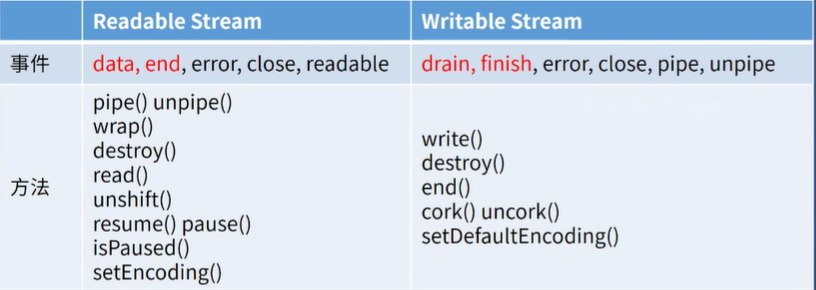
stream 流
例子1
const fs = require('fs')const stream = fs.createWriteStream('./big_file.txt')for (let i = 0; i < 1000000; i++) {stream.write(`这是第${i}行内容\n`)}stream.end()console.log('done')
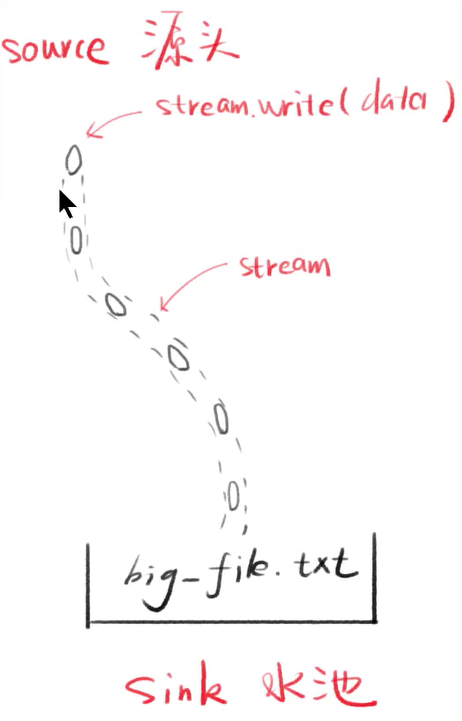
- stream是水流,但默认没有水
- stream.write可以让水流中有水(数据)
- 每次写的小数据就做chunk(块)
- 产生的数据的一端叫做source(源头)
- 得到数据的一端叫sink(水池)
例子2
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request', (request, response) => {fs.readFile('./big_file.txt', (error, data) => {if (err) throw errresponse.end(data)console.log('done')})})server.listen(8888)
- 用任务管理器看看Node.js内存占用大概130mb
例子3
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request', (request, response) => {const stream =fs.createReadStream('./big_file.txt')stream.pipe(response)stream.on('end', () => console.log('done'))})server.listen(8888)console.log('8888')
- 查看Node.js 内存占用,基本不会高于30Mb
- 文件stream和response stream通过管道相连接
管道
两个流可以用一个管道相连
stream1的末尾连接上stream2的开端
只要stream1有数据,就会流到stream2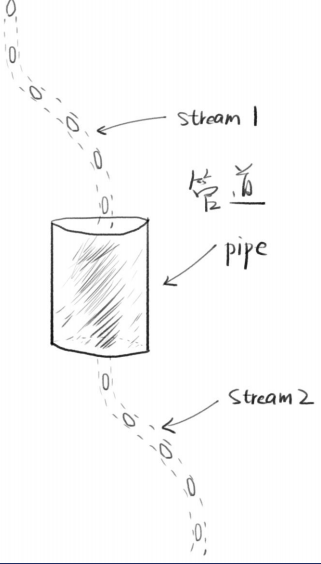
stream1.pipe(stream2)
a.pipe(b).pipe(c)
等价于a.pipe(b)b.pipe(c)
管道可以通过事件实现,一般不用这个,用pipe更简单
//stream1 一有数据就塞给stream2stream1.on('data',(chunk)=>{stream2.write(chunk)})//stream1停了,就停掉stream2stream1.on('end',()=>{stream2.end()})
Stream对象的原型链
s = fs.createReadStream(path)s的对象层级为
- 自身属性(由fs.ReadStream构造)
- 原型:stream.Readable.prototype
- 二级原型:stream.Stream.prototype
- 三级原型:events.EventEmitter.prototype
- 四级原型:Object.prototype
- Stream对象都继承了EventEmitter
drain(面试会问
当写入缓冲区变为空时触发。可以用来做上传节流。
stream1.on('data',(chunk)=>{stream2.write(chunk)stream2.on('drain',()=>{go on write})})
finish
调用 [stream.end()](http://nodejs.cn/api/stream.html#stream_writable_end_chunk_encoding_callback) 且缓冲数据都已传给底层系统之后触发。
const writer = getWritableStreamSomehow();for (let i = 0; i < 100; i++) {writer.write(`写入 #${i}!\n`);}writer.on('finish', () => {console.error('写入已完成');});writer.end('写入结尾\n');
corkwritable.cork() 方法强制把所有写入的数据都缓冲到内存中。 当调用 [stream.uncork()](http://nodejs.cn/s/6wPsns) 或[stream.end()](http://nodejs.cn/s/hYaxt3) 时,缓冲的数据才会被输出。
当写入大量小块数据到流时,内部缓冲可能失效,从而导致性能下降, writable.cork() 主要用于避免这种情况。 对于这种情况,实现了 writable._writev() 的流可以用更优的方式对写入的数据进行缓冲。
Stream分类
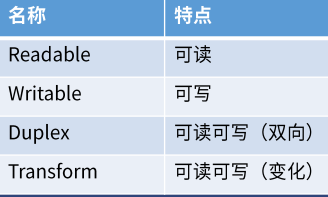
Readable
静止态paused和流动态flowing
- 默认处于paused态
- 添加data事件监听,它就变为flowing态
- 删掉data事件监听,它就变为paused态
- pause()可以将它变为paused
-
Writable
drain流干了事件
表示可以加点水了
- 我们调用sream.write(chunk)的时候,可能会得到false
- false的意思是你写的太快了,数据积压了
- 这时候就不能再write了,要监听drain
- 等drain事件触发,才能继续write
```javascript
// Write the data to the supplied writable stream one million times.
