let bar = { a: 1, b: 2 };let baz = { ...bar };//等价于let bar = { a: 1, b: 2 };let baz = Object.assign({}, bar);
Object.assign方法用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target)。
Object.assign方法的第一个参数是目标对象,后面的参数都是源对象。(如果目标对象与源对象有同名属性,或多个源对象有同名属性,则后面的属性会覆盖前面的属性)。
同样,如果用户自定义的属性,放在扩展运算符后面,则扩展运算符内部的同名属性会被覆盖掉。
let bar = {a: 1, b: 2};let baz = {...bar, ...{a:2, b: 4}}; // {a: 2, b: 4}
利用上述特性就可以很方便修改对象的部分属性。在redux中的reducer函数规定必须是一个纯函数,reducer中的state对象要求不能直接修改,可以通过扩展运算符把修改路径的对象都复制一遍,然后产生一个新的对象返回。
扩展运算符对对象实例的拷贝属于一种浅拷贝
数组的扩展运算符
可以将数组转换为参数序列
function add(x, y) {return x + y;}const numbers = [4, 38];add(...numbers) // 42
可以复制数组
如果直接通过下列的方式进行数组复制是不可取的
const arr1 = [1, 2];const arr2 = arr1;arr2[0] = 2;arr1 // [2,2]//用扩展运算符const arr1 = [1, 2];const arr2 = [...arr1];
扩展运算符(…)用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中,这里参数对象是个数组,数组里面的所有对象都是基础数据类型,将所有基础数据类型重新拷贝到新的数组中。
与解构赋值结合起来,用于生成数组
const [first, ...rest] = [1, 2, 3, 4, 5];first // 1rest // [2, 3, 4, 5]
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错
const [...rest, last] = [1, 2, 3, 4, 5];//报错const [first, ...rest, last] = [1, 2, 3, 4, 5];//报错
可以将字符串转为真正的数组
[...'hello']//["h", "e", "l", "l", "o"]
es6箭头函数
基本形式
let func = (num) => num;let func = () => num;let sum = (num1, num2) => num1 + num2;[1, 2, 3].map(x => x * x);
基本特点
this为父作用域的this,不是调用时的this
箭头函数的this永远指向其父作用域,任何方法都改变不了,包括call,apply,bind。
普通函数的this指向调用它的那个对象。
let person = {name:'jike',init:function(){//为body添加一个点击事件,看看这个点击后的this属性有什么不同document.body.onclick = ()=>{alert(this.name);//?? this在浏览器默认是调用时的对象,可变的?}}}person.init();
init是function,以person.init调用,其内部this就是person本身,而onclick回调是箭头函数,其内部的this,就是父作用域的this,就是person,能得到name。
let person = {name:'jike',init:()=>{//为body添加一个点击事件,看看这个点击后的this属性有什么不同document.body.onclick = ()=>{alert(this.name);//?? this在浏览器默认是调用时的对象,可变的?}}}person.init();
init为箭头函数,其内部的this为全局window,onclick的this也就是init函数的this,也是window,得到的this.name就为undefined。
箭头函数不能作为构造函数,不能使用new
//构造函数如下:function Person(p){this.name = p.name;}//如果用箭头函数作为构造函数,则如下var Person = (p) => {this.name = p.name;}
箭头函数没有arguments,caller,callee
本身没有arguments,如果箭头函数在一个function内部,它会将外部函数的arguments拿过来使用。箭头函数中要想接收不定参数,应该使用rest参数…解决。
let B = (b)=>{console.log(arguments);}B(2,92,32,32); // Uncaught ReferenceError: arguments is not definedlet C = (...c) => {console.log(c);}C(3,82,32,11323); // [3, 82, 32, 11323]
通过call和apply调用,不会改变this指向,只会传入参数
let obj2 = {a: 10,b: function(n) {let f = (n) => n + this.a;return f(n);},c: function(n) {let f = (n) => n + this.a;let m = {a: 20};return f.call(m, n)}};console.log(obj2.b(1)); //11console.log(obj2.c(1)); //11
箭头函数没有原型属性
var a = () => {return 1;}function b() {return 2;}console.log(a.prototype);//undefinedconsole.log(b.prototype);//{constructor: f}
箭头函数不能作为Generator函数,不能使用yield关键字
箭头函数返回对象时,要加一个小括号
var func = () => ({foo : 1})//正确var func = () => {foo : 1} //错误
箭头函数在es6 class中声明的方法为实例方法,不是原型方法
//deom1class Super{sayName(){//do some thing here}}//通过Super.prototype可以访问到sayName方法,这种形式定义的方法,都是定义在prototype上var a = new Super()var b = new Super()a.sayName === b.sayName //true//所有实例化之后的对象共享prototypy上的sayName方法//demo2class Super{sayName =()=>{//do some thing here}}//通过Super.prototype访问不到sayName方法,该方法没有定义在prototype上var a = new Super()var b = new Super()a.sayName === b.sayName //false//实例化之后的对象各自拥有自己的sayName方法,比demo1需要更多的内存空间
在class中尽量少用箭头函数声明方法
多重箭头函数就是一个高阶函数,相当于内嵌函数
const add = x => y => y + x;//相当于function add(x) {return function(y) {return y + x;}}
箭头函数常见错误
let a = {foo: 1,bar: () => console.log(this.foo)}a.bar()
bar函数中的this指向父作用域,而a对象没有作用域,因此this不是a,打印结果为undefined
function A() {this.foo = 1}A.prototype.bar = () => console.log(this.foo)let a = new A()a.bar() //undefined
原型上使用箭头函数,this指向是其父作用域,并不是对象a,因此得不到预期结果。
数据类型检测
typeof
返回一个字符串,字符串中包含了对应的数据类型
不能检测null
不能检测对象数据类型(引用数据类型)
instanceof
是检测实例是否属于某个类的方法
只要当前类的原型在当前实例的原型链上,都返回true;(局限性,校验不准)
只要改变了当前实例的原型链,检测结果就不再准确了
不能检测字面量方式创建的基本数据类型值
var num = new Number(1);console.log(num instanceof Number)
constructor(构造器)
原型中天生自带一个属性名
不能检测基本数据类型的null或undefined;(检测这两个报错)
如果原型扩展以及继承都有可能导致原型链指向发生改变,结果不准确
var ary = [];console.log(ary.constructor === Array) // trueconsole.log(ary.constructor === Object) // falsevar obj = {};console.log(obj.constructor === Array);var num = 1;console.log(num.constructor === Number);function A() {}A.prototype = {} //这种的原型扩展会导致原型上的constructor丢失var a = new A;a.constructor === A//如果原型扩展以及继承都有可能导致原型链指向发生改变,结果不准确console.log(a.constructor === A);
Object.prototype.toString.call()
通过call改变了toString中的this,call找到自己属性上的方法,检测的是谁,call就指向谁
常用数组操作
concat()
用于连接两个或多个数组,不会改变现有的数组,仅会返回被连接数组的一个副本
var arr1 = [1,2,3];var arr2 = [4,5];var arr3 = arr1.concat(arr2);console.log(arr1); //[1,2,3]console.log(arr3); //[1,2,3,4,5]
join()
用于把数组中的所有元素放入一个字符串,元素是通过指定的分隔符进行分割的,默认使用’,’分割,不改变原数组
var arr = [2,3,4];console.log(arr.join()); //2,3,4console.log(arr); //[2,3,4]
push()
可向数组的末尾添加一个或多个元素,并返回新的长度。末尾添加,返回的是长度,会改变原数组。
var a = [2,3,4];var b = a.push(5);console.log(a); //[2,3,4,5]console.log(b); //4//push方法可以一次添加多个元素push(data1,data2,……)
pop()
用于删除并返回数组的最后一个元素,返回最后一个元素,会改变原数组
var arr = [2,3,4];console.log(arr.pop()); //4console.log(arr); //[2,3]
shift()
用于把数组的第一个元素从其中删除,并返回第一个元素的值。返回第一个元素,改变原数组。
var arr = [2,3,4];console.log(arr.shift()); //2console.log(arr); //[3,4]
unshift()
可向数组的开头添加一个或更多元素,并返回新的长度。返回新长度,改变原数组。
var arr = [2,3,4,5];console.log(arr.unshift(3,6)); //6console.log(arr); //[3,6,2,3,4,5]//tip:该方法可以不传参数,不传参数就是不增加元素
slice()
返回一个新的数组,包含从start到end(不包括该元素)的arrayObject中的元素。返回选定的元素,该方法不会修改原数组。
var arr = [2,3,4,5];console.log(arr.slice(1,3)); //[3,4]console.log(arr) //[2,3,4,5]
splice()
可删除从index处开始的零个或多个元素,并且用参数列表中声明的一个或多个值来替换那些被删除的元素。如果从arrayObject中删除了元素,则返回的是含有被删除的元素的数组。splice()方法会直接对数组进行修改。
var a = [5,6,7,8];console.log(a.splice(1,0,9)); //[]console.log(a); //[5,9,6,7,8]var b = [5,6,7,8];console.log(b.splice(1,2,3)); //[6,7]console.log(b); //[5,3,8]
subString()和substr()
相同点:如果只是写一个参数,两者的作用都一样:都是截取字符串从当前下标以后直到字符串最后的字符串片段。substr(startIndex);subString(startIndex);
var str = '123456789';console.log(str.substr(2)); // "3456789"console.log(str.subString(2)); // "3456789"
不同点:第二个参数
substr(startIndex, length):第二个参数是截取字符串的长度(从起始点截取某个长度的字符串);
subString(startIndex, endIndex):第二个参数是截取字符串最终的下标(截取2个位置之间的字符串,含头不含尾)
