为什么引入集合
1、集合与数组都是存储多个数据的结构
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。
说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(比如:.txt,.jpg,.avi,数据库等)
2、数组在存储多个数据方面的特点
- 一旦初始化以后,其长度就确定了。
- 数组存储数据的特点:有序、可重复。
- 数组一旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。比如:
String[] arr; int[] arr1;
3、数组在存储多个数据反面的缺点
- 一旦初始化以后,其长度就不可修改。
- 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
- 对于获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用。
- 对于存储无序、不可重复的数据的需求,数组不能满足。
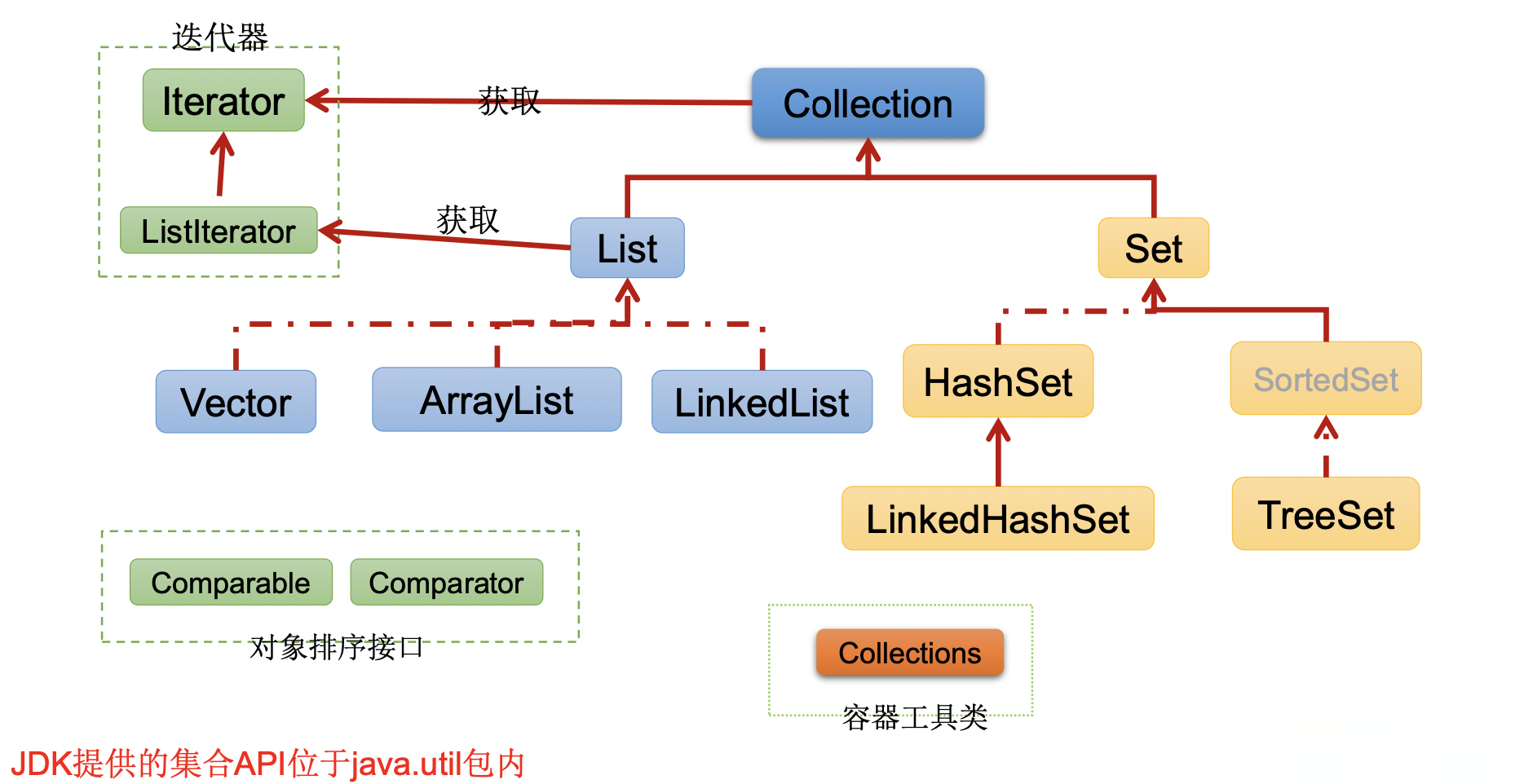
常用的接口与实现类
Java集合可以分为 **Collection** 和 **Map** 两种体系:
Collection接口:单列集合,用来存储一个一个的对象。- List 接口:存储有序的、可重复的数据。可以类比“动态”数组
ArrayListLinkedListVector
Set接口:存储无序的、不可重复的数据。可以类比高中讲的“集合”HashSetLinkedHashSet
TreeSet
- List 接口:存储有序的、可重复的数据。可以类比“动态”数组
- Map 接口:双列集合,用来存储一对一对(key - value)的数据。
HashMapLinkedHashMap
TreeMapHashtableProperties
Collection 接口
关于 Collection 接口的说明:
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法可以通用。- JDK 不提供
Collection接口的任何直接实现,而是提供更具体的子接口来实现(比如:Set和List)。 - 在 Java5 之前, Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成
Object类型处理,从 JDK 5.0 增加了泛型以后, Java 集合可以记住容器中对象的数据类型。
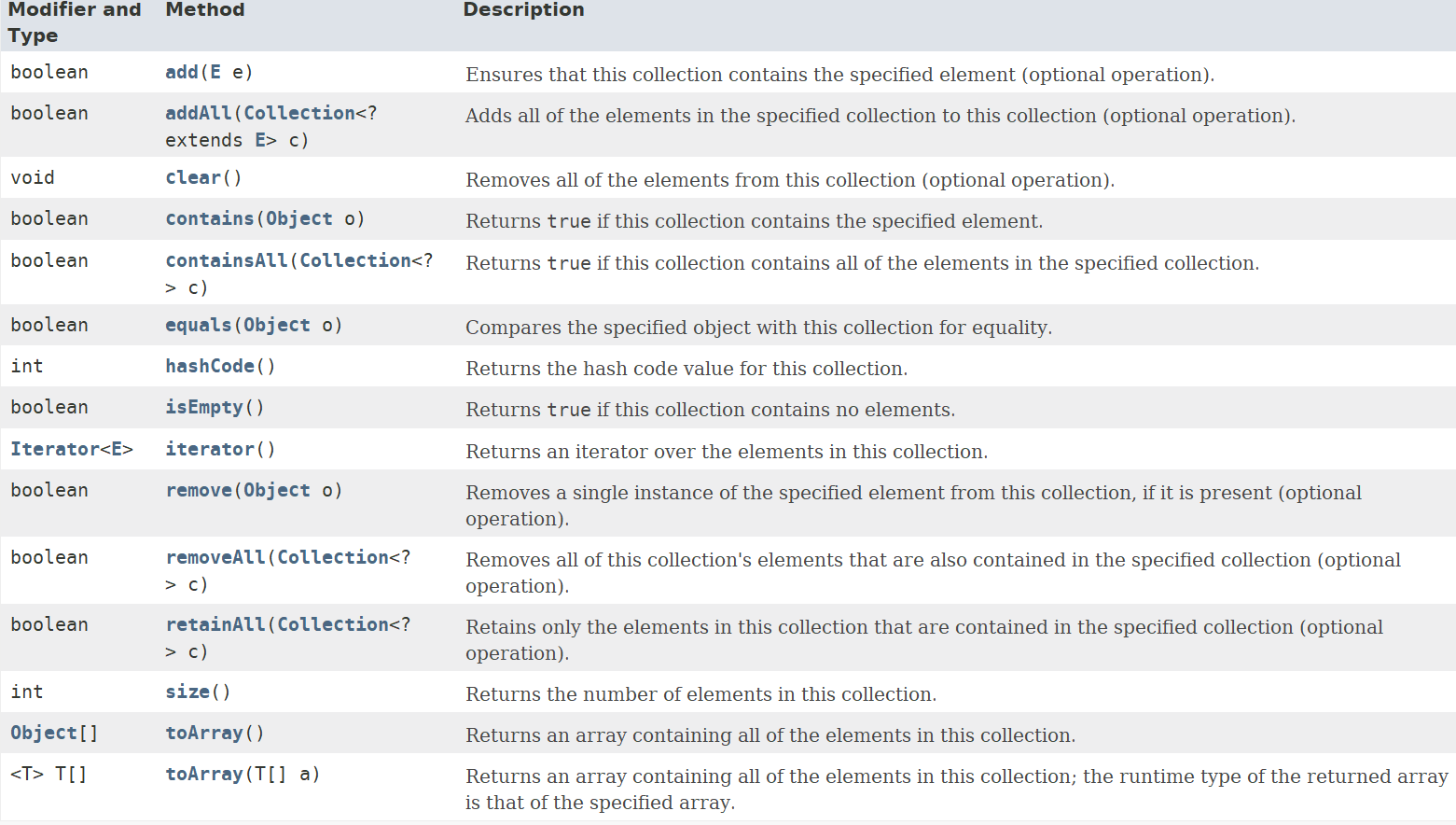
Collection 接口15个基本方法
【示例代码】
public class CollectionTest {@Testpublic void test1() {// ArrayList是collection接口的一个实现类// 用它来测试 Collection接口 通用的15个抽象方法Collection<Object> coll = new ArrayList<Object>();//1、add(Object e):将元素e添加到集合coll中coll.add("AA");coll.add(12);//自动装箱coll.add(new Date());//2、size():获取添加的元素的个数System.out.println(coll.size());//3//3、addAll(Collection coll1):将coll1集合中的元素添加到当前的集合中Collection<Object> coll1 = new ArrayList<Object>();coll1.add("BB");coll1.add(456);coll.addAll(coll1);System.out.println(coll.size());//5System.out.println(coll);//[AA, 12, Thu Dec 31 16:25:09 CST 2020, BB, 456]//4、clear():清空集合元素coll.clear();//5、isEmpty:判断当前集合是否为空// 底层实现:return size == 0;System.out.println(coll.isEmpty());//true}@Testpublic void test2() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(new String("Tom"));coll.add(new Person("Jerry", 20));coll.add(false);/*6、contains(Object obj):判断当前集合中是否包含obj我们在判断时会调用obj对象所在类的equals()故,向Collection接口的实现类的对象中添加数据obj时,要求obj所在类要重写equals()*/System.out.println(coll.contains(123));//true//string重写了equals方法,故为trueSystem.out.println(coll.contains(new String("Tom")));//true//Person类重写equals方法后会由false变为trueSystem.out.println(coll.contains(new Person("Jerry", 20)));//7、containsAll(Collection coll1)//判断形参coll1中的所有元素是否都存在于当前集合中。Collection<Object> coll1 = Arrays.asList(123, "Tom");System.out.println(coll.containsAll(coll1));//true//8、remove(Object obj):从当前集合中移除obj元素coll.remove(new Person("Jerry", 20));System.out.println(coll);//[123, Tom, false]//9、removeAll(Collection coll1)://差集:从当前集合中移除与 coll1中所共有的元素coll.removeAll(coll1);System.out.println(coll);//[false]}@Testpublic void test3() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(false);coll.add(new String("Tom"));//10、retainAll(Collection coll1)//交集:获取当前集合和 coll1集合的交集,并返回给当前集合Collection coll1 = Arrays.asList(123,456,false);coll.retainAll(coll1);System.out.println(coll);//[123, false]//11、equals(Object