注释
什么是注释?
- 注释就是就是对代码的解释说明,注释的内容不参与程序的运行,只起到提示作用
为什么要注释?
- 增强代码的可读性
如何使用注释?
代码注释分单行和多行注释
1、单行注释用#号,可以写在代码的正上方或者正后方
# 单行注释print("hello world") # 单行注释
2、多行注释可以用三对双引号或单引号”””””” ‘’’’’ ```python ‘’’ 多行注释 ‘’’
“”” 多行注释 多行注释 多行注释
“”” ```
代码注释的原则
- 1、不用全部加注释,只需要为自己觉得重要或不好理解的部分加注释即可
- 2、注释可以用中文或英文,但不要用拼音
- 3、单行注释#号与注释文本之间一定要有一个空格,跟在代码后面需要两个空格再写#

变量
- 什么是变量?
- 量指的是事物的状态,变指的是事物的状态是可以变化的,变量指的是可以将事物的状态给记录下来,并且记录的结果是可以被改变的
- 变量是一种存取内存的机制
- 为什么要有变量?
- 让计算机能够像人一样记住事物的状态,并且状态是可以发生变化的
详细地说:
程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
变量的定义与使用
定义
name = "mike" # 名字age = 18 # 年龄height = 1.8 # 身高weight = 80 # 体重
三大组成部分
- 变量名:用来找值
- 赋值符号: 将变量值的内存地址绑定给变量名
- 变量值:就是我们存储的数据,或者说记录的事物的状态
引用
print(age) # 打印
变量名
- 命名的大前提:变量名的命名应该见名知意 ```python age = 18 # 年龄
level = 18 # 等级
count = 18 # 数量
<a name="a3d10465"></a>### 命名规范- 只能由字母、数字、下划线组成- 不能以数字开头,下划线建议不要开头因为有特殊含义- 不能用python的关键字,会有冲突```python# 例:level_of_age = 18_=19 # 可以这么用,但不建议print(_)
Python关键字
'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del','elif', 'else','except', 'exec', 'finally', 'for', 'from', 'global','if', 'import', 'in', 'is', 'lambda','not', 'or', 'pass', 'print','raise', 'return', 'try', 'while', 'with', 'yield'

定义变量名不好的方式
- 变量名为中文、拼音
- 变量名词不达意
命名风格
# 1. 驼峰体大驼峰 # 所有单词首字母大写其余字母小写组成的命名LevelOfAge = 18NumberOfStudents = 80小驼峰 # 第一单词首字母小写其余单词首字母大写组成的命名levelOfAge = 18numberOfStudents = 80# 2.纯小写加下划线 # 单词与单词之间下划线隔开level_of_age = 18number_of_students = 80"""python推荐使用下划线"""
变量值
1、变量三要素
name='jason'print(name) # value:变量的值print(id(name)) # id: 反映的是变量的内存地址,内存地址不同id肯定不同print(type(name)) # type:数据类型 <class 'str'>age = 18salary = 3.3res = age + 1print(res)# =============》类型print(type(age))print(type(salary))# =============》id:就是值在内存中的身份证号,id反映的就是内存print(id(age))print(id(salary))
is 与 = =
is :判断的是左右两个值身份id是否相等== :判断的是左右两个值是否相等
注意:
(1)如果id相同,意味着tye和value必定相同
x = 1000y = xprint(x is y)
(2)value相同type肯定相同,但id可能不同
C:\Users\oldboy>python3Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSCv.1927 64 bit (AMD64)] on win32Type "help", "copyright", "credits" or "license" for moreinformation.>>> x=1000>>> y=1000>>> id(x)x2577369562032>>> id(y)2577369562096>>>>>> x is yFalse>>> x == yTrue>>>
2、小整数池** [-5,256]
从python解释器启动那一刻开始,就会在内存中事先申请好一系列内存空间存放好常用的整数
x=111111111111111y=111111111111111print(id(x))print(id(y))

3、垃圾回收机制
内存管理:gc 机制
垃圾:当一个变量值被绑定的变量名的个数为0时,该变量值无法被访问到,称之为垃圾(用来回收没有关联任何变量名的值)
Python的垃圾回收机制,其实高级的语言都有自己的垃圾回收机制简称GC,python当中主要通过三种方式解决垃圾回收的方式:
引用计数:核心原理
分代回收:提升效率
标记清除:循环引用导致内存泄露问题???
- 引用计数:如果有新的引用指向对象,对象引用计数就加一,引用被销毁时,对象引用计数减一,当用户的引用计数为0时,该内存被释放

# 引用计数增加x = 100 # 100的引用计数为1y = x # 100的引用计数为2z = x # 100的引用计数为3# 引用计数减少del x # 解除变量名x与值100的绑定关系,100的引用计数变为2print(y)del y # 100的引用计数变为1print(z)z = 12345 # # 100的引用计数变为0print(z)
- 标记清除:首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)
首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效)。将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象 - 分代回收:垃圾回收器会更频繁的处理新对象。一个新的对象即是你的程序刚刚创建的,而一个老的对象则是经过了几个时间周期之后仍然存在的对象。Python会在当一个对象从零代移动到一代,或是从一代移动到二代的过程中提升(promote)这个对象。
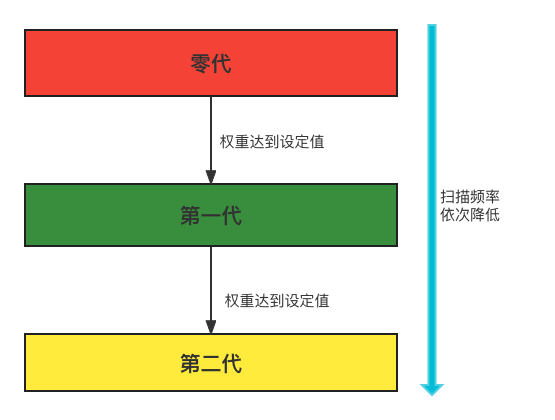
》》》其实垃圾回收机制内部是Cpython 解释器GIL全局锁的底层原理。
常量
主要用于记录一些不变的状态
常量即指不变的量,如pai 3.141592653…, 或在程序运行过程中不会改变的量
在python中没有真正意义上的常量 我们墨守成规的将全大写的变量看成是常量
AGE = 18print(AGE)HOST = '127.0.0.1' # 一般情况下在配置文件中使用较多在其他编程语言中是存在真正意义上的常量 定义了就无法修改const age int = 18 # 定义常量age = 19 # 不支持修改

若有收获,就点个赞吧
0 人点赞