console.log("123456789".substr(2,5)) // 34567console.log("123456789".substring(2,5)) // 345
sort排序
按照unicode code位置排序,默认升序
var fruit = ['cherries', 'apples', 'bananas'];fruit.sort(); // ['apples', 'bananas', 'cherries']var scores = [1, 10, 21, 2];scores.sort(); // [1, 10, 2, 21]
reverse()
用于颠倒数组中元素的顺序。返回的是颠倒后的数组,会改变原数组。
var arr = [2,3,4];console.log(arr.reverse()); //[4,3,2]console.log(arr); // [4,3,2]
indexOf和lastindexOf
都接受两个参数:查找的值、查找起始位置不存在,返回-1;存在,返回位置。
indexOf是从前往后查,lastindexof是从后往前查
//indexOfvar a = [2, 9, 9];a.indexOf(2); //0a.indexOf(7); //-1if(a.indexOf(7) === -1) {//不存在}//lastindexofvar numbers = [2, 5, 9, 2];numbers.lastIndexOf(2); // 3numbers.lastIndexOf(7); // -1numbers.lastIndexOf(2, 3); // 3numbers.lastIndexOf(2, 2); // 0numbers.lastIndexOf(2, -2); //0numbers.lastIndexOf(2, -1); // 3
every
对数组的每一项都运行给定的函数,每一项都返回true,则返回true
function isBigEnough(element, index, array){return element < 10:}[2,5,8,3,4].every(isBigEnough);//true
some
对数组的每一项都运行给定的函数,任意一项都返回true,则返回true
function compare(element, index, array){return element > 10;}[2,5,8,1,4].some(compare); // false[12,5,8,1,4].some(compare); // true
filter
对数组的每一项都运行给定的函数,返回结果为true的项组成的数组
var words = ["spray", "limit", "elite", "exuberant", "destruction", "present", "happy"];var longWords = words.filter(function(word){return word.length > 6;})//Filtered array longWords is ["exuberant", "destruction", "present"]
map
对数组的每一项都运行给定的函数,返回每次函数调用的结果组成一个新数组
var numbers = [1, 5, 10, 15];var doubles = numbers.map(function(x){return x * 2;})// doubles is now [2, 10, 20, 30];// numbers is still [1, 5, 10, 15]
forEach数组遍历
const items = ['item1', 'item2', 'item3'];const copy = [];items.forEach(function(item){copy.push(item);})
ES6新增操作数组方法
find()
传入一个回调函数,找到数组中符合当前搜索规则的第一个元素,返回它,并且终止搜索
const arr = [1, "2", 3, 3, "2"]console.log(arr.find(n => typeof n === "number")) // 1
findIndex()
传入一个回调函数,找到数组中符合当前搜索规则的第一个元素,返回它的下标,终止搜索
const arr = [1, "2", 3, 3, "2"];console.log(arr.findIndex(n => typeof n === "number"); // 0
fill()
用新元素替换掉数组内的元素,可以指定替换下标范围
arr.fill(value, start, end)
copyWithin()
选择数组的某个下标,从该位置开始复制数组元素,默认从0开始复制。也可以指定要复制的元素范围
//arr.copyWithin(target, start, end);const arr = [1, 2, 3, 4, 5]console.log(arr.copyWithin(3))//[1,2,3,1,2]从下标为3的元素开始,复制数组,所以4,5被替换成1,2const arr1 = [1, 2, 3, 4, 5]console.log(arr1.copyWithin(3,1))//[1,2,3,2,3]从下标为3的元素开始,复制数组,指定复制的第一个元素下标为1,所以4,5被替换成2,3const arr2 = [1, 2, 3, 4, 5]console.log(arr2.copyWithin(3, 1, 2))//[1,2,3,2,5]从下标为3的元素开始,复制数组,指定复制的第一个元素下标为1,结束位置为2,所以4被替换成2
from
将类似数组的对象(array-like object)和可遍历(iterable)的对象转为真正的数组
const bar = ["a", "b", "c"];Array.from(bar); // ["a", "b", "c"]Array.from('foo'); //["f", "o", "o"]
of
用于将一组值,转换为数组。这个方法的主要目的, 是弥补数组构造函数Array()的不足。因为参数的个数不同会导致Array()的行为有差异
Array() //[]Array(3) // [, , ,]Array(3, 11, 8) //[3, 11, 8];Array.of(7) // [7]Array.of(1, 2, 3) //[1, 2, 3]Array(7) //[, , , , , , ,]Array(1, 2, 3) //[1, 2, 3]
entries()
返回迭代器:返回键值对
//数组const arr = ['a', 'b', 'c'];for(let v of arr.entries()) {console.log(v)}//[0, 'a'] [1, 'b'] [2, 'c']//setconst arr = new Set(['a', 'b', 'c']);for(let v of arr.entries()) {console.log(v)}//[a, 'a'] [b, 'b'] [c, 'c']//Mapconst arr = new Map();arr.set('a', 'a');arr.set('b', 'b');for(let v of arr.entries()) {console.log(v)}//[a, 'a'] [b, 'b']
values()
返回迭代器:返回键值对的value
//数组const arr = ['a', 'b', 'c'];for(let v of arr.values()) {console.log(v)}//'a', 'b', 'c'//setconst arr = new Set(['a', 'b', 'c']);for(let v of arr.values()) {console.log(v)}//'a', 'b', 'c'//Mapconst arr = new Map();arr.set('a', 'a');arr.set('b', 'b');for(let v of arr.entries()) {console.log(v)}//[a, 'a'] [b, 'b']
keys()
返回迭代器:返回键值对的key
//数组const arr = ['a', 'b', 'c'];for(let v of arr.keys()) {console.log(v)}//0,1,2//setconst arr = new Set(['a', 'b', 'c']);for(let v of arr.keys()) {console.log(v)}//'a', 'b', 'c'//Mapconst arr = new Map();arr.set('a', 'a');arr.set('b', 'b');for(let v of arr.entries()) {console.log(v)}// 'a' 'b'
includes
判断数组中是否存在该元素,参数:查找的值、起始位置、可以替换ES5的indexOf判断方式。indexOf判断元素是否为NaN,会判断错误。
var a = [1, 2, 3];a.includes(2); // truea.includes(4); //false
数组去重
let arr = [1, 1, 2, 2, 3, 4, 3, 4, 5, 5];//indexOflet newArr = [];for(let i = 0; i < arr.length; i++) {if(newArr indexOf(arr[i]) === -1) {newArr.push(arr[i])}}console.log(newArr); //[1, 2, 3, 4, 5]//ES6的Setlet newArr = [...new Set(arr)];console.log(newArr);//filter()函数let newArr = arr.filter(function(ele, index, self) {return self.indexOf(ele) === index;})console.log(newArr); //[1, 2, 3, 4, 5]//ES6的includeslet newArr = [];for(let n of arr) {if(!newArr.includes(n)) {newArr.push(n)}}console.log(newArr); // [1, 2, 3, 4, 5]//Array.from方法可以将Set结构转为数组function dedupe(array) {return Array.from(new Set(array))}console.log(dedupe(arr)); //[1, 2, 3, 4, 5]//jQuery的inArraylet newArr = [];for(let i = 0; i < arr.length; i++) {if($.inArray(arr[i].newArr) == -1) {newArr.push(arr[i])}}console.log(dedupe(arr)); //[1, 2, 3, 4, 5]
浅拷贝和深拷贝的区别和实现方式
基本数据类型
名字和值都会储存在栈内存
var a = 1;b = a;//栈内存会开辟一个新的内存空间,此时b和a都是相互独立的b = 2;console.log(a); // 1
当然,这也算不上深拷贝,因为深拷贝本身只针对较为复杂的object类型数据
引用数据类型
名字存在栈内存,值存在堆内存中,但是栈内存会提供一个引用的地址指向堆内存中的值
比如浅拷贝:
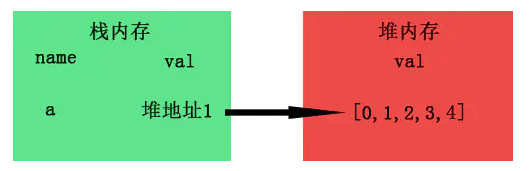
当b=a进行拷贝时,其实想复制的是a的引用地址,而并非堆里面的值。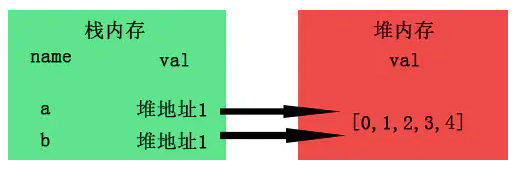
而当我们a[0]=1时进行数组修改时,由于a与b指向的是同一个地址,所以自然b也受了影响,这就是所谓的浅拷贝了。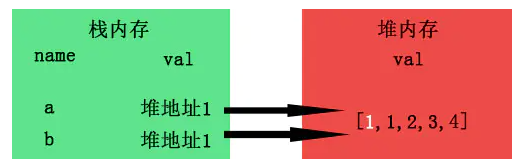
那,要是在堆内存中也开辟一个新的内存专门为b存放值,就像基本类型那样,岂不是达到深拷贝的效果了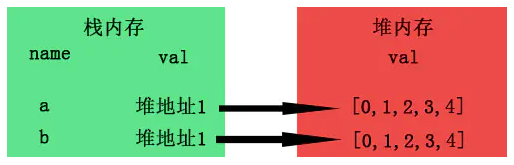
实现浅拷贝的方法
for…in只循环第一层
// 只复制第一层的浅拷贝function simpleCopy(obj1) {var obj2 = Array.isArray(obj1) ? [] : {};//for in 之前需要判断一下是否是引用类型,如果是数组和对象,需要在进行自调用for(let i in obj1) {obj2[i] = obj1[i];}return obj2;}var obj1 = {a: 1,b: 2,c: {d: 3}}var obj2 = simpleCopy(obj1);obj2.a = 3;obj2.c.d = 4;alert(obj1.a); // 1alert(obj2.a); // 3alert(obj1.c.d); // 4alert(obj2.c.d); // 4
object.assign方法
var obj = {a: 1,b: 2}var obj1 = Object.assign(obj);obj1.a = 3;console.log(obj.a) // 3
直接用=赋值
let a = [0, 1, 2, 3, 4];b = a;console.log(a === b); // falsea[0] = 1;console.log(a, b); // [1, 1, 2, 3, 4] [1, 1, 2, 3, 4]
实现深拷贝的方法
采用递归去拷贝所有层级属性
function deepClone(obj) {let objClone = Array.isArray(obj) ? [] : {};if(obj && typeof obj === "object") {for(key in obj) {if(obj.hasOwnProperty(key)) {//判断obj子元素是否为对象,如果是,递归复制if(obj[key] && typeof obj[key] === "object") {objClone[key] = deepClone(obj[key]);} else {//如果不是,简单复制objClone[key] = obj[key]}}}}return objClone;}let a = [1, 2, 3, 4];b = deepClone(a);a[0] = 2;console.log(a, b)