obj):要想返回true,需要当前集合和形参集合的元素都相同System.out.println(coll.equals(coll1));//false}@Testpublic void test4() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(new Person("Jerry",20));coll.add(new String("Tom"));coll.add(false);//12、hashCode():返回当前对象的哈希值System.out.println(coll.hashCode());//-1351709216//13、toArray():集合 --->数组Object[] arr = coll.toArray();for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}//拓展:调用Arrays类的静态方法asList():数组 --->集合List<String> list = Arrays.asList(new String[]{"AA", "BB", "CC"});System.out.println(list);//[AA, BB, CC]//易错点:List arr1 = Arrays.asList(new int[]{123, 456});System.out.println(arr1);// 把整个数组当成一个元素了:[[I@396e2f39]List arr2 = Arrays.asList(new Integer[]{123, 456});System.out.println(arr2);// [123, 456]}@Testpublic void test5() {//14、iterator():返回Iterator接口的实例,用于遍历集合元素//详见下面的 IteratorTest}}
Iterator 迭代器接口
【基本概念】
**Iterator**对象称为迭代器(设计模式的一种),GOF《设计模式》给迭代器模式的定义为:提供一种方法访问一个容器对象中的各个元素,而又不需暴露该对象的内部细节。迭代器模式就是为容器而生,类似于“公交车上的售票员”。**Collection**接口继承了**Iterable**接口,Collection接口有一个iterator()方法- 所有实现了
Collection接口的集合类都有一个iterator()方法,用来返回一个实现了Iterator接口的对象。 - 集合对象每次调用
iterator()方法都会得到一个全新的迭代器对象。 - 新的迭代器对象默认游标都在集合的第一个元素之前。
- 所有实现了
**Iterator**仅用于遍历**Collection**集合,其本身并不承装对象,如果需要创建Iterator对象,则必须有一个被迭代的集合。
【基本方法】
使用注意事项
- 在调用
iterator.next()方法之前必须要调用iterator.hasNext()进行检测。若不调用,且下一条记录无效,会抛出NoSuchElementException异常。 iterator.next()会做两个动作:- 指针下移一位
- 将指针下移一位后的位置上的元素返回
iterator.remove()可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove()方法,不是集合对象的remove()方法。- 如果还未调用
next()或在上一次调用next()之后已经调用了remove(),再调用remove()都会报IllegalStateException异常。

【示例代码】
public class IteratorTest {@Testpublic void test1() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(456);coll.add(new Person("Jerry", 20));coll.add(new String("Tom"));coll.add(false);Iterator<Object> iterator = coll.iterator();// 方式一:(不推荐)// System.out.println(iterator.next());// System.out.println(iterator.next());// System.out.println(iterator.next());// System.out.println(iterator.next());// System.out.println(iterator.next());// System.out.println(iterator.next());//java.util.NoSuchElementException// 方式二:(不推荐)// for (int i = 0; i < coll.size(); i++) {// System.out.println(iterator.next());// }// 方式三:(推荐使用)while (iterator.hasNext()) {System.out.println(iterator.next());}// 方式四:(推荐使用)增强 for 循环for (Object obj : coll) {System.out.println(obj)}}@Testpublic void test2() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(456);coll.add(new Person("Jerry", 20));coll.add(new String("Tom"));coll.add(false);Iterator<Object> iterator = coll.iterator();// 错误方式一:// 先输出456、Tom、然后报异常 NoSuchElementExceptionwhile ((iterator.next()) != null) {System.out.println(iterator.next());}// 错误方式二:// 一直输出123的死循环while (coll.iterator().hasNext()) {System.out.println(coll.iterator().next());}}@Testpublic void test3() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(456);coll.add(new Person("Jerry", 20));coll.add(new String("Tom"));coll.add(false);Iterator<Object> iterator = coll.iterator();// 删除集合中的 Tom// 如果还未调用next()或在上一次调用 next 方法之后已经调用了 remove 方法,// 再调用 remove都会报异常 IllegalStateExceptionwhile (iterator.hasNext()) {// iterator.remove();Object obj = iterator.next();if ("Tom".equals(obj)) {iterator.remove();// iterator.remove();}}System.out.println(coll);// [123, 456, Person{name='Jerry', age=20}, false]}}
