介绍
你是一个人,所以你可以做很多事情。你可以通过看和听来感知你周围的世界。你可以通过说话和打手势进行交流。你可以四处移动,探索你周围的环境。你可以理解和推理抽象概念,如笑话、文化等。而且,你可以从你的经历中学习。这些都是一种能力,我认为这些能力都是来源于我们的学习。
人类所说的学习,是指人去了解之前没有接触到的知识,使知识由未知变为已知的过程。机器学习,就是把这个过程中的主体由人换为计算机。
| Human ability | Name of AI Research Field |
|---|---|
| Seeing | Computer vision |
| Talking | Speech synthesis |
| Listening | Speech recognition |
| Understanding language | Natural Language Processing |
| Reasoning | Automated Reasoning |
| Consciousness | Philosophy / Cognitive Science |
| Walking / moving around | Robotics |
| Learning | Machine Learning |
发展历程
基础
机器学习是一个综合了很多学科的交叉学科,根据应用的场景也有简单和复杂的分别。简单一些的需要利用到统计学、概率学,复杂的则需要用到心理学、生物学、基础物理等。
应用
数据挖掘、人工智能、机器视觉等。
需求
所有机器学习算法首先需要一件事:数据。 没有数据,就没有什么可学的。 同样,人类也无法没有数据学习。当学习新技能时,“数据”来自观察周围的世界。所以当大数据时代来临,机器学习、人工智能的发展越来越快。
- 在之前,人类根据设想进行模型的搭建。
- 现在,人们可以使用大量的数据进行训练来生成目标模型,不必在初期就提出一个很精准的模型。
基本流程
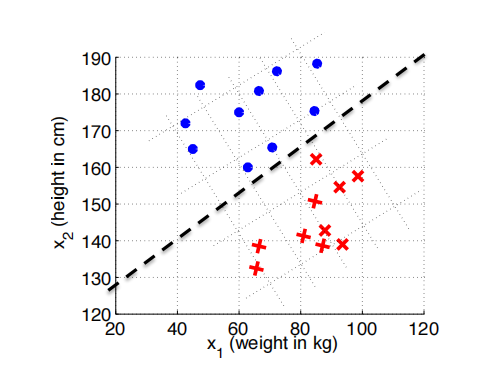
我们有一些训练数据,数据可以有很多的维度,以及一个 Label,即我们人为给数据打的标签。
比如根据一组已知只包含汽车和摩托车的数据。
| 车顶 | Label(是汽车/摩托车) |
|---|---|
| 有 | 汽车 |
| 有 | 汽车 |
| 有 | 汽车 |
| 有 | 汽车 |
| 无 | 摩托车 |
| 无 | 摩托车 |
| 无 | 摩托车 |
| 无 | 摩托车 |
简单的模型
决策树桩模型(0-1 模型)、回归分析、随机森林、贝叶斯等。
决策树桩模型 - Decision Stump
决策树桩是一种特殊的线性分割模型,特点是通过一个特征进行二元分割,例如上面提到的汽车摩托车。
%3E0%2C%20f(x)%3Dx_1-t%5C%5C%0A0%2C%20%26if%5C%20f(x)%3C0%2C%20f(x)%3Dx_1-t%0A%5Cend%7Bcases%7D%0A#card=math&code=%5Chat%20y%0A%5Cbegin%7Bcases%7D%0A1%2C%26if%5C%20f%28x%29%3E0%2C%20f%28x%29%3Dx_1-t%5C%5C%0A0%2C%20%26if%5C%20f%28x%29%3C0%2C%20f%28x%29%3Dx_1-t%0A%5Cend%7Bcases%7D%0A&id=zpJKo)