通过JSON对象来实现
function deepClone2(obj) {var _obj = JSON.stringify(obj),objClone = JSON.parse(_obj);return objClone;}
缺点: 无法实现对对象中方法的深拷贝,会显示为undefined
通过jQuery的extend方法实现
var array = [1, 2, 3, 4];var newArray = $.extend(true, [], array); //true为深拷贝, false为浅拷贝
lodash函数库实现深拷贝
let result = _.cloneDeep(test)
reflect
//代理法function deepClone(obj) {if(!isObject(obj)) {throw new Error('obj不是一个对象')}let isArray = Array.isArray(obj)let cloneObj = isArray ? [...obj] : { ...obj }Reflect.ownKeys(cloneObj).forEach(key => {cloneObj[key] = isObject(obj[key]) ? deepClone(obj[key]) : obj[key]})return cloneObj}
手动实现深拷贝
let obj1 = {a: 1,b: 2}let obj2 = {a: obj1.a,b: obj1.b}obj2.a = 3;alert(obj1.a); // 1alert(obj2.a); // 3
object.assign
var obj = {a: 1,b: 2}var obj1 = object.assign({}, obj); // obj赋值给一个空{}obj1.a = 3;console.log(obj.a); // 1
用slice实现对数组的深拷贝
// 当数组里面的值是基本数据类型,比如string、number、Boolean属于深拷贝// 当数组里面的值是引用数据类型,比如Object、Array时,属于浅拷贝var arr1 = ["1", "2", "3"];var arr2 = arr1.slice(0);arr2[1] = "9";console.log("数组的原始值:" + arr1);console.log("数组的新值:" + arr2);
用concat实现对数组的深拷贝
// 当数组里面的值是基本数据类型,比如string、number、Boolean属于深拷贝var arr1 = ["1", "2", "3"];var arr2 = arr1.concat();arr2[1] = "9";console.log("数组的原始值:" + arr1);console.log("数组的新值:" + arr2);// 当数组里面的值是引用数据类型,比如ObjectdArray时,属于浅拷贝var arr1 = [{a:1},{b:2},{c:3}];var arr2 = arr1.concat();arr2[0].a = "9";console.log("数组的原始值:" + arr1[0].a); //数组的原始值: 9console.log("数组的新值:" + arr2[0].a); //数组的原始值: 9
var newObj = Object.create(oldObj)
function deepClone(initalObj, finalObj) {var obj = finalObj || {};for(var i in initalObj) {var prop = initalObj[i];if(prop === obj) {continue;}if(typeof prop === 'object') {obj[i] = (prop.constructor === Array) ? [] : Object.create(prop);} else {obj[i] = prop;}}return obj;}
扩展运算符
// 当value是基本数据类型,比如string、number、Boolean时,是可以使用拓展运算符进行深拷贝// 当value是引用数据类型,比如Object、Array,引用类型进行深拷贝也只是拷贝了引用地址,所以属于浅拷贝var car = {brand: "BMW", price: "380000", length: "5米"}var car1 = { ...car, price: "500000" }console.log(car1); // {brand: "BMW", price: "380000", length: "5米"}console.log(car); //{brand: "BMW", price: "380000", length: "5米"}
promise
异步编程的一种解决方案,比传统的解决方案(回调函数和事件)更合理和强大
promise对象特点
对象的状态不受外界影响
promise对象有三种状态:pending、fulfilled、rejected。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是promise这个名字的由来,其他手段无法改变状态。
一旦状态改变就不会再变,任何时候都能得到这个结果
promise对象的状态改变只有两种状态:从pending变成fulfilled,从pending变成rejected。只要这两种情况发生,状态就凝固不会再变了,这时就称为resolved。如果改变已经发生,再对promise对象添加回调函数,也会立即得到这个结果。这与事件完全不同。事件的特点是,如果你错过了它,再去监听是得不到结果的。
有了promise对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调。此外,promise对象提供统一的接口,使得控制异步操作更加容易。
缺点
无法取消promise,一旦新建就会立即执行,无法中途取消。其次,如果不设置回调函数,promise内部抛出的错误,不会反应到外部。第三,当处于pending状态时,无法得知得知目前进展到哪一个阶段。
基本用法
promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由JS引擎提供
resolve函数的作用是,将promise对象的状态从pending变为fulfilled,在异步操作成功时调用,并将异步操作的结果,作为参数传递出去。
reject函数的作用是,将promise对象的状态从pending变为rejected,在异步操作失败时调用,并将异步操作报出的错误作为参数传递出去。
promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。promise.then(function(val) {}, function(err) {})
let promise = new Promise(function(resolve, reject) {console.log('Promise');resolve();})promise.then(function() {console.log('resolved');})console.log('Hi');// Promise// Hi!// resolved// Promise新建后立即执行,所以首先输出的是Promise。然后,then方法指定的回调函数,将在当前脚本所有同步任务执行完才会执行,所以resolved最后输出
如果调用resolve函数和reject函数时带有参数,那么它们的参数会被传递给回调函数。reject函数的参数通常是Error对象的实例,表示抛出的错误;resolve函数的参数除了正常的值以外,还可能是另一个Promise实例,比如像下面这样
const p1 = new Promise(function(resolve, reject) {//……})const p2 = new Promise(function(resolve, reject) {//……resolve(p1j)})//p2的resolve方法将p1作为参数,即一个异步操作的结果是返回另一个异步操作//p1的状态就会传递给p2,也就是说,p2自己的状态无效,由p1的状态决定p2的状态,p2后面的then语句都变成针对p1的。如果p1自己的状态是pending,那么p2的回调函数就会等待p1的状态改变;如果p1的状态已经是resolved或者rejected,那么p2的回调函数将会立刻执行。
注意:调用resolve或reject并不会终结Promise的参数函数的执行。写在resolve或reject之后的语句是会执行的。但是一般来说,调用resolve或reject以后,Promise的使命就完成了,后继操作应该放到then方法里面,而不应该直接写在resolve或reject的后面。所以,最好在它们前面加上return语句,这样就不会有意外。
new Promise((resolve, reject) => {resolve(1);console.log(2);}).then(r => {console.log(r);})// 2// 1new Promise((resolve, reject) => {return resolve(1);//后面的语句不会执行console.log(2);})
promise的API
promise.prototype.then
如果then方法返回的是一个新的promise实例,那么可以采用链式写法,then方法后再调用一个then方法。
promise.prototype.catch
catch方法是.then(null, rejection)或.then(undefined, rejection)的别名,用于指定发生错误时的回调函数。
getJSON('/posts.json').then(function(posts) {//...}).catch(function(error) {//处理getJSON和then方法中回调函数运行时发生的错误console.log('发生错误', error);})
一般来说,不要在then()方法里面定义reject状态的回调函数(即then的第二个参数),总是使用catch方法。
如果没有使用catch()方法指定错误处理的回调函数,Promise对象抛出的错误不会传递到外层代码,即不会有任何反应。Promise内部的错误不会影响到Promise外部的代码,通俗的说法就是”Promise会吃掉错误”。
promise.prototype.finally
finally方法用于指定不管promise对象最后状态如何,都会执行的操作。finally的回调函数不接受任何参数,里面的操作应该是与状态无关的。
promise.all()
promise.all()用于将多个promise实例,包装成一个新的promise实例。const p = Promise.all([p1, p2, p3])
promise的应用
加载图片
将图片的加载写成一个promise,一旦加载完成,promise的状态就发生变化。
generator函数与promise的结合
使用generator函数管理流程,遇到异步操作的时候,通常返回一个promise对象。
async和await
什么是async/await
async/await是写异步代码的新方式,以前的方法有回调函数和Promise。
async/await是基于Promise实现的,它不能用于普通的回调函数。
async/await与Promise一样,是非阻塞的。
async/await使得异步代码看起来像是同步代码,这正是它的魔力所在。
async/await语法
使用Promise
const makeRequest = () =>getJSON().then(data => {console.log(data);return "done"})makeRequest()
使用async
const makeRequest = async() => {//await getJSON()表示console.log会等到getJSON的promise成功resolve之后再执行console.log(await getJSON);return "done"}makeRequest();
区别
函数前面多了一个async关键字,await关键字只能用在async定义的函数内。async函数会隐式地返回一个promise,该promise的resolve值就是函数return的值。
不能在最外层代码中使用await,因为不在async函数内。
//不能在最外层代码中使用awaitawait makeRequest()//这是会出事情的makeRequest().then((result) => {//代码})
为什么async/await更好
代码简洁
使用async函数可以让代码简洁很多,不需要像Promise一样需要些then,不需要写匿名函数处理Promise的resolve值,也不需要定义多余的data变量,还避免了嵌套代码。
错误处理
async和await让try/catch可以同时处理同步和异步错误
//promiseconst makeRequest = () => {try {getJSON().then(result => {//JSON.parse可能会出错const data = JSON.parse(result);console.log(data)})//取消注释,处理异步代码的错误//.catch((err) => {//console.log(err)//})} catch(err) {console.log(err)}}//async/awaitconst makeRequest = async () => {try {const data = JSON.parse(result);console.log(data)} catch(err) {console.log(err)}}
条件语句