增强 for 循环
【基本概念】
Java 5.0 提供了 foreach 循环迭代访问 Collection 和 数组。
基本格式是:for( 集合或数组元素的类型 局部变量 : 集合或数组对象 ){ }
- 遍历操作不需获取
Collection或数组的长度,无需使用索引访问元素。 - 遍历集合的底层还是调用
Iterator来完成操作的。 - 遍历的过程其实是取出每一项赋值给局部变量,原来的每一项没有发生改变。
【示例代码】
public class ForEachTest {@Testpublic void test1() {Collection<Object> coll = new ArrayList<Object>();coll.add(123);coll.add(456);coll.add(new Person("Jerry",20));coll.add(new String("Tom"));coll.add(false);//for(集合元素的类型 局部变量 : 集合对象)//内部仍然调用了迭代器。for (Object obj : coll) {System.out.println(obj);}}@Testpublic void test2() {int[] arr = {1, 2, 3, 4, 5};//for(数组元素的类型 局部变量 : 数组对象)for (int i : arr) {System.out.println(i);}}// 练习题@Testpublic void test3() {String[] arr = {"MM","MM","MM"};// 方式一:普通for赋值// 改变原来的数组,遍历会输出"GG"for (int i = 0; i < arr.length; i++) {arr[i] = "GG";}// 方式二:增强for循环赋值// 不改变原来的数组,遍历会输出"MM"for (String s : arr) {s = "GG";}// 遍历结果for(int i = 0;i < arr.length;i++){System.out.println(arr[i]);}}}
List 接口
List 接口是 Collection 接口的一个子接口:存储有序的、可重复的数据,可以视为一种“动态”的数组,用来替换原有的数组。
List 接口有三种常用的实现类:
**ArrayList**- 作为
List接口的主要实现类; - 线程不安全的,效率高;
- 底层使用
Object[] elementData存储。
- 作为
**LinkedList**- 对于频繁的插入、删除操作,使用此类效率比
ArrayList高; - 底层使用双向链表存储。
- 对于频繁的插入、删除操作,使用此类效率比
**Vector**- 作为
List接口的古老实现类;(Vector在JDK1.0时就有了,List接口在JDK1.2时才出现) - 线程安全的,效率低;
- 底层使用
Object[] elementData存储
- 作为
ArrayList
一、jdk 7 中的情况ArrayList list = new ArrayList();底层创建了长度是10的Object[] elementData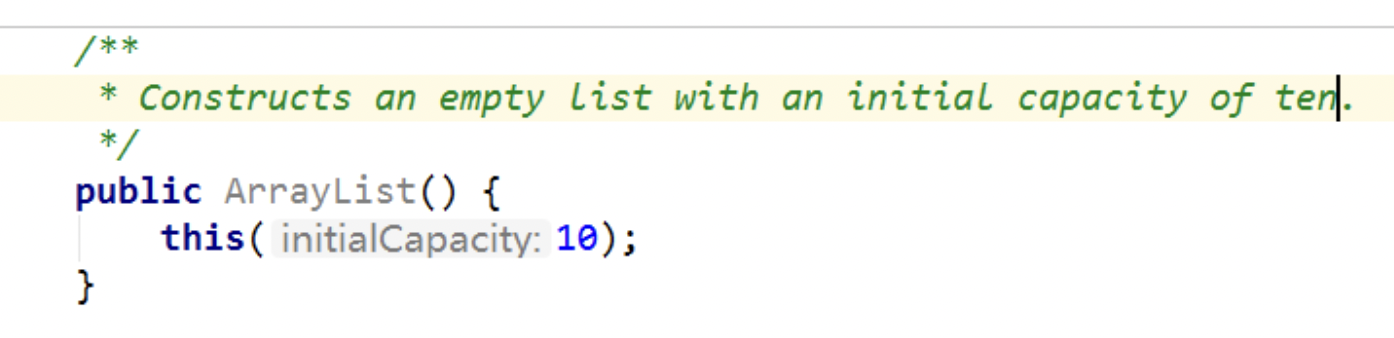
list.add(123);相当于是elementData[0] = new Integer(123);...list.add(11);如果此次的添加导致底层elementData数组容量不够,则扩容。
默认情况下,扩容为原来的容量的1.5倍,如果还不够就扩容为最低要求的容量,同时需要将原有数组中的数据复制到新的数组中。
结论:建议开发中使用带参的构造器:ArrayList list = new ArrayList(int capacity)
二、jdk 8 中的情况ArrayList list = new ArrayList(); 底层创建了Object[] elementData,并初始化为{},并没有创建长度为10的数组。list.add(123); 第一次调用add()时,底层才创建了长度 10 的数组,并将数据 123 添加到elementData[0]
…
后续的添加和扩容操作与jdk 7 无异。
三、小结
jdk 7 中的ArrayList的对象的创建类似于单例的饿汉式,而jdk 8 中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
LinkedList
LinkedList list = new LinkedList();内部声明了Node类型的first和last属性,默认值为nulllist.add(123); 将123封装到Node中,创建了Node对象。
其中,Node定义为:体现了LinkedList的双向链表的说法。
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
Vector
jdk 7 和 jdk 8 中通过Vector()构造器创建对象时,底层都创建了长度为 10 的数组。
在扩容方面,默认扩容为原来的数组长度的2倍。
面试题:**ArrayList**、**LinkedList**、**Vector**三者的异同
相同:
- 三个类都是实现了
List接口。 - 存储数据的特点相同:存储有序的、可重复的数据。
不同:见上。
List 接口常用方法
总结:
- 增:
add(Object obj) - 删:
remove(int index)remove(Object obj)—-> 属于是Collection接口提供的方法
- 改:
set(int index, Object ele) - 查:
get(int index) - 插:
add(int index, Object ele) - 长度:
size() - 遍历:
Iterator迭代器方式- 增强for循环(底层也是 Iterator)
- 普通的循环
【示例代码】