判别函数模型(感知机)- Discriminant Function(Perceptron)
%3D%5Csum%7Bi-1%7D%5Ed%20%CF%89_ix_i-t%0A#card=math&code=f%28x%29%3D%5Csum%7Bi-1%7D%5Ed%20%CF%89_ix_i-t%0A&id=JuFqT)
- d:所有特征
- ω:特征的权重
%3D%CF%89_1x_1%2B%CF%89_2x_2-t%3D0%0A#card=math&code=f%28x%29%3D%CF%89_1x_1%2B%CF%89_2x_2-t%3D0%0A&id=d2bxY)
%3D-%5Ccfrac%7B%CF%89_1%7D%7B%CF%89_2%7D%20x_1%20%2B%20%5Ccfrac%7Bt%7D%7B%CF%89_2%7D%3Dmx_1%2Bc%0A#card=math&code=f%28x%29%3D-%5Ccfrac%7B%CF%89_1%7D%7B%CF%89_2%7D%20x_1%20%2B%20%5Ccfrac%7Bt%7D%7B%CF%89_2%7D%3Dmx_1%2Bc%0A&id=JMBiG)
m 为梯度,c 为 y 轴截距。
可以通过数据样本来训练出一个一次函数模型,通过函数模型把二维坐标系中的点分开。
支持向量机 - SVM
介绍

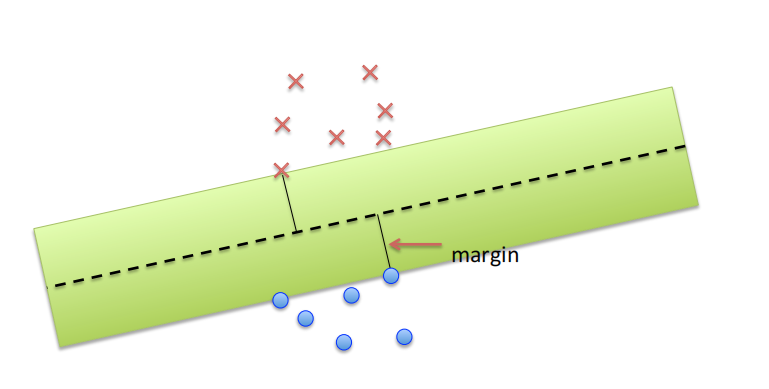
寻找最佳平面
对于SVM,存在一个分类面,两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。

决策树模型
网球问题

信息熵(Entropy)
信息熵的概念用来描述信源的不确定度。
%3D-%5Csum%7Bx%20%5Cin%20X%7D%20p(x)logp(x)%0A#card=math&code=H%28X%29%3D-%5Csum%7Bx%20%5Cin%20X%7D%20p%28x%29logp%28x%29%0A&id=gh9et)
- 熵越小=越小的不确定性=越多的信息
简单的学习算法
分类,聚类
- 在分类中,对于目标数据库中存在哪些类是知道的,要做的就是将每一条记录分别属于哪一类标记出来。聚类分析是研究如何在没有训练的条件下把样本划分为若干类。
- 聚类需要解决的问题是将已给定的若干无标记的模式聚集起来使之成为有意义的聚类,聚类是在预先不知道目标数据库到底有多少类的情况下,希望将所有的记录组成不同的类或者说聚类,并且使得在这种分类情况下,以某种度量(例如:距离)为标准的相似性,在同一聚类之间最小化,而在不同聚类之间最大化。
有监督学习
- 有监督机器学习的核心是分类。
- 对具有概念标记(分类)的训练样本进行学习,以尽可能对训练样本集外的数据进行标记(分类)预测。有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用在新的数据上,映射为输出结果。再经过这样的过程后,模型就有了预知能力。
- 有监督的工作是选择分类器和确定权值
- 包括所有的回归算法分类算法,比如线性回归、决策树等;
无监督学习
- 无监督机器学习的核心是聚类
- 对没有概念标记(分类)的训练样本进行学习,以发现训练样本集中的结构性知识。无监督相比于有监督,没有训练的过程,而是直接拿数据进行建模分析,意味着这些都是要通过机器学习自行学习探索。
- 无监督的工作是密度估计(寻找描述数据统计值),这意味着无监督算法只要知道如何计算相似度就可以开始工作
- 包括所有的聚类算法,比如K-Means、PCA、 GMM、SOM等。
训练方法
数据分批次
- 一组数据,随机分为 3 个训练集和 1 个验证集。
- 再重新分配继续进行训练。
- 可以有效降低欠拟合和过拟合。
迭代
%3Dax%2Bb%0A#card=math&code=f%28x%29%3Dax%2Bb%0A&id=zVnaP)

若有收获,就点个赞吧
0 人点赞