//promiseconst makeRequest = () => {return getJSON().then(data => {if(data.needsAnotherRequest) {return makeAnotherRequest(data).then(moreData => {console.log(moreData);return moreData})} else {console.log(data);return data}})}//async/awaitconst makeRequest = async() => {const data = await getJSON()if (data.needsAnotherRequest) {const moreData = await makeAnotherRequest(data);console.log(moreData);return moreData} else {console.log(data);return data}}
undefined和null的区别
undefined不是关键字,null是关键字
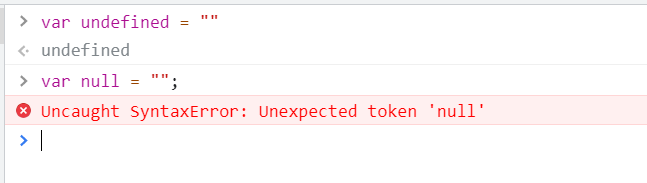
undefined和null被转换为布尔值的时候,两者都为false

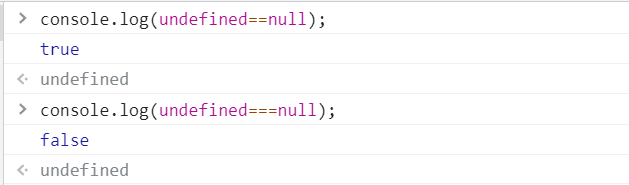
undefined在和null进行==比较时两者相等,全等于比较时两者不等
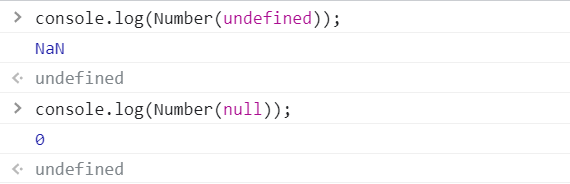
使用Number()对undefined和null进行类型转换
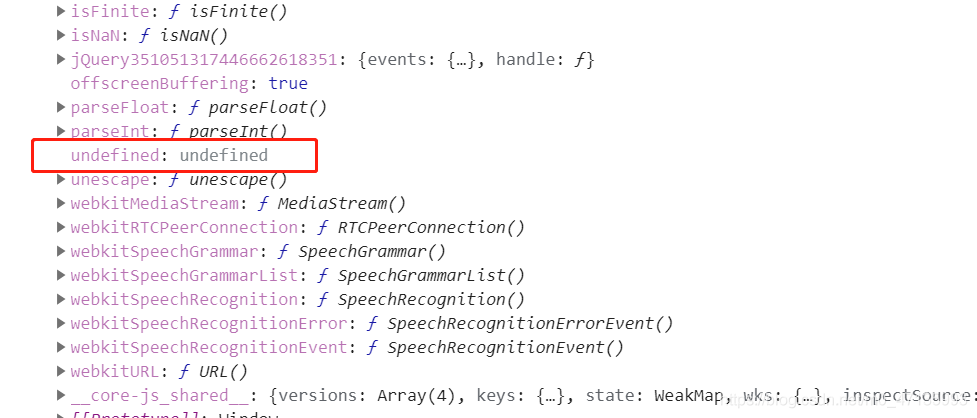
undefined本质上是window的一个属性,而null是一个对象

undefined和null的用途
null表示没有对象,即不应该有值,经常用作函数的参数,或作为原型链的重点。
undefined表示缺少值,即应该有值,但是还没有赋予(变量提升时默认会赋值undefined,函数参数未提供默认为undefined,函数的返回值默认为undefined)
for in和for of的区别
循环数组
for in和for of都可以循环数组,for in输出的是数组的index下标,而for of输出的是数组的每一项的值。
const arr = [1, 2, 3, 4]//for infor(const key in arr) {console.log(key)//输出0,1,2,3}//for offor(const key of arr) {console.log(key) //输出1,2,3,4}
循环对象
for in可以遍历对象,for of不能遍历对象,只能遍历带有iterator接口的,例如Set,Map,String,Array
const object = { name: 'lx', age: 23 }//for infor(const key in object) {console.log(key)//输出name,ageconsole.log(object[key]) //输出lx,23}//for offor(const key of object) {console.log(key) //报错uncaught typeError: object is not iterable}
数组对象
const list = [{ name: 'lx' }, {age: 23}];for(const val of list) {console.log(val); //输出{ name: 'lx' }, {age: 23}for(const key in val) {console.log(val[key]) //输出 lx, 23}}
for in适合遍历对象,for of适合遍历数组。
for in遍历的是数组的索引,对象的属性,以及原型链上的属性
forEach和map区别是什么
forEach()针对每一个元素执行提供的函数
map()创建一个新的数组,其中每个元素由调用数组的每一个元素执行提供的函数得来
forEach()可以做到的东西,map()也同样可以。反过来也是如此。
map()会分配内存空间存储新数组并返回,forEach()不会返回数据。
forEach()允许callback更改原始数组的元素。map()返回新的数组。
DOM操作和BOM操作
DOM操作和BOM操作
DOM操作
BOM操作
DOM操作之获取标签对象
document.querySelector('条件');//获取符合条件的第一个标签对象//执行结果是 一个独立的标签对象//可以直接操作这个独立的标签对象//如果没有符合条件的标签对象 结果是nulldocument.querySelectorAll('条件');//获取符合条件的所有标签对象//执行结果是一个 伪数组//伪数组的单元 存储的具体数据 是 一个独立的标签对象//伪数组不能直接操作//可以通过[]语法,获取一个独立的标签对象 再操作//还可以通过循环语法 循环遍历 操作所有的标签对象//获取的伪数组 可以使用 forEach循环遍历//如果没有符合条件的标签 结果是length为0的空伪数组//条件可以写所有html和css支持的语法形式//('标签名称')//('#id属性值')//('.class属性值')//('[属性="属性值"]')//('ul>li')//('ul li')//('ul li:nth-child(1)')//('div + p')//('div ~ p')总结:JavaScript对于标签对象的操作 一定是 对独立的标签对象的操作不能直接对标签对象 伪数组 进行操作补充说明:所谓的伪数组支持[]语法和length属性可以执行的函数方法 和 数组不同
BOM操作_三大弹窗
window.alert() //警告框
window.prompt() //输入框
window.confirm() //确认框
点击确定返回值是true
点击取消返回值是false
BOM操作_获取浏览器相关数据
浏览器上卷 左移的距离
//有文档类型声明document.documentElement.scrollTopdocument.documentElement.scrollLeft//没有文档类型声明document.body.scrollTopdocument.body.scrollLeft
浏览器视窗窗口宽度高度
//包含滚动条window.innerWidthwindow.innerHeight//不包含滚动条//有文档类型说明document.documentElement.clientWidthdocument.documentElement.clientHeight//没有文档类型说明document.body.clientWidthdocument.body.clientHeight
总结兼容语法:
一种情况有值 一种情况无值
使用逻辑或做逻辑赋值
一种情况有 这个方法 一种情况没有这个方法
使用if判断 做兼容
DOM操作常见事件
//鼠标事件click //左键单击dblclick //左键双击contextmenu //右键单击mousedown //鼠标按键按下mouseup //鼠标按键抬起mousemove //鼠标按键移动mouseover //鼠标移入mouseout //鼠标移出mouseenter //鼠标移入mouseleave //鼠标移出//键盘事件keydown //按键按下keyup //按键抬起keypress //类似按键按下//表单事件focus //获取焦点事件blur //失去焦点事件change //失去焦点并且数据改变事件input //输入事件submit //提交事件//触摸事件//只有移动端设备支持事件//手机 pad...touchstart //触摸开始touchend //触摸结束touchmove //触摸移动//特殊事件transitionstart //过渡开始transitionend //过渡结束animationstart //动画开始animationend //动画结束
虚拟DOM与真实DOM的区别
虚拟DOM不会进行排版与重绘操作,虚拟DOM就是把真实DOM转换为JavaScript代码
虚拟DOM进行频繁修改,然后一次性比较并修改真实DOM中需要改的部分,最后并在真实DOM中进行排版与重绘,减少过多DOM节点排版与重绘损耗
真实DOM频繁排版与重绘的效率是相当低的
虚拟DOM有效降低大面积(真实DOM节点)的重绘与排版,因为最终与真实DOM比较差异,可以只渲染局部
使用虚拟DOM的损耗计算:总损耗 = 虚拟DOM增删改 + (与Diff算法效率有关)真实DOM差异增删改 + (较少的节点)排版与重绘
直接使用真实DOM的损耗计算:总损耗 = 真实DOM完全增删改 + (可能较多的节点)排版与重绘
总之,一切为了减弱频繁的大面积重绘引发的性能问题,不同框架不一定需要虚拟DOM,关键看框架是否频繁会引发大面积的DOM操作
如何实现图片懒加载
懒加载
将图片src先赋值为一张默认图片,当用户滚动滚动条到可视区域图片的时候,再去加载后续真正的图片
如果用户只对第一张图片感兴趣,那剩余的图片请求就可以节省了
为什么要引入懒加载
懒加载是前端优化是一种有效方式,极大的提升用户体验。
懒加载实现的原理
先将img标签中的src链接设置为空,将真正的图片链接放在自定义属性(data-src),当js监听到图片元素进入到可视窗口的时候,将自定义属性中的地址存储到src中,达到懒加载的效果。
懒加载中设计的属性
document.documentElement.clientHeight; //表达浏览器可见区域高度document.body.clientHeight //是整个页面内容的高度,而非浏览器可见区域的高度document.documentElement.scrollTop //滚动条 已滚动的高度chrome中document.body.scrollTop //滚动条 滚动的高度//那么要得到滚动条的高度:var scrollTop = document.body.scrollTop || document.documentElement.scrollTop//这两个值总会有一个恒为0,所以不用担心会对真正的scrollTop造成影响。offsetTop、offsetLeftobj.offsetTop //指obj距离上方或上层控件的位置,整型,单位像素obj.offsetLeft //指obj距离左方或上层控件的位置,整型,单位像素obj.offsetWidth //指obj控件自身的宽度,整型,单位像素obj.offsetHeight //指obj控件自身的高度,整型,单位像素//offsetParent不同于parentNode,offsetParent返回的是在结构层次中与这个元素最近的position为absolute\relative\static的元素或者body
const定义的数据可以修改吗
const定义的数据是一个简单数据类型的时候,是不能修改的,但如果是一个复杂数据类型是可以修改的,因为对于数据的存放是有栈、堆之说的,当存简单数据类型的时候,是放在栈中
而对于复杂数据类型,是将它的地址放在栈中,真正的数据放在堆中,当数据变化的时候并不会去修改地址,所以用const可以修改对象中的值
本地储存localStorage, sessionStorage,cookie
本地存储:
把一些信息存储到客户端本地(本地目的有很多,其中有一个就是实现多页面之间的信息共享)
| 特性 | cookie | localStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在header中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,cookie已经不建议用于存储。如果没有大量数据存储需求的话,可以使用localStorage和sessionStorage。对于不怎么改变的数据尽量使用localStorage存储,否则可以用sessionStorage存储。
对于cookie,还需要注意安全性。
用于本地存储的地方
页面之间信息的通信
A存储信息,B页面中可以获取
本地存储都是存储到当前浏览器指定的地方=>在谷歌浏览器中存储的信息,在IE浏览器中虎丘不到本地存储信息无法跨浏览器进行传输
存储的信息是按照域来管理的=>访问京东网站,把信息都存储到了jd.com,其他域的网站中是无法直接获取这些信息的本地存储不能直接跨域访问
做一些性能优化
可减轻服务器压力
对于不经常更新的数据可以把存储周期设置的长一些,有助于页面第二次加载的时候,渲染的速度
localStorage VS cookie
[cookie]
兼容所有的浏览器
有存储的大小限制,一般一个源(一个域下)只能存储4KB内容
cookie有过期时间(当然自己可以手动设置这个时间)
杀毒软件或者浏览器的垃圾清理都可能会把cookie信息强制清除掉
在隐私或者无痕浏览模式下,是不记录cookie的
cookie不是严格的本地存储,因为要和服务器之间来回传输
[localStorage]
不兼容IE8及以下
也有存储的大小限制,一个源下最多只能存储5MB左右
本地永久存储,只有不手动删除,永远存储在本地(但是可以基于API,removeItem/clear手动清除一些自己想要删除的信息)
杀毒软件或者浏览器的垃圾清理暂时不会清除localStorage(新版本谷歌浏览器会清除localStorage等信息)
在隐私或者无痕浏览模式下,是记录localStorage的
localStorage和服务器没有半毛钱关系
//真实项目中使用本地存储来完成一些需求的情况不是很多,一般都是基于服务器的session或者数据库存储完成的(服务器的session和本地的cookie是有关联的),如果不考虑兼容,就想基于本地存储来完成一些事情。那么一般都是用localStorage的(尤其是移动端开发)localStorage.setItem([key],[value]): //[value]必须是字符串格式的,即使写的不是字符串,也会默认转换为字符串localStorage.getItem([key])://通过属性名获取存储的信息localStorage.removeItem([key])://删除指定的存储信息localStorage.clear(): //清除当前域下存储的所有信息localStorage.key(0): //基于索引获取指定的key名document.cookie = ''; //=>设置cookie