@Testpublic void test1() {ArrayList<Object> list = new ArrayList<Object>();list.add(123);list.add(456);list.add("AA");list.add(new Person("Tom", 12));list.add(456);// 1、void add(int index, Object ele):// 在 index 位置插入ele元素list.add(1, "BB");System.out.println(list);// 2、boolean addAll(int index, Collection eles):// 从index位置开始将eles中的所有元素添加进来List<Integer> list1 = Arrays.asList(1, 2, 3);list.addAll(list1);System.out.println(list.size());// 9// 3、Object get(int index):// 获取指定index位置的元素System.out.println(list.get(0));// 123// 4、int indexOf(Object obj):// 返回obj在集合中首次出现的位置。如果不存在,返回-1int index = list.indexOf(456);System.out.println(index);// 2// 5、int lastIndexOf(Object obj):// 返回obj在当前集合中末次出现的位置。如果不存在,返回-1.System.out.println(list.lastIndexOf(456));//5// 6、Object remove(int index):// 移除指定index位置的元素,并返回此元素Object obj = list.remove(2);System.out.println(obj);// 456System.out.println(list);// 7、Object set(int index, Object ele):// 设置指定index位置的元素为elelist.set(1, "CC");System.out.println(list);// 8、List subList(int fromIndex, int toIndex):// 返回从fromIndex到toIndex位置的左闭右开区间的子集合// 原来的集合并不发生改变List<Object> subList = list.subList(0, 3);System.out.println(subList);// [123, CC, AA]System.out.println(list);// [123, CC, AA, Person{name='Tom', age=12}, 456, 1, 2, 3]}
遍历集合的三种方式
@Testpublic void test2() {// 遍历集合的三种方式ArrayList<Object> list = new ArrayList<>();list.add(123);list.add(456);list.add("AA");// 方式一:iterator迭代器方式Iterator<Object> iterator = list.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}// 方式二:增强for循环for (Object obj : list) {System.out.println(obj);}// 方式三:普通for循环for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}}
【易错点】
删除数字时候,传入的数字会被认为是索引,要想删除指定的数字,可以用其包装类。
@Testpublic void testListRemove() {// 区分List中的 remove(int index)和 remove(Object obj)ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);updatedList(list);System.out.println(list);}private void updatedList(List<Integer> list) {// list.remove(2);// 删除的时索引2,会导致输出[1, 2]list.remove(new Integer(2));// 删除的是数字2,会导致输出[1, 3]}
Set 接口
Set 接口是Collection接口的子接口:存储无序的、不可重复的数据 ,类似于高中讲的“集合”。
**Set** 接口的实现类
**HashSet**- 作为
Set接口的主要实现类; - 线程不安全的;
- 可以存储
null值。
- 作为
**LinkedHashSet**- 它是
HashSet的子类; - 遍历其内部数据时,可以按照添加的顺序遍历;
- 对于频繁的遍历操作,
LinkedHashSet效率高于HashSet。
- 它是
**TreeSet**- 要求放入同一个类的对象,可以按照添加对象的指定属性进行排序。
**Set** 接口的方法Set 接口中没有额外定义新的方法,使用的都是 Collection 中声明过的方法。
要求:
- 向
Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()。 - 重写的
hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列值。 - 重写两个方法的小技巧:对象中用作
equals()方法比较的Field,都应该用来计算hashCode值。

HashSet
1、关于无序性和不可重复性
- 无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
- 不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个。
2、HashSet 的底层实现
数组+链表的结构。
图解: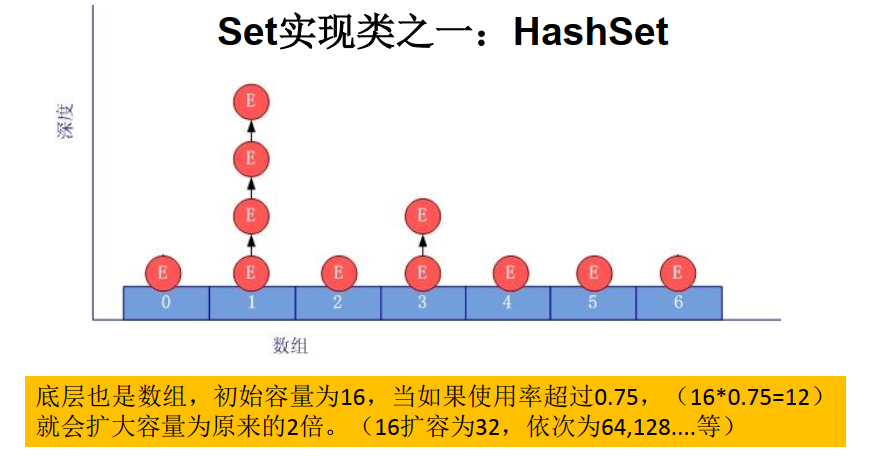
3、HashSet 添加元素的过程
我们向 HashSet 中添加元素 a,首先调用元素 a 所在类的 hashCode() 方法,计算元素 a 的哈希值,此哈希值接着通过某种算法计算出在HashSet 底层数组中的存放位置(即为:索引位置),然后判断:
数组此位置上是否已经有元素:
- 如果此位置上没有其他元素,则元素 a 添加成功。 —->情况1
- 如果此位置上有其他元素 b (或以链表形式存在的多个元素),则比较元素 a 与元素 b 的 hash 值:
- 如果 hash 值不相同,则元素 a 添加成功。—->情况2
- 如果 hash 值相同,进而需要调用元素 a 所在类的
equals()方法:- 如果
equals()返回 true,元素 a 添加失败 - 如果
equals()返回 false,则元素 a 添加成功。—->情况3
- 如果
对于添加成功的情况 2 和情况 3 而言:元素 a 与已经存在指定索引位置上数据以链表的方式存储。
- jdk 7:元素 a 放到数组中,指向原来的元素。
- jdk 8:原来的元素在数组中,指向元素 a
- 巧记:七上八下
示例代码
@Testpublic void test1() {// HashSet()不会按照添加的顺序输出// 如果改用LinkedHashSet()会按照添加的顺序输出HashSet<Object> set = new HashSet<>();set.add(456);set.add(123);// 第二个123不会被添加set.add(123);set.add("AA");set.add("CC");set.add(new Person("Tom",12));// 如果Person类不重写equals()和hashcode(),下面的也会被添加set.add(new Person("Tom",12));Iterator<Object> iterator = set.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}}