// Be attentive to back-pressure.
const fs = require(‘fs’)
function writeOneMillionTimes(writer, data) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
} while (i > 0 && ok); if (i > 0) {i--;if (i === 0) {// Last time!writer.write(data);} else {// See if we should continue, or wait.// Don't pass the callback, because we're not done yet.ok = writer.write(data);}
} } }// Had to stop early!// Write some more once it drains.writer.once('drain', ()=>{console.log('干涸了')write()});
const writer=fs.createWriteStream(‘./big_file.txt’) writeOneMillionTimes(writer,’hello world’)
<a name="FioFK"></a># 自定义Steam<a name="7uiu6"></a>## 创建一个Writable Stream```javascriptconst {Writable} = require('stream')const outStream = new Writable({write(chunk, encoding, callback) {console.log(chunk.toString())callback()}})process.stdin.pipe(outStream)
创建一个Readable Stream
const {Readable} = require("stream");const inStream = new Readable();inStream.push("ABCDEFGHIJKLM");inStream.push("NOPQRSTUVWXYZ");inStream.push(null); // No more datainStream.pipe(process.stdout);
const {Readable} = require("stream");const inStream = new Readable({read(size) {const char = this.push(String.fromCharCode(this.currentCharCode++));console.log(`推了${char}`)if (this.currentCharCode > 90) {this.push(null);}}})inStream.currentCharCode = 65inStream.pipe(process.stdout)//这次数据是按需供给的,调用read才会给一次数据
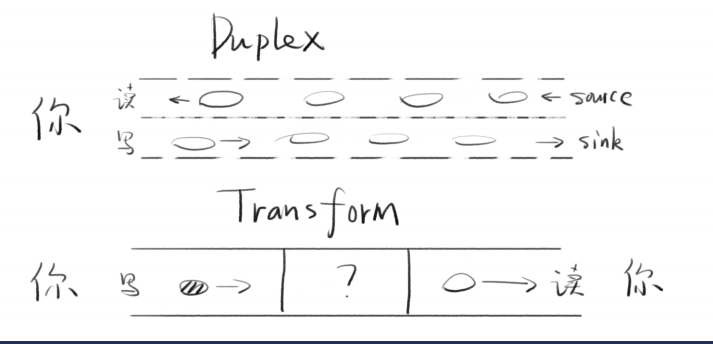
Duplex Stream
const { Duplex } = require("stream");const inoutStream = new Duplex({write(chunk, encoding, callback) {console.log(chunk.toString());callback();},read(size) {this.push(String.fromCharCode(this.currentCharCode++));if (this.currentCharCode > 90) {this.push(null);}}});inoutStream.currentCharCode = 65;process.stdin.pipe(inoutStream).pipe(process.stdout);
Transform Stream
const { Transform } = require("stream");const upperCaseTr = new Transform({transform(chunk, encoding, callback) {this.push(chunk.toString().toUpperCase());callback();}});process.stdin.pipe(upperCaseTr).pipe(process.stdout);
内置的Transform Stream
gzip压缩
const fs = require("fs");const zlib = require("zlib");const file = process.argv[2];fs.createReadStream(file).pipe(zlib.createGzip()).pipe(fs.createWriteStream(file + ".gz"));
记录写了几次 …
const fs = require("fs");const zlib = require("zlib");const file = process.argv[2];fs.createReadStream(file).pipe(zlib.createGzip()).on("data", () => process.stdout.write(".")).pipe(fs.createWriteStream(file + ".zz")).on("finish", () => console.log("Done"))
const fs = require("fs");const zlib = require("zlib");const file = process.argv[2];const {Transform} = require("stream");const reportProgress = new Transform({transform(chunk, encoding, callback) {process.stdout.write(".");callback(null, chunk);}});fs.createReadStream(file).pipe(zlib.createGzip()).pipe(reportProgress).pipe(fs.createWriteStream(file + ".zz")).on("finish", () => console.log("Done"));
const fs = require("fs");const zlib = require("zlib");const crypto = require("crypto");// ..fs.createReadStream(file).pipe(crypto.createCipher("aes192", "123456")).pipe(zlib.createGzip()).pipe(reportProgress).pipe(fs.createWriteStream(file + ".zz")).on("finish", () => console.log("Done"));//先加密再压缩
Node.js中的Stream
 #
#
数据流中的积压问题

若有收获,就点个赞吧
0 人点赞
