命令说明
[表示可选] {表示参数}
--- 创建数据库create database [if not exists] db_hive [location '/hdfspath'];--- 查看数据库show databases;--- 查看数据库基础信息desc database db_hive;--- 查看数据库详细信息desc database extended db_hive;--- 切换数据库use db_hive;--- 为数据库添加自定义属性,自定义属性可以通过desc database extended查看alert database db_hive set dbproperties(creat_time='20200303');--- 删除数据库,有数据时,无法删除drop database [if exists] db_hive;--- 级联删除,删除表和数据drop database [if exists] db_hive cascade;--- 创建表,external表示外部表,内部表创建的时候,会把数据拷贝到HDFS中,而外部表不拷贝。--- 删除内部表的时候,元数据与表数据都会被删除,而删除外部表的时候,只删除元数据,表数据不会被删除CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(column_name data_type [COMMENT column_comment], ...)][COMMENT table_comment][PARTITIONED BY (column_name data_type [COMMENT column_comment], ...)] --- 分区 HDFS 会更具分区字段,创建子文件夹[CLUSTERED BY (column_name, column_name ...) ---分桶 表中数据按照分桶键进行哈希取值,然后散列到不同的文件中,[SORTED BY (column_name [ASC|DESC], ...)] INTO number_buckets BUCKETS][ROW FORMAT row_format] --- row format delimited fields terminated by "分割符"[SORTED AS file_format] --- 指定文件存储类型[LOCATION hdfs_path][LIKE] ---复制表结构,但是不复制数据row_format = DELIMITED [FIELDS TERMINATED BY {char}] [COLLECTION ITEMS TERMINATED BY {char}] [MAP KEY TERMINATED BY {char}] [LINES TERMINATED BY {char}]| SERDE {serde_name} WITH SERDEPROPERTIES (property_name=property_value, ...)]file_format = SEQUENCEFILE --- hadoop_kv 序列文件 | TEXTFILE ---文本文件 | RCFILE ---列式存储文件 | PARQUETFILE --- ---列式存储文件--- 读取数据load data inpath <hdfs_path> into table table_name [partition(area="CQ",dt="2019-2-1")]load data local inpath <local_path> into table table_name [partition(area="CQ",dt="2019-2-1")]--- 读取数据到分桶表--- 设置mapreduce.job.redueces=-1 表示让hadoop 自己觉得reduce数量,适配分桶表的桶数insert into ft_table select * from source_table
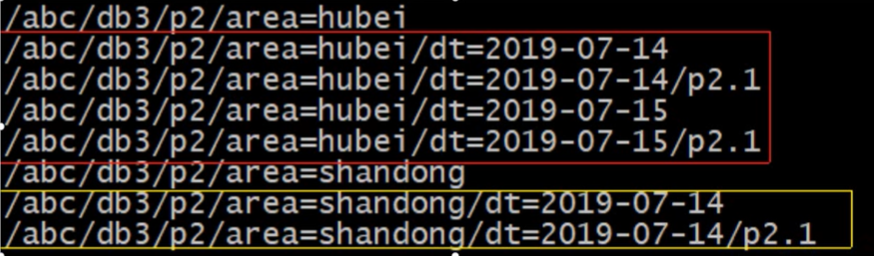
分区后的HDFS 目录
serde 序列化,反序列化
创建表时可以用来切分列,用户可以使用预定义的serde也可以自定义serde
例如要拆分如下数据格式
id=123,name=张三
CREATE TABLE tbl_user (id int,name string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerde' with serdeproperties ("input.regex" = "id=(.*),name=(.*)")sorted as textfile
分桶抽样查询
--- x 指定从哪个桶开始抽取, y 必须是桶的倍数或因子,hive 根据y的大小,决定抽样比例抽比例公式为 桶数/y--- 例如桶数为4 TABLESAMPLE(BUCKET 1 OUT OF 2)表示从第一个桶开始取数据,取4/2个桶的数据,所取的桶为 x, [x+y] ...+y 即桶1 与桶1+2=3--- x 必须 <=ySELECT * FROM table_name TABLESAMPLE(BUCKET x OUT OF y)

若有收获,就点个赞吧
0 人点赞