输出结果: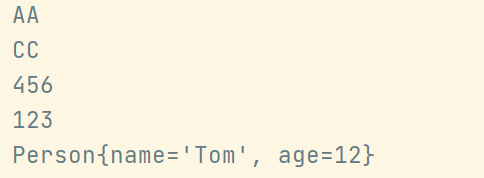
LinkedHashSet
LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。这使得元素看起来是以插入顺序保存的。
优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet。
缺点:LinkedHashSet 插入性能略低于 HashSet
图解 LinkedHashSet 底层结构: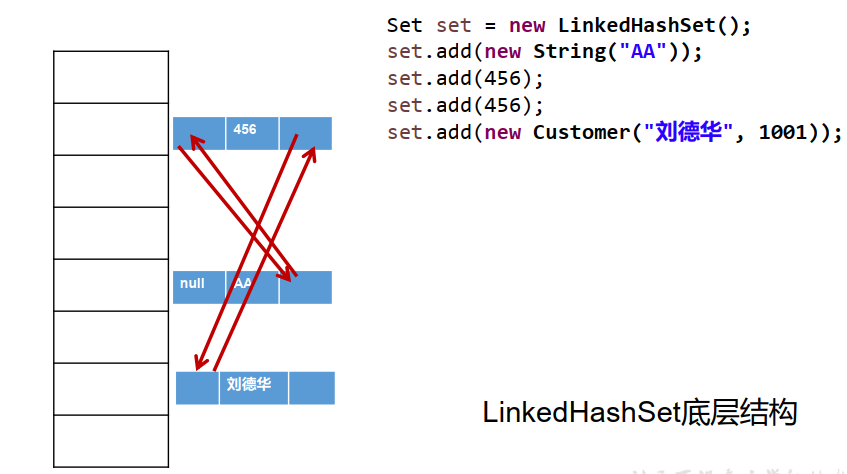
TreeSet
TreeSet 是 SortedSet 接口的实现类,TreeSet 可以确保集合元素处于排序状态。
TreeSet 底层使用红黑树结构存储数据。
向 TreeSet 中添加的数据,要求是相同类的对象。
TreeSet 两种排序方法
- 自然排序(默认情况下,TreeSet 采用自然排序)
- 自然排序中,比较两个对象是否相同的标准为:compareTo()返回0,不再是equals()
- 定制排序
- 定制排序中,比较两个对象是否相同的标准为:compare()返回0,不再是equals()
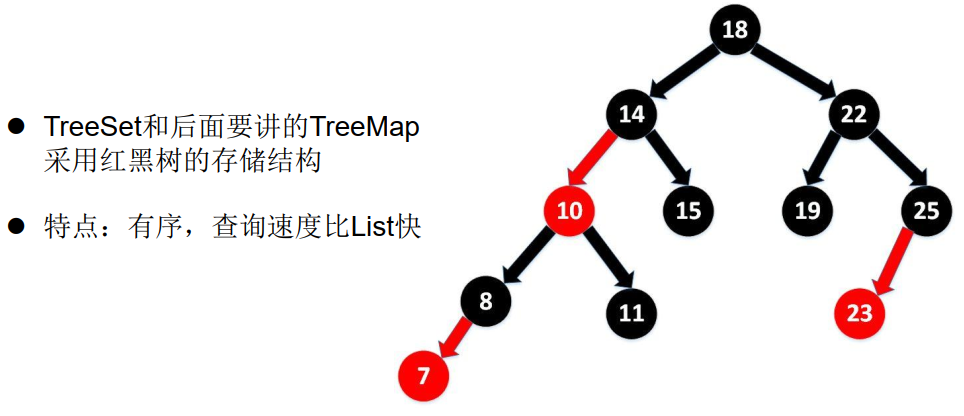
示例代码
@Testpublic void test2() {TreeSet<Object> set = new TreeSet<>();set.add(123);// 下面一句会报异常:ClassCastException// set.add("AA");set.add(12);set.add(-2);set.add(-2);set.add(33);Iterator<Object> iterator = set.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}}
输出结果是:(会自动按照从小到大的顺序,去重排列好)
-2
12
33
123
示例代码(自然排序)
public class SetTest {@Testpublic void test3() {// 采用定制排序的方法TreeSet<Object> set = new TreeSet<>();set.add(new Person("Alice", 40));set.add(new Person("Jerry", 33));set.add(new Person("Mike", 65));set.add(new Person("Mike", 20));set.add(new Person("Tom", 12));Iterator<Object> iterator = set.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}}}
其中 Person 类修改如下:(增加自然排序)
public class Person implements Comparable {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person persson = (Person) o;return age == persson.age && Objects.equals(name, persson.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}/*** 实现Comparable接口的compareTo()方法:名字降序,年龄升序* @param o* @return*/@Overridepublic int compareTo(Object o) {if (o instanceof Person) {Person person = (Person) o;int compare = -this.name.compareTo(person.name);if (compare != 0) {return compare;} else {return Integer.compare(this.age, person.age);}} else {throw new RuntimeException("输入的类型不匹配");}}}
输出结果为:
示例代码(定制排序)
@Testpublic void test4() {Comparator<Object> comparator = new Comparator<>() {@Overridepublic int compare(Object o1, Object o2) {if (o1 instanceof Person && o2 instanceof Person) {Person p1 = (Person) o1;Person p2 = (Person) o2;int compare = Integer.compare(p1.getAge(), p2.getAge());if (compare != 0) {return compare;} else {return -p1.getName().compareTo(p2.getName());}} else {throw new RuntimeException("输入的类型不匹配");}}};TreeSet<Object> set = new TreeSet<>(comparator);set.add(new Person("Alice", 40));set.add(new Person("Jerry", 33));set.add(new Person("Mike", 65));set.add(new Person("Mike", 20));set.add(new Person("Tom", 12));Iterator<Object> iterator = set.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}}
输出结果为:
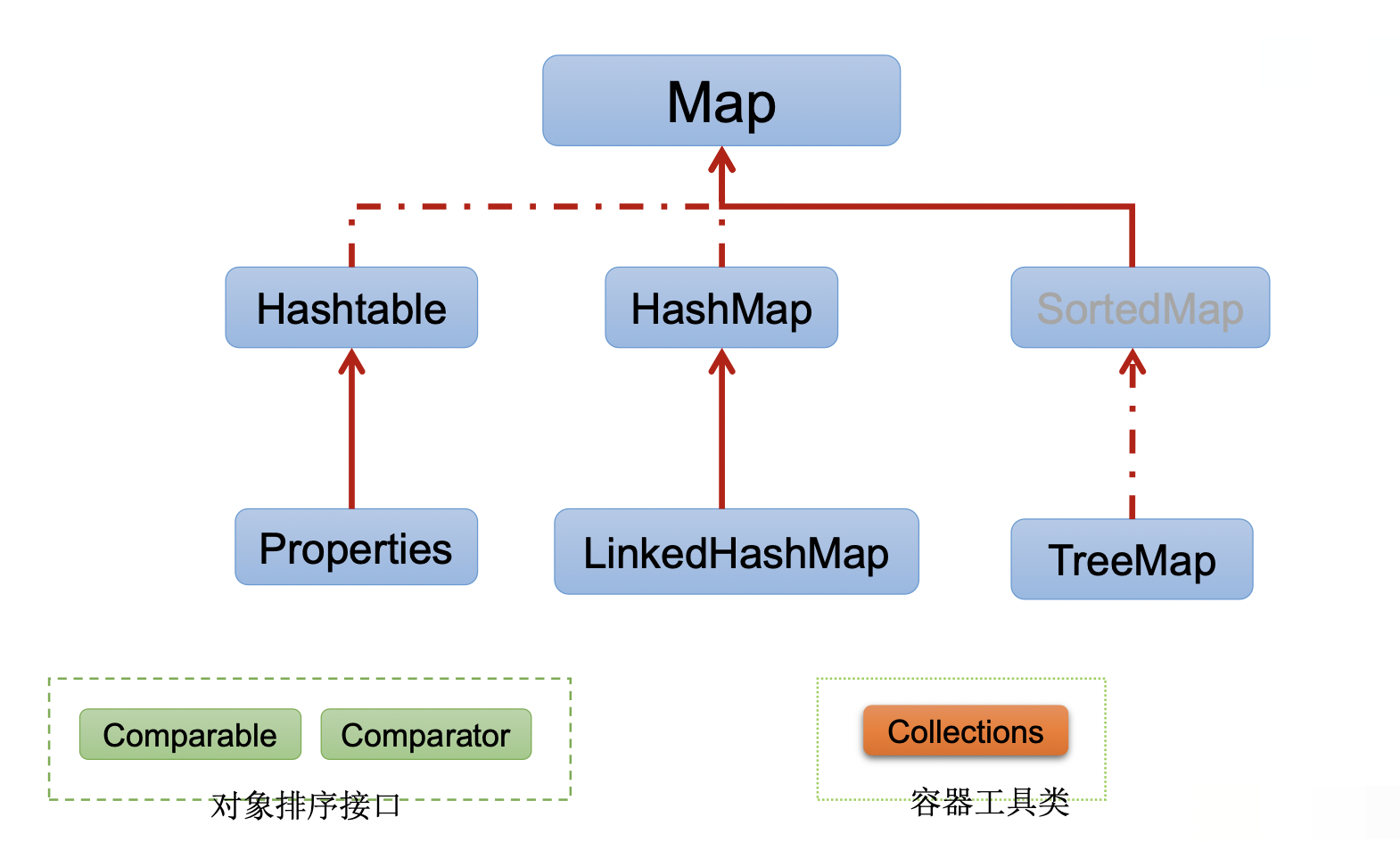
Map 接口
Map 接口的实现类的结构
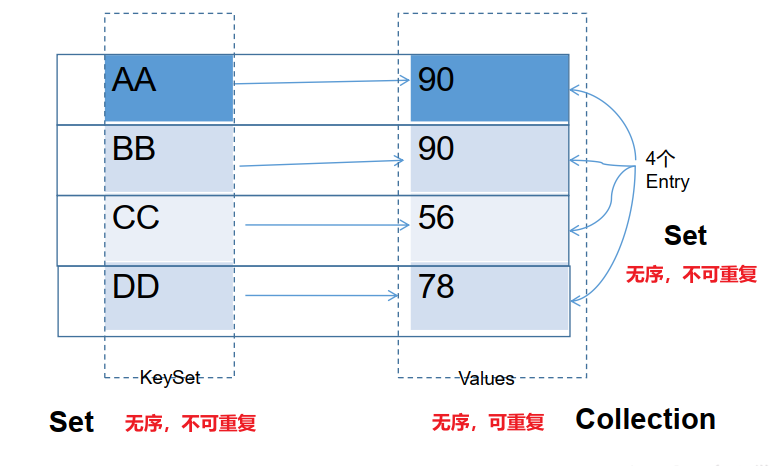
Map:双列数据,存储key-value对的数据,类似于高中的函数:y = f(x)
- HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value
- LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
- TreeMap:保证按照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序,底层使用红黑树
- Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
- Properties:常用来处理配置文件。key和value都是String类型
Map结构的理解
- Map 中的 key:无序的、不可重复的,使用 Set 存储所有的 key
- key 所在的类要重写 equals() 和 hashCode() (以HashMap为例)
- Map 中的 value:无序的、可重复的,使用 Collection 存储所有的value
- value 所在的类要重写 equals()
- 一个键值对 key-value 构成了一个 Entry 对象:无序的、不可重复的,使用 Set 存储所有的 entry
Map的常用方法

总结常用方法:
- 添加/修改:
put(Object key, Object value) - 删除:
remove(Object key) - 查询:
get(Object key)/containsKey(Object key)/containsValue(Object value) - 长度:
size()/isEmpty() - 遍历:
keySet()/values()/entrySet()
示例代码:
public class MapTest {@Testpublic void test1() {Map map = new HashMap();// map = new Hashtable(); // NullPointerExceptionmap.put(null, 123);System.out.println(map);}@Testpublic void test2() {HashMap map = new HashMap();// put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中map.put("AA", 123);map.put(45, 123);map.put("BB", 56);// 修改map.put("AA", 87);System.out.println(map);// putAll(Map m):将m中的所有key-value对存放到当前map中HashMap map1 = new HashMap();map1.put("CC", 12);map1.put("DD", 24);map.putAll(map1);System.out.println(map);// remove(Object key):移除指定key的key-value对,并返回valueObject obj = map.remove("CC");System.out.println(obj);System.out.println(map);// clear():清空当前map中的所有数据map.clear();//与map = null操作不同System.out.println(map);// size():返回map中key-value对的个数System.out.println(map.size());// isEmpty():判断当前map是否为空System.out.println(map.isEmpty());}@Testpublic void test3() {Map map = new HashMap();map.put("AA",123);map.put(45,123);map.put("BB",56);// get(Object key):获取指定key对应的valueSystem.out.println(map.get(45));//123// containsKey(Object key):是否包含指定的keySystem.out.println(map.containsKey("BB"));//true// containsValue(Object value):是否包含指定的valueSystem.out.println(map.containsValue(123));//true// equals(Object obj):判断当前map和参数对象obj是否相等Map map1 = new HashMap();map1.put("AA",123);map1.put(45,123);map1.put("BB",56);System.out.println(map.equals(map1));//true}@Testpublic void test4() {Map map = new HashMap();map.put("AA",12);map.put(12,24);map.put("BB",144);//遍历所有的key集:keySet()Set set = map.keySet();Iterator iterator = set.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}System.out.println();//遍历所有的value集:values()Collection values = map.values();for (Object obj : values) {System.out.println(obj);}System.out.println();//遍历所有的key-value//方式一:entrySet()Set entrySet = map.entrySet();Iterator iterator1 = entrySet.iterator();while (iterator1.hasNext()) {//entrySet集合中的元素都是entryMap.Entry entry = (Map.Entry) iterator1.next();System.out.println(entry.getKey() + "::" + entry.getValue());}System.out.println();//方式二:Set keySet = map.keySet();Iterator iterator2 = keySet.iterator();while (iterator2.hasNext()) {Object key = iterator2.next();Object value = map.get(key);System.out.println(key + "::" + value);}}}
HashMap
HashMap的底层:
数组+链表 (jdk7及之前)
数组+链表+红黑树 (jdk 8)
以 jdk7 为例说明:HashMap map = new HashMap();
在实例化以后,底层创建了长度是16的一维数组Entry[] table。
…可能已经执行过多次put…map.put(key1,value1);
首先,调用key1所在类的 hashCode() 计算key1哈希值,此哈希值经过某种算法计算以后,得到在 Entry 数组中的存放位置。
- 如果此位置上的数据为空,此时的 key1-value1 添加成功。 ——情况1