session和cookie的关联
session是服务器存储,cookie是客户端存储
在服务器端建立session之后,服务器和当前客户端之间会建立一个唯一的标识(sessionID/sid),而本次存储的session信息都存放到对应的sid下(目的是为了区分不同客户端都在服务器上建立session信息,后期查找的时候,可以找到自己当初建立的)
当服务器端把一些成功或者失败的结果返回给客户端的时候,在响应头信息中会增加set-cookie(客户端的cookie)这样的字段,把connect.sid存储到客户端的cookie信息中
当客户端在向服务器发送任何请求的时候,在请求头中,都会把cookie信息带上,传送给服务器(包含了之前存储的connect.sid信息)
闭包
解释
由于在JS中,变量的作用域属于函数作用域,在函数执行后作用域就会被清理、内存也随之被收回,但是由于闭包是建立在一个函数内部的子函数,由于其可访问上级作用域的原因,即使上级函数执行完,作用域也不会随之销毁,这时的子函数也就是闭包,便拥有了访问上级作用域中的变量的权限,即使上级函数执行完后,作用域内的值也不会被销毁。
解决
由于闭包可以缓存上级作用域,那么就使得函数外部打破了”函数作用域”的束缚,可以访问函数内部的变量
以平时使用的Ajax成功回调为例,这里其实就是个闭包,由于上述的特性
回调就拥有了整个上级作用域的访问和操作能力,提高了极大的便利。
用处
一个是可以读取函数内部的变量
另一个就是让这些变量的值始终保存在内存中
应用场景
Ajax请求的成功回调
事件绑定的回调方法
setTimeout的延时回调
一个函数内部返回另一个匿名函数简而言之,无论使用何种方式对函数类型的值进行传递,当函数在别处被调用时,都有闭包的身影
注意事项
代码难以维护:闭包内部是可以访问上级作用域,而如果闭包又是异步执行的话,一定要清楚上级作用域都发生了什么,而这样就需要对代码的运行逻辑和JS运行机制相当了解才能弄明白究竟发生了什么
由于闭包会使得函数中的变量都保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能会导致内存泄漏。解决方法:在退出函数之前,将不使用的局部变量全部删除。
内存泄漏:程序的运行需要内存。对于持续运行的服务进程,必须及时释放不再用到的内存,否则占用越来越高,轻则影响系统性能,重则导致进程崩溃。不再用到的内存,没有及时释放,就叫做内存泄漏。
特性
函数内部嵌套函数
函数内部可以引用外部的变量
参数和变量不会被垃圾回收机制回收
this指向
指向是window
浏览器兼容性问题
| 浏览器 | 内核 |
|---|---|
| Chrome | blink(webkit的分支内核) |
| Safari | webkit |
| Firefox | gecko |
| Opera | Blink(此前使用presto内核) |
| IE | Trident(俗称IE内核) |
| 360浏览器 | IE和Chrome双内核 |
| QQ浏览器 | trident(兼容模式) + webkit(高速模式) |
| 搜狗浏览器 | trident(兼容模式) + webkit(高速模式) |
| 百度浏览器 | IE内核 |
常见浏览器兼容性问题和解决办法
- HTML兼容
- CSS兼容
- JavaScript兼容
对于HTML兼容,这是由于低版本浏览器不能识别一些高版本浏览器使用的标签,从而导致不能解析,比如HTML5新增的标签,这类兼容性问题比较容易处理。
CSS兼容
问题一:
不同浏览器的标签默认的外补丁(margin)和内补丁(padding)不同
标签在不在样式的情况下外补丁(margin)和内补丁(padding)存在差异
解决方法:在css里添加
* {margin: 0;padding: 0;}
问题二:
IE6下margin值双倍边距问题(IE6下元素浮动之后margin值变成双倍)
解放方法:将元素转为行内属性
{display: inline}
问题三:
height值设置过小问题(IE6、IE7下设置标签高度小于10px,存在超出已设置的高度的问题)
解决方法:为超出高度的元素添加溢出部分隐藏
{overflow: hidden}
问题四:
标签min-height属性不兼容问题(min-height属性本身就是一个不兼容css属性,所以min-height不能很好地被各个浏览器兼容)
解决方法:
{min-height: 200px;height: auto !important;overflow: visible;height:200px;}
问题五:
图片元素img下默认有间距(IE5下图片元素img出现多余空白)
解决方法:图片使用float属性
问题六:
Firefox和Chrome不兼容cursor:hand
解决方法:cursor:pointer兼容所有浏览器
问题七:
opacity多浏览器透明度兼容问题(opacity是css3里的属性,只有部分浏览器支持)
解决方法:使用各个浏览器的私有属性以支持opacity
{filter: alpha(opacity=50);/*IE*/-moz-opacity: 0.5; //老版Mozilla-khtml-opacity: 0.5; //老版Safariopacity: 0.5;}
问题八:
IE6的3px Bug(一个标签浮动,另一个不浮动的元素自然上浮与之靠近出现3px间距)
解决方法:对浮动的标签设置margin-right: -3px
JS中继承的几种方式总结以及原型的理解
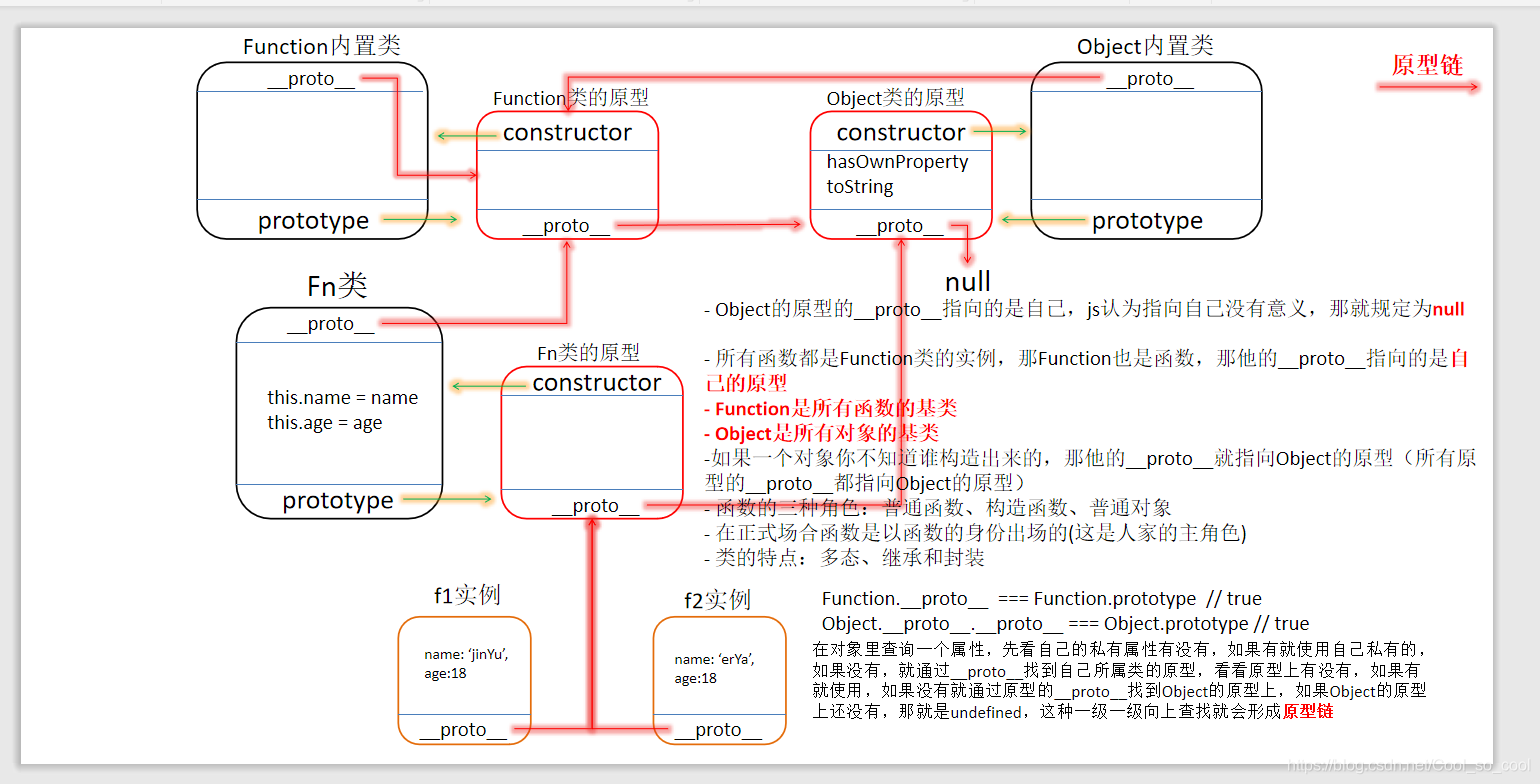
每个函数数据类型天生自带一个prototype属性,prototype的属性值是一个对象数据类型的;
prototype的属性值天生自带一个constructor属性,constructor属性值指向当前原型所属的类;
每一个对象数据类型天生自带一个proto,其属性值指向当前实例所属类的原型
class继承
class语法
class Bar{//这既不是一个函数的{},也不是对象的{}constructor(x, y) {//这个的代码就相当于函数体中的代码//这里面可以新增私有属性//this.x = x;//this.y = y;console.log(x);var a = 1;}//在原型上新增方法getX() {console.log("X");}getY() {console.log("Y")}static x = 1;//static 可以给类新增私有属性y = 2 //在给实例新增私有属性}console.log(typeof Bar)//Bar.prototype.x = 100console.dir(Bar);let a = new Bar(100, 200);console.log(a);
class继承方式
class继承既继承A的私有属性,又能继承其公有属性
class A {constructor() {this.x = 1}getX=()=> {//这是一个普通函数}getY() {//这是一个公有的属性}}let a = new A;//B的prototype中的_proto指向A的原型//class继承既继承A的私有属性,又能继承其公有属性class B extends A {constructor(a) {super(); //super构造器,继承的函数中想增加自己的私有属性,必须加这个,否则会报错this.z = a;}getZ() {}}let b = new B(1);console.log(b);
原型继承
让B的原型地址指向A的实例
function A(){this.x = 10;}A.prototype.getX = function() {}function B() {}B.prototype = new A;//让B的原型地址指向A的实例var b = new B;b.x//b就可以调用A属性上的方法b.getX
call继承
call继承只能继承私有属性,不能继承公有
function A() {this.a = 100;//this=>B的实例}A.prototype.getA = function() {}function B() {//在类B中,调用了类A,并且通过call改变了类A中的this指向,使其指向B的实例;这样类B创建的实例就具有类A的私有属性;这种继承就是call继承A.call(this);//this--->b}var b = new B;console.log(b);
中间类继承
在IE10以下不兼容
function sum() {// arguments.pop();// arguments是实参集合;是类数组,是Object构建出来的实例;不能直接调用到Array原型上的方法,arguments.__proto__指向了Object的原型;//在IE10以下不兼容的;arguments._proto_ = Array.prototype;//arguments是对象只能用_proto_,这种的叫中间类继承arguments.pop();}sum(12, 3, 4, 6, 7, 44, 66, 88, 9);
寄生组合继承
通过b既能找到B的私有和A的公有
//寄生组合继承 callObject.create({a:1});//创建对象,会把第一个参数当成原型上的原型链//继承了私有和公有//context=Object(context) || window;var num = 1;console.log(Object(num)); //new Number(1)var o = Object.create({a:1});console.log(o);function A() {}function B() {A.call(this)}B.prototype = Object.create(A.prototype);var b = new B;console.log(b); //通过b既能找到B的私有和A的公有
函数的防抖和节流
防抖
触发事件后在n秒内函数只能执行一次,如果在n秒内又触发了事件,则会重新计算函数执行时间
防抖函数分为非立即执行版和立即执行版
非立即执行版:触发事件后函数不会立即执行,而是在n秒后执行,如果在n秒内又触发了事件,则会重新计算函数执行时间
立即执行版:触发事件后函数会立即执行,然后n秒内不触发事件才能继续执行函数的效果
节流(throttle)
连续触发事件但是在n秒中只执行一次函数。节流会稀释函数的执行频率。
对于节流,一般有两种方式可以实现,分别是时间戳版和定时器版
时间戳版
function throttle(func, wait) {let previous = 0;return function() {let now = Date.now();let context = this;let args = arguments;if(now - previous > wait) {func.apply(context, args);previous = now;}}}content.onmousemove = throttle(count, 1000);
定时器版
function throttle(func, wait) {let timeout;return function() {let context = this;let args = arguments;if(!timeout) {timeout = setTimeout(() => {timeout = null;func.apply(context, args)}, wait)}}}content.onmousemove = throttle(count, 1000);
区别:时间戳版的函数触发是在时间段内开始的时候,而定时器版的函数触发是在时间段内结束的时候
所以可以结合起来
function throttle(func, wait, type) {if(type === 1) {let previous = 0;} else if(type === 2) {let timeout;}return function() {let context = this;let args = arguments;if(type === 1) {let now = Date.now();if(now - previous > wait) {func.apply(context, args);previous = now;}} else if(type === 2) {if(!timeout) {timeout = setTimeout(() => {timeout = null;func.apply(context, args)}, wait)}}}}
keep-alive
vue的内置组件,当它包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们。keep-alive是一个抽象组件:它自身不会渲染成一个DOM元素,也不会出现父组件链中。
作用
在组件切换过程中将状态保留在内存中,防止重复渲染DOM,减少加载时间及性能消耗,提高用户体验性
原理
在created函数调用时将需要缓存的VNode节点保存在this.cache中/的render(页面渲染)时,如果VNode的name符合缓存条件(可以用include以及exclude控制),则会从this.cache中取出之前缓存的VNode实例进行渲染
VNode:虚拟DOM,其实就是一个JS对象
props
include-字符串或正则表达式。只有名称匹配的组件会被缓存
exclude-字符串或正则表达式。任何名称匹配的组件都不会被缓存
max-数字。最多可以缓存多少组件实例
生命周期函数
activated
在keep-alive组件激活时调用
该钩子函数在服务器端渲染期间不被调用
deactivated
在keep-alive组件停用时调用
该钩子函数在服务器端渲染期间不被调用
被包含在keep-alive中创建的组件,会多出两个生命周期的钩子:activated和deactivated
