在MySQL 中,只有一种 Join 算法,就是大名鼎鼎的 Nested Loop Join,他没有其他很多数据库所提供的 Hash Join,也没有 Sort Merge Join。
Nested-Loop
Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
驱动表的概念是指多表关联查询时,第一个被处理的表,使用此表的记录去关联其他表。驱动表的确定很关键,会直接影响多表连接的关联顺序,也决定了后续关联时的查询性能。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。
1.Simple Nested-Loop Join
简单来说嵌套循环连接算法就是一个双层for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,当执行select * from user tb1 left join level tb2 on tb1.id=tb2.user_id时,我们会按类似下面代码的思路进行数据匹配:
for (user : user表){for (level : level表){if (user.id == level.id).....}}
如图所示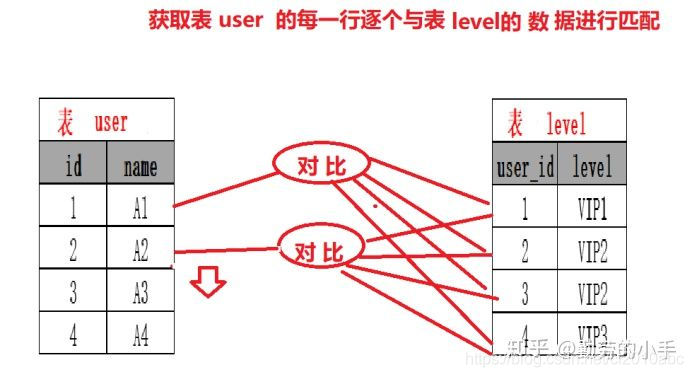
Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
当然mysql 肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join 优化算法,在执行join 查询时mysql 会根据情况选择 后面的两种优join优化算法的一种进行join查询。
2.Index Nested-Loop Join
ndex Nested-Loop Join其优化的思路 主要是为了减少内层表数据的匹配次数, 简单来说Index Nested-Loop Join 就是通过外层表匹配条件 直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较, 这样极大的减少了对内层表的匹配次数,从原来的匹配次数=外层表行数 内层表行数,变成了 外层表的行数 内层表索引的高度,极大的提升了 join的性能。
如SQL:select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
当level 表的 user_id 为索引的时候执行过程会如下图: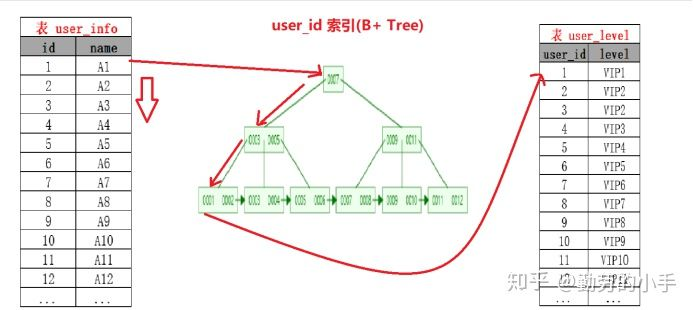
注意:使用Index Nested-Loop Join 算法的前提是匹配的字段必须建立了索引。
3.Block Nested-Loop Join
Block Nested-Loop Join 其优化思路是减少外层表的循环次数,Block Nested-Loop Join 通过一次性缓存多条数据,把参与查询的列缓存到join buffer 里,,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了外层循环的次数,当我们不使用Index Nested-Loop Join的时候,默认使用的是Block Nested-Loop Join。
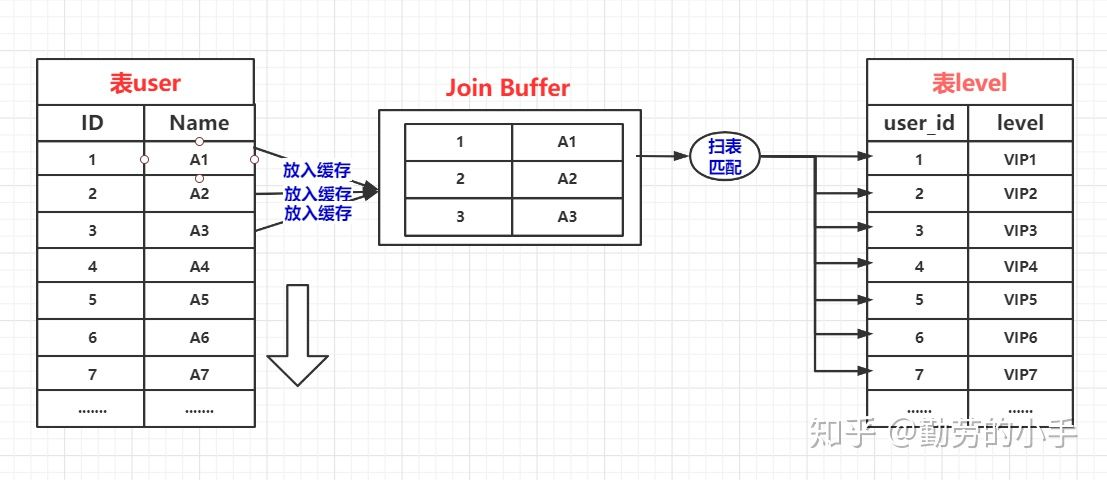
Hash Join
在mysql 8.0以后,加入了hash join.
hash join 也是利用了 join buffe。 他会把连接表读入到join buffer,创建一个hash表,优化连接表的读取速度。

若有收获,就点个赞吧
0 人点赞