- 如果此位置上的数据不为空,意味着此位置上存在一个或多个数据(以链表形式存在),比较key1和已经存在的一个或多个数据的哈希值:
- 如果 key1 的哈希值与已经存在的数据的哈希值都不相同,此时 key1-value1 添加成功。——情况2
- 如果 key1 的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续调用 key1 所在类的
equals(key2)方法,比较:- 如果
equals()返回false:此时 key1-value1 添加成功。——情况3 - 如果
equals()返回true:使用 value1 替换value2。
- 如果
补充:关于情况2和情况3:此时 key1-value1 和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,当超出临界值且要存放的位置非空时,扩容。
默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。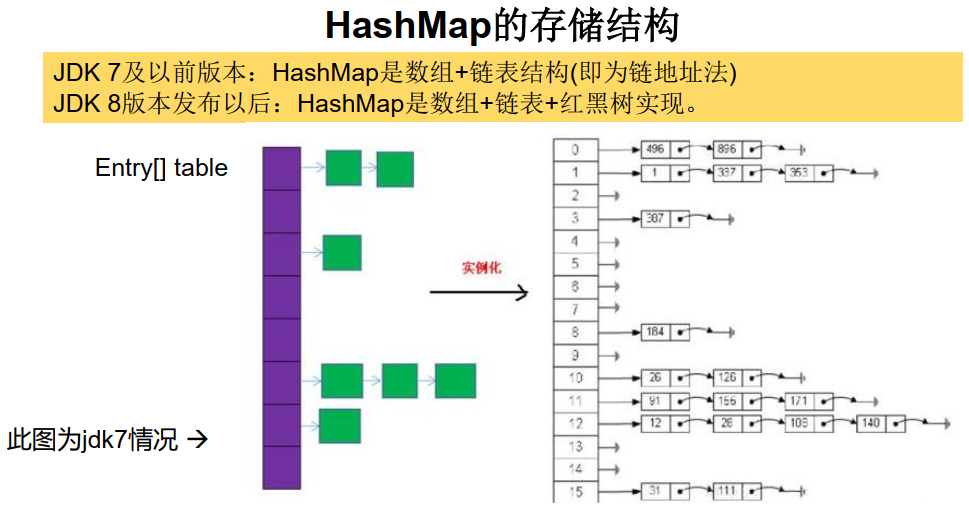
jdk8 相较于 jdk7 在底层实现方面的不同:
1、new HashMap():底层没有创建一个长度为16的数组,jdk 8底层的数组是:Node[],而非Entry[]
2、首次调用 put() 方法时,底层创建长度为16的数组
3、jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。
4、形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
5、当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。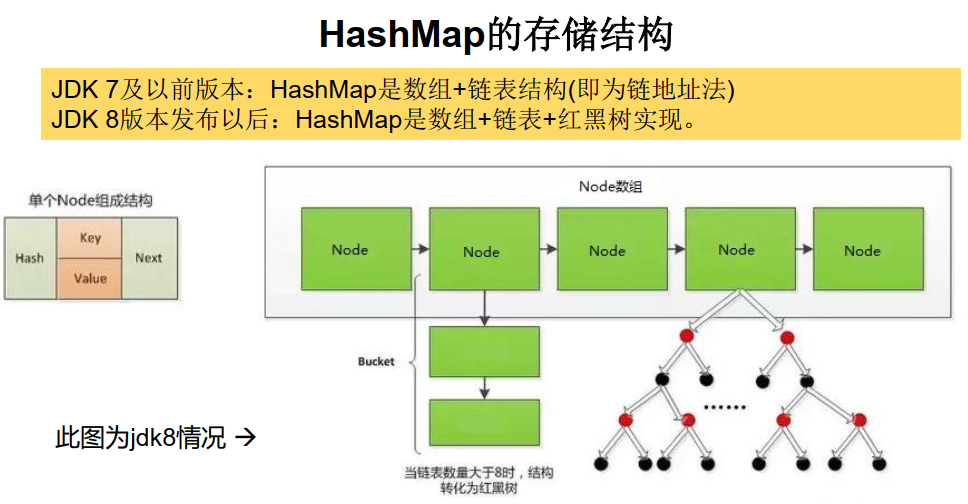
HashMap中的重要常量:
- DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
- DEFAULT_LOAD_FACTOR:HashMap的默认负载因子:0.75
- threshold:扩容的临界值 = 容量负载因子:16 0.75 => 12
- TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
- MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64

LinkedHashMap
LinkedHashMap 介绍
- LinkedHashMap 是 HashMap 的子类
- 在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序
- 与LinkedHashSet类似, LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致

TreeMap
TreeMap 存储 Key-Value 对时, 需要根据 key-value 对进行排序。
TreeMap 可以保证所有的 Key-Value 对处于有序状态。
TreeSet底层使用红黑树结构存储数据。
TreeMap 对 Key 排序:
- 自然排序: TreeMap 的所有的 Key 必须实现 Comparable接口,重写
compareTo()方法,而且所有的 Key 必须是同一个类的对象。 - 定制排序:创建 TreeMap 时传入一个 Comparator对象,该对象需要重写
compare()方法,负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现 Comparable 接口。 - TreeMap判断两个key相等的标准:两个key通过
compareTo()方法或者compare()方法返回0。
示例代码
public class TreeMapTest {// 向TreeMap中添加key-value,要求key必须是由同一个类创建的对象// 因为要按照key进行排序:自然排序 、定制排序// 自然排序@Testpublic void test1() {TreeMap map = new TreeMap();Person p1 = new Person("Tom", 36);Person p2 = new Person("Jerry", 44);Person p3 = new Person("Jack", 22);Person p4 = new Person("Rose", 18);map.put(p1, 99);map.put(p2, 77);map.put(p3, 56);map.put(p4, 88);Set set = map.entrySet();Iterator iterator = set.iterator();while (iterator.hasNext()) {Map.Entry entry = (Map.Entry) iterator.next();System.out.println(entry.getKey() + "::" + entry.getValue());}}// 定制排序@Testpublic void test2() {TreeMap map = new TreeMap(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if (o1 instanceof Person && o2 instanceof Person) {Person p1 = (Person) o1;Person p2 = (Person) o2;return Integer.compare(p1.getAge(), p2.getAge());}throw new RuntimeException("输入的类型不匹配");}});Person p1 = new Person("Tom", 36);Person p2 = new Person("Jerry", 44);Person p3 = new Person("Jack", 22);Person p4 = new Person("Rose", 18);map.put(p1, 99);map.put(p2, 77);map.put(p3, 56);map.put(p4, 88);Set set = map.entrySet();Iterator iterator = set.iterator();while (iterator.hasNext()) {Map.Entry entry = (Map.Entry) iterator.next();System.out.println(entry.getKey() + "::" + entry.getValue());}}}
Properties
Properties 类是 Hashtable 的子类,该对象用于处理属性文件。
- 由于属性文件里的 key、 value 都是字符串类型,所以 Properties 里的 key 和 value 都是字符串类型
- 存取数据时,建议使用