使用keep-alive会将数据保留在内存中,如果要在每次进入页面的时候获取最新的数据,需要在activated阶段获取数据,承担原来created钩子函数中获取数据的任务。
注意:只要组件被keep-alive包裹时,这两个生命周期函数才会被调用,如果作为正常组件使用,是不会被调用,以及在2.1.0版本之后,使用exclude排除之后,就算被包裹在keep-alive中,这两个钩子函数依然不会被调用!另外,在服务端渲染时,此钩子函数也不会被调用。
缓存所有页面
App.vue
<template><div id="app"><keep-alive><router-view/></keep-alive></div></template><script>export default {name: 'App'}</script>
根据条件缓存页面
//App.vue<template><div id="app"><-- 将缓存name为test的组件 --><keep-alive include='test'><router-view/><keep-alive><-- 将缓存name为a或者b的组件,结合动态组件使用 --><keep-alive include='a,b'><router-view/><keep-alive><-- 使用正则表达式,需使用v-bind --><keep-alive :include='/a|b/'><router-view/><keep-alive><-- 动态判断 --><keep-alive :include='includedComponents'><router-view/><keep-alive><-- 将不缓存name为test的组件 --><keep-alive exclude='test'><router-view/><keep-alive></div></template><script>export default {name: 'App'}</script>
结合router缓存部分页面
//在router目录下的index.js文件里import Vue from 'vue'import Router from 'vue-router'const Home = resolve => require(['@/components/home/home'], resolve)const Goods = resolve => require(['@/components/home/goods'], resolve)const Ratings = resolve => require(['@/components/home/ratings'], resolve)const Seller = resolve => require(['@/components/home/seller'], resolve)Vue.use(Router)export default new Router({mode: 'history',routes: [{path: '/',name: 'home',component: 'goods',children: [{path: 'goods',name: 'goods',component: 'Goods',meta: {keepAlive: false //不需要缓存}},{path: 'ratings',name: 'ratings',component: 'Ratings',meta: {keepAlive: true //不需要缓存}},{path: 'seller',name: 'seller',component: 'Seller',meta: {keepAlive: true //不需要缓存}},]}]})
<template><div id="app"><keep-alive><router-view v-if="$route.meta.keepAlive"></router-view></keep-alive><router-view v-if="!$route.meta.keepAlive"></router-view></div></template><script>export default {name: 'App'}</script>
vue组件之间的数据传递
数据传递的方式
- 父传子:通过props属性传递
- 子传父:通过$emit属性,用来发布自定义事件
- 兄弟组件之间的传递
父传子
- 把父组件的数据以动态属性的方式放在当前子组件的行间属性上
- 在子组件中用props接收到这个属性(数组、对象)
- 在子组件取值使用动态的属性名取值
<body><div id="app"><child :c="msg"></child><child :c="num" :b="obj"></child><child :b="obj"></child></div><script src="vue.js"></script><script>let child = {data() {return {//msg:'xxx' 如果自己身上也有msg这个属性,会去取父组件上的msg}},props: ["c", "b"],template: "<div>{{c}}{{b}}</div>"}let vm = new Vue({el: "#app",data: {msg: "春光正好",num: "越战越勇",obj: "中国加油"},components: {child}})</script></body>
子传父
- 在vue中子组件不能直接修改父组件的数据,想更改数据需要通过$emit属性,用来发布自定义事件,进行修改
- 自定义的名称必须小写,@changemoney=
<body><div id="app">父亲:{{ money }}<!-- 自定义事件 --><son :m="money" @changemoney="fn" :b="fn"></son></div><script src="vue.js"></script><script>let son = {data() {return {}},props: ["m", "b"],//props接收到的属性也会放在组件实例上一份methods: {add() {//this ==> 组件的实例this.$emit("changemoney", 1080);//这里的1080传给fn中的val}},template: "<div>儿子:{{m}}<button @click='add'>点一下</button></div>"}let vm = new Vue({el: "#app",data: {money: 888},methods: {fn(val) {this.money = val;}},components: {son}})</script></body>
子传父的sync修饰符
代码中的两个方法是上面子传父的语法糖,也就是简写,写了这两个后父组件的methods中的方法就可以不写了<body><div id="app">父亲:{{ money }}<!-- 自定义事件 --><!--<son :m="money" @changemoney="fn" :b="fn"></son>--><son :m.sync="money" :v.sync="val"></son></div><script src="node_modules/vue/dist/vue.js"></script><script>//语法糖let son = {data() {return {}},props: ["m", "v"],methods: {add() {this.$emit("update:m", 2000);this.$emit("update:v", 8899);}},template: "<div>儿子:{{m}}<button @click='add'>多点</button>{{v}}</div>"}new Vue({el: "#app",data: {money: 888,val: 1000},methods: {},components: {son}})</script></body>
兄弟直接的数据传递
eventBus
$on: 订阅
$emit: 发布;轮询对应的事件池,让其中的方法执行
let eventBus = new Vue;//这就是一个容器,联系了兄弟之间的纽带
vuex适用于父子、隔代、兄弟组件通信
- vuex是一个专为Vue.js应用程序开发的状态管理模式。每一个vuex应用的核心就是store(仓库)。”store”基本上就是一个容器,它包含着你的应用中大部分的状态(state)
- vuex的状态存储是响应式的。当vue组件从store中读取状态的时候,若store中的状态发生变化,那么相应的组件也会相应地得到高效更新
- 改变store中的状态的唯一途径就是显式地提交(commit)mutation。这样使得我们可以方便地跟踪每一个状态的变化
$route和$router的区别
route是路由信息对象,包括path、params、hash、query、fullPath、matched、name等路由信息参数
router是路由实例对象包括了路由的跳转方法,钩子函数等
ref和$refs的使用
在vue中一般很少直接操作DOM。如果需要操作DOM,我们可以通过ref和$ref来实现
ref
ref被用来给元素或子组件注册引用信息,引用信息将会注册在父组件的$refs对象上,如果是在普通的DOM元素上使用,引用指向的就是DOM元素,如果是在子组件上,引用就指向组件的实例。
$refs
$refs是一个对象,持有已注册过ref的所有的子组件
因此可以通过this.$refs.xxx.属性名(style,attr……)从而达到在vue中操作DOM元素的目的了
v-show和v-if的区别
了解
v-show:通过设置布尔值来控制元素是否显示,如果是true,则显示,false,则隐藏;如果不是一个布尔值,那么会默认转布尔;通过设置元素的display属性来控制是否显示
v-if:控制元素的显示隐藏;如果不是布尔,会默认 转为布尔;如果是false,直接删除了原有的元素
官方解释
v-if是真正的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建;v-if也是惰性的:如果在初始渲染时候条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。
相比之下,v-show就简单的多——不管初始条件是什么,元素总是会被渲染,并且只是简单地基于css进行切换。
一般来说,v-if有更高的切换开销,而v-show有更高的初始渲染开销,因此如果需要非常频繁地切换,使用v-show;如果在运行条件很少改变,使用v-if
相同点和不同点
相同点:
不同点:
实现本质方法不同
v-show本质就是通过设置css中的display设置为none,控制隐藏
v-if是动态的向DOM树内添加或者删除DOM元素
编译的区别
v-show其实就是在控制css
v-if切换有一个局部编译/卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件
编译的条件
v-show都会编译,初始值为false,只是将display设为none,但它也编译了
v-if初始值为false,就不会编译了
性能方面
- v-show只编译一次,后面其实是控制css,而v-if不停的销毁和创建,故v-show性能更好一点
- 注意点:因为v-show实际是操作display:””或者none,当css本身有display:none时,v-show无法显示
- 总结:如果要频繁切换某节点时,使用v-show(无论true或者false初始都会进行渲染,此后通过css来控制显示隐藏,因此切换开销比较小,初始开销较大),如果不需要频繁切换某节点时,使用v-if(因为懒加载,初始为false时,不会渲染,但是因为它是通过添加和删除dom元素来控制显示和隐藏的,因此初始渲染开销较小,切换开销比较大)
v-for和v-if一起使用处理方式
在处于同一节点的时候,v-for优先级比v-if高,这意味着v-if将分别重复运行于每个v-for循环中。即——先运行v-for的循环,然后在每一个v-for的循环中,再进行v-if的条件对比。所以,不推荐v-for和v-if同时使用
<-- template --><template v-for="(item, index) in list" :key="index"><div v-if="item.isShow">{{item.title}}</div></template>
<template><div><div v-for="(user, index) in activeUsers" :key="user.index">{{ user.name }}</div></div></template><script>export default {name: 'A',data() {return {users: [{ name: 'aaa', isShow: true },{ name: 'bbb', isShow: false }]}},computed: {//通过计算属性过滤掉列表中不需要显示的项目activeUsers: function() {return this.users.filter(function(user) {return user.isShow;//返回isShow=true的项,添加到activeUsers数组})}}}</script>
v-model原理
是什么
v-model就是vue的双向绑定的指令,能将页面上空间输入的值同步更新到相关绑定的data属性,也会在更新data绑定属性时候,更新页面上输入控件的值
使用原因
v-model作为双向绑定指令也是vue两大核心功能之一,使用非常方便,提高前端开发效率。在view层,model层相互需要数据交互,即可使用v-model。
原理简述
主要提供两个功能:view层输入值影响data属性值。data属性值发生改变会更新view层的数值变化。
<-- 举例 --><html lang="en"><head><meta charset="utf-8"></head><body><div id="app"><p>{{ name }} </p><input type="text" v-model="name" /></div></body></html>
input输入值后更新data
首先在页面初始化时,vue的编译器会编译该html模板文件,将页面上的dom元素遍历生成一个虚拟的dom树。再递归遍历虚拟的dom的每一个节点。当匹配到其是一个元素而非纯文本,则继续遍历每一个属性。
如果遍历到v-model这个属性,则会这个节点添加一个input事件,当监听从页面输入值的时候,来更新vue实例中的data相对应的属性值
//假如node是遍历到的input节点node.addEventListener("input", function(e) {vm.name = e.target.value;})
data的属性赋值后更新input的值
同样初始化vue实例时,会递归遍历data的每一个属性,并且通过defineProperty来监听每一个属性的get,set方法,从而一旦某个属性重新赋值,则能监听到变化来操作相应的页面控制。
Object.defineProperty(data, "name", {get() {return data["name"];},set(newVal) {let val = data["name"];if(val === newVal) {return;}data["name"] = newVal;//监听到了属性值的变化,假如node是其对应的input节点node.value = newVal;}})
总结
一方面model层通过defineProperty来劫持每个属性,一旦监听到变化通过相关的页面元素更新。另一方面通过编译模板文件,为控件的v-model绑定input事件,从而页面输入能实时更新相关data属性值。
vue生命周期函数
渲染过程
加载渲染过程
父 beforeUpdate->父 created->父 beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父 mounted
子组件更新过程
父 beforeUpdate->子beforeCreate->子updated->父 updated
父组件更新过程
父 beforeUpdate->子updated
销毁过程
父 beforeDestroy->子beforeDestroy->子destroyed->父 destroyed
生命周期
vue是一个构造函数,当执行这个函数时,相当于初始化vue实例;在创建实例过程中,需要设置数据监听,编译模板,将实例挂载到DOM上,数据更新能够让DOM也更新,在这个初始化,又会不同阶段默认调用一些函数执行,这些函数就是生命周期的钩子函数
生命周期钩子函数中的this,会默认指向vue的实例
beforeCreate
- 创建vue实例之前
- 在beforeCreate生命周期函数执行的时候data和methods中的数据都还没初始化,在这个钩子函数中,不能获取data中的数据
- 这个函数不能操作DOM
created
- 创建实例成功之后(一般在这里实现数据的异步请求)
- data和methods中的数据都已经初始化好了,如果想使用methods中的方法,或者是操作data中的数据,最早只能在created中操作
beforeMount
- 渲染DOM之前(加载组件第一次渲染)
- 此函数执行的时候,模板已经在内存中编译好了,但是尚未挂载到页面中去,此时的页面还是旧的(注意一个细节点,更改数据尽量在mounted之前,在mounted之前改数据,不会调用beforeUpdate这个函数;提高性能)
mounted
- 渲染DOM完成(加载组件第一次渲染)
- 数据和DOM都完成挂载,如果要通过某些插件操作页面上的DOM节点,最早在mounted中进行,不过在created请求会更好点
beforeUpdate
- (重新渲染完成之前)更新数据之前执行
- 当数据更新时,会调用beforeUpdate和updated钩子函数;上面四个不再运行
- 页面显示的数据还是旧的,此时data中的数据是最新的,页面尚未和最新的数据保持一致
updated
- 重新渲染完成
- 只要页面中的数据改变了,都会触发,页面和data数据已经保持同步了,都是最新的
- beforeUpdate和updated两个方法要慎用,因为是页面更新数据时触发,在这里操作数据容易死循环
beforeDestroy
- 销毁之前
- 当执行这个钩子函数的时候,vue实例就已经从运行阶段进入到了销毁阶段,实例上所有的methods以及过滤器,指令……都处于可用状态,此时还未销毁
- 如果页面有定时器,会在这个钩子中清除定时器
destroyed
- 销毁完成
- 当执行这个函数时,组件已经被销毁了,所有的数据,方法,指令……都不可以用了,销毁观察者,事件监听者
- DOM元素的事件还在,但是更改数据不会让视图进行更新了
- vue实例销毁后调用,实例中的属性也不再是响应式的,watch被移除
activated
- 当缓存组件有被显示出来时,会触发这个钩子函数
- 写在组件中
deactivated
- 当缓存的组件隐藏时,会触发这个钩子函数
- 写在组件中
errorCapture
- 当子孙组件出错时,会调用这个钩子函数
- 写在组件中
created和mounted区别
created:在模板渲染成html前调用,即通常初始化某些属性值,然后再渲染成视图
mounted:在模板渲染成html后调用,通常是初始化页面完成后,再对html的dom节点进行一些需要的操作
通常created使用的次数多,而mounted通常是在一些插件的使用或者组件的使用中进行操作,比如插件chart.js的使用:
var ctx = document.getElementById(ID)
通常会有这么一步,而如果写入组件中,会发现created中无法对chart进行一些初始化配置,一定要等这个html渲染完后才可以进行,那么mounted就是不二之选。在created的时候,视图中的html并没有渲染出来,所以此时如果直接去操作html的dom节点,一定找不到相关的元素,而在mounted中,由于此时html已经渲染出来,所以可以直接操作dom节点
computed和watch区别
computed计算属性
计算属性基于data中声明过或者父组件传递的props中的数据通过计算得到的一个新值,这个新值只会根据已知值的变化而变化,简言之,这个属性依赖其他属性,由其他属性计算而来的
<p>姓名:{{fullName}}</p>data: {firstName: 'David',lastName: 'Beckham'},computed: {fullName: function() {return this.firstName + '' + this.lastName}}//注:计算属性fullName不能在data中定义,而计算属性值的相关已知值在data中;
在computed属性对象中定义计算属性的方法,和取data对象里的数据属性一样以属性访问的形式调用,即在页面中使用{{ 方法名 }}来显示计算的结果
如果fullName在data中定义了会报错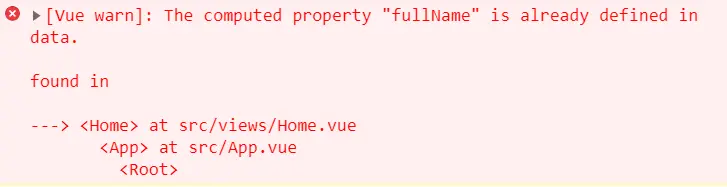
因为如果computed属性值是一个函数,那么默认会走get方法,必须要有一个返回值,函数的返回值就是属性的属性值,计算属性定义了fullName并返回对应的结果给这个变量,变量不可被重复定义和赋值**computed带有缓存功能**
<p>姓名:{{fullName}}</p><p>姓名:{{fullName}}</p><p>姓名:{{fullName}}</p><p>姓名:{{fullName}}</p><p>姓名:{{fullName}}</p>……computed: {fullName: function() {console.log('computed')//在控制台只打印了一次return this.firstName + '' + this.lastName}}//注:计算属性fullName不能在data中定义,而计算属性值的相关已知值在data中;
computed内定义的function只执行一次,仅当初始化显示或者相关的data、props等属性数据发生变化的时候调用;而computed属性值默认会缓存计算结果,计算属性是基于它们的响应式依赖进行缓存的
只有当computed属性被使用后,才会执行computed的代码,在重复的调用中,只有依赖数据不变,直接取缓存中的计算结果,只有依赖型数据发生改变,computed才会重新计算
计算属性的高级
在computed中的属性都有一个get和set方法,当数据变化时,调用set方法。
通过计算属性的getter/setter方法来实现对属性数据的显示和监视,即双向绑定
computed: {fullName: {get() {//读取当前属性值的回调,根据相关的数据计算并返回当前属性的值return this.firstName + '' + this.lastName},set(val) {const names = val ? val.split(''): [];this.firstName = names[0];this.lastName = names[1]}}}
watch监听属性
通过vm对象的$watch或watch配置来监听vue实例上的属性变化,或某些特定数据的变化,然后执行某些具体的业务逻辑操作。当属性变化时,回调函数自动调用,在函数内部进行计算,其可以监听的数据来源:data、props、computed内的数据
watch: {//监听data中的firstName,如果发生了变化,就把变化的值给data中的fullName,val就是firstName的最新值firstName: function(val) {this.fullName = val + '' + this.lastName},lastName: function(val) {this.fullName = this.lastName + '' + val}}//watch监听两个数据,而且代码是同类型的重复的,所以相比用computed更简洁
注:监听函数有两个参数,第一个参数是最新的值,第二个参数是输入之前的值,顺序一定是新值、旧值,如果只写一个参数,那就是最新属性值。
在使用时选择watch还是computed,当需要在数据变化时执行异步或开销较大的操作时,watch方式是最有用的。所以watch一定是支持异步的。
监听复杂数据类型需要用到深度监听deep
data: {fullName: {firstName: 'David',lastName: 'Beckham'}},watch: {fullName: {handler(newVal, oldVal) {console.log(newVal);console.log(oldVal);},deep: true//deep:为了发现对象内部值的变化,可以在选项参数中指定deep:true。//注意监听数组的变更不需要这么做}}
深度监听虽然可以监听到对象的变化,但是无法监听到对象里面哪个具体属性的变化。这是因为它们的引用指向同一个对象/数组,vue不会保留变更之前值的副本。
如果要监听对象的单个属性的变化,有两个方法
直接监听对象的属性
watch: {fullName.firstName: function(newVal, oldVal) {console.log(newVal, oldVal)}}
与computed属性配合使用,computed返回想要监听的属性值,watch用来监听
computed: {firstNameChange() {return this.fullName.firstName}},watch: {firstNameChange() {console.log(this.fullName)}}
总结
watch和computed都是以vue的依赖追踪机制为基础的,当某一个依赖型数据(依赖型数据:简单理解即放在data等对象下的实例数据)发生变化的时候,所有依赖这个数据的相关数据会自动发生变化,即自动调用相关的函数,来实现数据的变动。
当依赖的值变化时,在watch中,是可以做一些复杂的操作,而computed中的依赖,仅仅是一个值依赖另一个值,是值上的依赖
区别
computed:通过属性计算而得来的属性
- 初始化显示或相关的data、props等属性数据发生变化的时候调用
- computed中的函数必须用return返回
- 计算属性不在data中,它是基于data或props中的数据通过计算得到的一个新值,这个新值根据已知值的变化而变化
- 在computed属性对象中定义计算属性的方法,和取data对象里的数据属性一样,以属性访问的形式调用
- 如果computed属性值是函数,那么默认会走get方法,必须要有一个返回值,函数的返回值就是属性的属性值
- computed属性值默认会缓存计算结果,在重复的调用中,只要依赖数据不变,直接取缓存中的计算结果,只有依赖型数据发生改变,computed才会重新计算
- 在computed中的,属性都有一个get和set方法,当数据变化时,调用set方法
watch
- 主要用来监听某些特定数据的变化,从而进行某些具体的业务逻辑操作,可以看作是computed和methods的结合体
- 可以监听的数据来源:data、props、computed内的数据
- watch支持异步
- 不支持缓存,监听的数据改变,直接会触发相应的操作
- 监听函数有两个参数,第一个参数是最新的值,第二个参数是输入之前的值,顺序一定是新值、旧值
- immediate:true 页面首次加载的时候做一次监听
- watch的函数不需要调用
$nextTick
什么是vue.nextTick
在下次DOM更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的DOM
nextTick()是将回到函数延迟在下一次DOM更新数据后调用 ,简单的理解是:当数据更新了,在DOM中渲染后,自动执行该函数注意:vue实现响应式并不是数据发生变化之后DOM立即变化,而是按一定的策略进行DOM的更新
nextTick是在下次DOM更新循环结束之后执行延迟回调,在修改数据之后使用nextTick,则可以在回调中获取更新后的DOM
什么时候需要用vue.nextTick()