setProperty(String key,String value)方法和getProperty(String key)方法
添加之前,为了避免中文乱码,需要在IDEA设置里面修改字符集: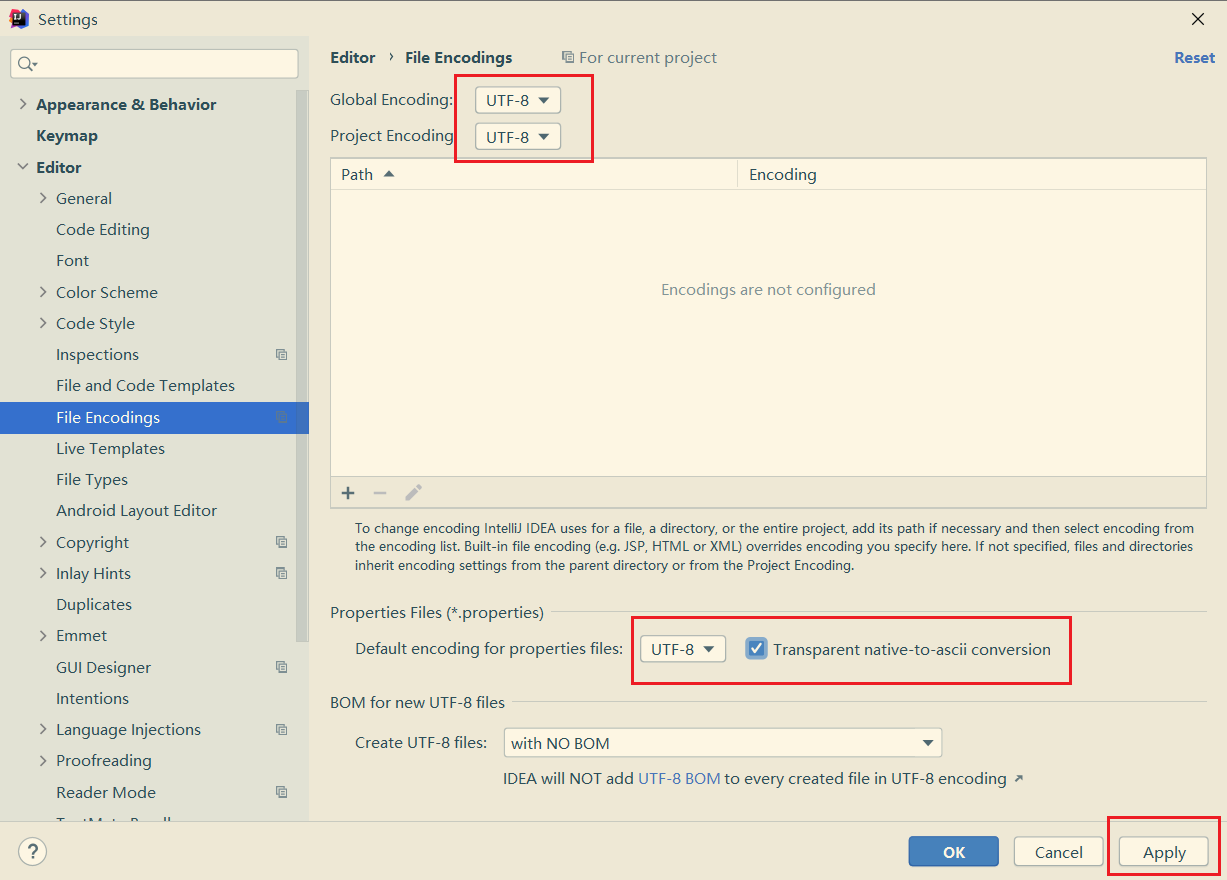
示例代码:
public class PropertiesTest {//Properties:常用来处理配置文件。key和value都是String类型public static void main(String[] args) {FileInputStream fis = null;try {Properties props = new Properties();fis = new FileInputStream("Collection_Map/src/jdbc.properties");props.load(fis);//加载流对应的文件String username = props.getProperty("username");String password = props.getProperty("password");System.out.println("username = " + username + ", password = " + password);} catch (Exception e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}}
其中properties文件:
username=汤姆password=123456
Collections 工具类
Collections 是一个操作 Set、 List 和 Map 等集合的工具类。
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法。
排序操作(均为static方法)
reverse(List): 反转 List 中元素的顺序shuffle(List): 对 List 集合元素进行随机排序sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序sort(List, Comparator): 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序swap(List, int, int): 将指定 list 集合中的 i 处元素和 j 处元素进行交换
查找、替换
Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素Object max(Collection``,``Comparator): 根据 Comparator 指定的顺序,返回给定集合中的最大元素Object min(Collection)Object min(Collection``,``Comparator)int frequency(Collecti``on``, ``Object``): 返回指定集合中指定元素的出现次数void copy(List dest,List src):将src中的内容复制到dest中boolean replaceAll(List list``, ``Object oldVal``, ``Object newVal): 使用新值替换List 对象的所有旧值
同步控制(解决多线程并发访问集合时候的线程安全问题)
synchronizedCollection(Collection<T> c)synchronizedList(List<T> list)synchronizedMap(Map<K,V> m)synchronizedSet(Set<T> s)
Enumeration 接口是 Iterator 迭代器的 “古老版本”
示例代码
@Testpublic void test1() {List list = new ArrayList();list.add(123);list.add(43);list.add(765);list.add(765);list.add(765);list.add(-97);list.add(0);System.out.println(list);// 返回指定集合中指定元素的出现次数int frequency = Collections.frequency(list, 765);System.out.println(frequency);// 对 List 集合元素进行随机排序Collections.shuffle(list);System.out.println(list);// 反转 List 中元素的顺序Collections.reverse(list);System.out.println(list);// 根据元素的自然顺序对指定 List 集合元素按升序排序Collections.sort(list);System.out.println(list);// 将指定 list 集合中的 i 处元素和 j 处元素进行交换Collections.swap(list, 1, 2);System.out.println(list);// 根据元素的自然顺序,返回给定集合中的最小元素Comparable min = Collections.min(list);System.out.println(min);}
示例代码
@Testpublic void test2() {List list = new ArrayList();list.add(123);list.add(43);list.add(765);list.add(-97);list.add(0);//报异常:IndexOutOfBoundsException("Source does not fit in dest")// List dest = new ArrayList();// Collections.copy(dest,list);//正确的:List<Object> dest = Arrays.asList(new Object[list.size()]);System.out.println(dest.size());Collections.copy(dest, list);System.out.println(dest);/*Collections类中提供了多个synchronizedXxx()方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题*///返回的list1即为线程安全的ListList list1 = Collections.synchronizedList(list);}
示例代码
@Testpublic void test1() {StringTokenizer stringTokenizer = new StringTokenizer("a-b*c-d-e-g", "-");while (stringTokenizer.hasMoreElements()) {Object obj = stringTokenizer.nextElement();System.out.println(obj);}}
控制台输出:

若有收获,就点个赞吧
0 人点赞