vue生命周期的created()钩子函数进行的DOM操作一定要放在vue.nextTick()的回调函数中,原因是created()钩子函数执行的时候DOM,其实并未进行任何渲染,而此时进行DOM操作无异于徒劳,所以此处一定要将DOM操作的js代码放进vue.nextTick()的回调函数中,与之对应的就是mounted钩子函数,因为该钩子函数执行时所有的DOM挂载已完成。
created() {let that = this;that.$nextTick(function() {//不使用this.$nextTick()方法报错that.$refs.aa.innerHTML = "created中更改了按钮内容" //写入到DOM元素})}
当项目中你想在改变DOM元素的数据后基于新的DOM做点什么,对新DOM一些列的js操作都需要放进vue.nextTick()的回调函数中;通俗理解是:更新数据后当你想立即使用js操作新的视图的时候需要使用它vue改变DOM元素结构后使用vue.$nextTick()方法来实现DOM数据更新后延迟执行后续代码
vue.nextTick(callback)——>当数据发生变化,更新后执行回调
vue.$nextTick(callback)——>当dom发生变化,更新后执行回调
mounted和this.$nextTick()区别
mounted适合在初始化渲染完成后数据和页面没有发生变化的情况下使用
在vue的整个生命周期中执行一次;所以使用mounted是无法获取更新后的dom元素
$nextTick适合初始化完成后,我们对数据进行操作并且页面发生了变化时使用,且可以多次使用(可以在dom渲染完成后多次被执行)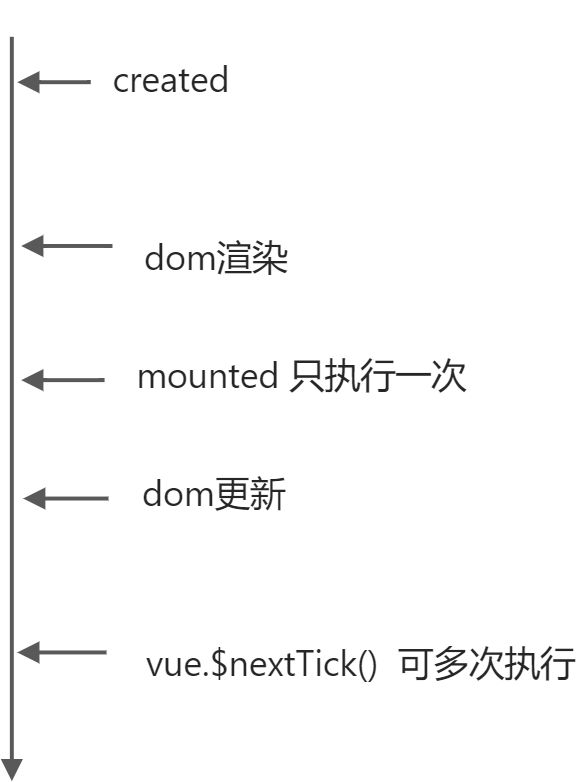
vue-router的next()方法
next():进行管道中的下一个钩子,如果全部钩子执行完了,则导航的状态就是confirmed(确认的)
next(false):中断当前的导航。如果浏览器的URL改变了(可能是用户手动或者浏览器后退按钮),那么url地址会重置到from路由对应的地址
next(‘/‘)或者next({path: ‘/‘}):跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。你可以向next传递任意位置对象,且允许设置诸如replace:true、name:’home’之类的选项以及任何用在router-link的toProp或router.push中的选项
next(error)如果传入next的参数是一个Error实例,则导航会被终止且该错误会被传递给router.onError()注册过的回调
vue渲染页面的时候出现闪烁问题的解决方法
在使用vue绑定数据的时候,渲染页面时会出现变量闪烁
<div id="h_cameraman" v-cloak><public-nav>{{msg}}</public-nav></div>
加载的时候就会看到{{msg}}
解决方法:给最外层的标签加上v-cloak
class里面:
[v-cloak] {display: none}
有时候可能没有用,可能是[v-cloak]{display:none}的层级被覆盖掉了,你需要提高它的层级[v-cloak]{ display:none !important},也有可能把它放进了@import引入的css文件中,它放在@import引入的文件是没有作用的,可以放在link引入的文件来使用,或者直接写在页面的标签中
vue-router实现原理
单页面应用与多页面应用
单页面
第一次进入页面的时候会请求一个html文件,刷新清除一下,切换到其他组件,此时路径也相应变化,但是并没有新的html文件请求,页面内容也变化了
原理是:JS会感知到url的变化,通过这一点,可以用js动态的将当前页面的内容清除掉,然后将下一个页面的内容挂载到当前页面上,这个时候的路由不是后端来做了,而是前端来做,判断页面到底是显示哪个组件,清除不需要,显示需要的组件。这个过程就是单页面应用,每次跳转的时候不需要再请求html文件了
多页面
每一次页面跳转的时候,后台服务器都会给返回一个新的html文档,这种类型的网站也就是多页网站,也叫做多页应用
原理是:传统的页面应用,是用一些超链接来实现页面切换和跳转的
vue-router实现原理
原理核心:更新视图但不重新请求页面
vue-router实现单页面路由跳转,提供了三种方式:hash模式、history模式、abstract模式,根据mode参数来决定采用哪一种方式
路由模式
vue-router提供了三种运行模式
- hash:使用URL hash值来作路由。默认模式
- history:依赖HTML5 History API和服务器配置,查看HTML5 History模式
- abstract:支持所有JavaScript运行环境,如:Node.js服务器端
Hash模式
hash即浏览器url中#后面的内容,包含#。hash是URL中的锚点,代表的是网页中的一个位置,单单改变#后的部分,浏览器只会加载相应位置的内容,不会重新加载页面。
- 即#是用来指导浏览器动作的,对服务器端完全无用,HTTP请求中,不包含#
- 每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用“后退”按钮,就可以回到上一个位置
所以说Hash模式通过锚点值的改变,根据不同的值,渲染指定DOM位置的不同数据
History模式
HTML5 History API提供一种功能,能让开发人员在不刷新整个页面的情况下修改站点的url,就是利用history.pushState API来完成url跳转而无须重新加载页面
由于hash模式会在url中自带#,如果不想要很丑的hash,我们可以用路由的history模式,只需要在配置路由规则时,加入“mode:history”,这种模式充分利用history.pushState API来完成URL跳转而无须重新加载页面
hash模式:xxx.com/#/id=5 请求地址为xxx.com,没有问题
history模式:xxx.com/id=5 请求地址为xxx.com/id=5 ,如果后端没有对应的路由处理,就会返回404错误
abstract模式
使用一个不依赖于浏览器的浏览历史虚拟管理后端
在Weex环境中只支持使用abstract模式,不过,vue-router自身会对环境做校验,如果发现没有浏览器的API,vue-router会自动强制进入abstract模式,所以在使用vue-router时只要不写mode配置即可,默认会在浏览器环境中使用hash模式,在移动端原生环境中使用abstract模式
路由守卫,编程式导航
导航守卫
当切换导航时,会默认调用一些钩子函数,那么这些钩子函数就是导航的守卫;可以在进入这个导航或者离开这个导航时,在钩子函数中做一些事情
:::info
全局路由钩子:beforeEach(to, from, next)、beforeResolve(to, from, next)、afterEach(to, from)
独享路由钩子:beforeEnter(to, from, next)
组件内路由钩子:beforeRouteEnter(to, from, next)、beforeRouteUpdate(to, from, next)、beforeRouteLeave(to, from, next)
:::
导航守卫回调函数
to:目标路由对象
from:即将要离开的路由对象
next:最重要的一个参数,相当于佛珠的线,把一个一个珠子逐个串起来
- 但凡涉及到有next参数的钩子,必须调用next()才能继续往下执行下一个钩子,否则路由跳转等会停止
- 如果要中断当前的导航要调用next(fasle)。如果浏览器的url改变了(可能是用户手动或者浏览器后退按钮),那么url地址会重置到from路由对应的地址。(主要用于登录验证不通过的处理)
- 当然next可以这样使用,next(‘/‘)或者next({path: ‘/‘});跳转到一个不同 的地址。意思是当前的导航被中断,然后进行一个新的导航。可传递的参数与router.push中选项一致
- 在beforeRouteEnter钩子中next((vm) => {})内接收的回调函数参数为当前组件的实例vm,这个回调函数在生命周期mounted之后调用,也就是,他是所有导航守卫和生命周期函数最后执行的那个钩子
- next(error):如果传入next的参数是一个Error实例,则导航会被终止且该错误会被传递给router.onError()注册过的回调
全局的导航守卫
只要配置在这个router上面就会触发这个钩子函数,触发的可能不止一个,有可能点一下就会触发
beforeEach全局的前置钩子函数
只要切换组件,就会执行
在这个钩子函数中获取到用户的信息,进行权限的校验,如果不符合要求,那么next不需要运行;或者直接跳转到首页或403页面
router.beforeEach((to, from, next) => {//console.log(to) 到哪个路由去//console.log(from) 从哪来路由来console.log(1);next();//只有执行了next,才会往下继续跳转路由})
beforeResolve
全局的解析守卫
router.beforeEach((to, from, next) => {//console.log(to) 到哪去//console.log(from) 从哪来console.log(2);next();//只有执行了next,才会往下继续跳转路由})
可以用router.beforeResolve注册一个全局守卫。这和router.beforeEach类似,区别是在导航被确认之前,同时在所有组件内守卫和异步路由组件被解析之后,解析守卫就被调用。(一个解析之前调用,一个解析之后调用)
beforeEach(全局后置的钩子函数)
路由切换成功以后执行的钩子函数,所以没有next函数
router.afterEach((to, from) => {console.log(3);//路由切换成功以后执行的钩子函数})
路由独享守卫(beforeEnter)
在路由配置上直接定义beforeEnter守卫
const router = new VueRouter({routes: [{path: '/foo',component: Foo,beforeEnter: (to, from, next) => {//……}}]})
组件内的守卫
在路由组件内直接定义以下路由导航守卫
let home = {beforeRouteEnter(to, from, next) {//这个钩子函数执行时进入组件实例之前,此时组件实例还没有创建console.log(this); // this ==> windowconsole.log("home beforeRouteEnter")next(vm => {//最后执行//当next执行传入回调函数,回调函数不能立即执行,等到组件实例创建好之后,才会触发这个回调函数;其中vm就是组件实例//console.log(vm)})},beforeRouteUpdate(to, from, next) {console.log("home beforeRouteUpdate")next()},beforeRouteLeave(to, from, next) {//当离开list这个组件时,会调用这个钩子函数console.log("home beforeRouteLeave")next()},template: "<div>这是第{{$route.params.id}}本书</div>"}
- beforeRouteEnter 这个钩子函数执行时进入组件实例之前,此时组件实例还没有创建
守卫不能访问this,因为守卫在导航确认前被调用,因此即将登场的新组件还没被创建。
通过传一个回调给next来访问组件实例,在导航被确认的时候执行回调,并且把组件实例作为回调方法的参数
- beforeRouteUpdate 当复用这个组件并且更新了组件时,这个函数才会被调用
- beforeRouteLeave 当离开list这个组件时,会调用这个钩子函数
这个离开守卫通常用来禁止用户在还未保存修改前突然离开。该导航可以通过next(false)来取消
beforeRouteLeave(to, from, next) {const answer = window.confirm('Do you really want to leave? you have unsaved changes!')if(answer) {next()} else {next(false)}}
执行顺序
相同路由切换路由时:路由守卫执行顺序
beforeEach ==> beforeEnter ==> beforeRouteUpdate ==> beforeResolve ==> afterEach ==>beforeResolve
切换路由时执行顺序
beforeRouteLeave ==> beforeEach ==> beforeEnter ==> beforeRouteEnter ==> afterEach
当进入组件时,先触发全局的前置钩子,然后触发进入组件的路由独享守卫,然后触发组件内部的beforeRouteEnter,最后触发全局的beforeResolve和全局后置钩子函数
完整的导航解析流程
导航被触发
在失活的组件里调用离开守卫
调用全局的beforeEach守卫
在重用的组件里调用beforeRouteUpdate守卫
在路由配置里调用beforeEnter
解析异步路由组件
在被激活的组件里调用beforeRouteEnter
调用全局的beforeResolve守卫
导航被确认
调用全局的afterEach钩子
触发DOM更新
用创建好的实例调用beforeRouteEnter守卫传给next的回调函数
vue编程式的导航跳转传参的方式有哪些
//命名的路由router.push({name: 'user', params: { userId: '123'}})//带查询的参数,变成了/register?plan=privaterouter.push({ path: 'register', query: { plan: 'private' }})

若有收获,就点个赞吧
0 人点赞
