集合简介
1)说明
(1)Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质。
(2)对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本,分别位于以下两个包
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable
2)案例实操
(1)Scala不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象进行修改。
(2)可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。
object TestList {def main(args: Array[String]): Unit = {//不可变Listval immutableList: List[Int] = List(1, 2, 3, 4, 5)//对不可变List进行修改,在头部添加一个元素0val newImmutableList: List[Int] = 0 +: immutableListprintln(immutableList)println(newImmutableList)//可变Listval mutableList: ListBuffer[Int] = ListBuffer(1, 2, 3, 4, 5)//对可变List进行修改,在头部添加一个元素0val newMutableList: ListBuffer[Int] = 0 +=: mutableListprintln(mutableList)println(newMutableList)}}
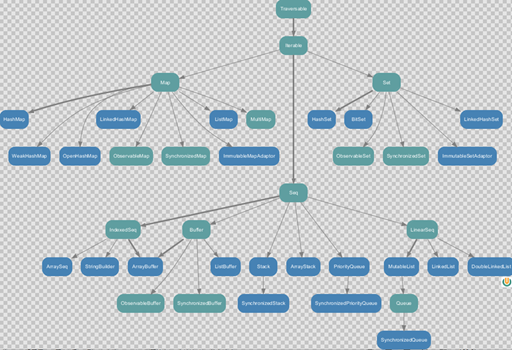
不可变集合继承图

1)Set、Map是Java中也有的集合
2)Seq是Java没有的,我们发现List归属到Seq了,因此这里的List就和Java不是同一个概念了
3)我们前面的for循环有一个 1 to 3,就是IndexedSeq下的Vector
4)String也是属于IndexeSeq
5)我们发现经典的数据结构比如Queue和Stack被归属到LinerSeq
6)大家注意Scala中的Map体系有一个SortedMap,说明Scala的Map可以支持排序
7)IndexSeq和LinearSeq的区别:
(1)IndexSeq是通过索引来查找和定位,因此速度快,比如String就是一个索引集合,通过索引即可定位
(2)LineaSeq是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
可变集合继承图
集合符号总结:
带+与带-的区别:
带+是添加元素
带-是删除元素(不可变一般没有-号)一个+/-与两个+/-的区别:
一个+/-是添加/删除单个元素
两个+/-是添加/删除指定集合所有元素冒号在前与冒号在后以及不带冒号的区别:
冒号在前是将元素添加在集合最末尾
不带冒号是将元素添加在集合最末尾
冒号在后是将元素添加在集合最前面带=与不带=的区别
带=是修改集合本身(不可变一般没有=号)
不带=是生成一个新集合,原集合没有改变有序集合:【数组、list、队列】
update/updated方法修改元素
可变的不需要update/updated方法,直接通过角标修改数据
不可变的需要update/updated方法才能修改数据
update:修改集合本身
updated:生成一个新的集合,原集合没有改变-
无序集合:【map、set】
set
-
map
不可变map,不可删除元素
- 可变map,可删除
集合分类
数组
不可变数组
_ 不可变数组创建:
1、通过new创建: new Array元素类型
2、通过apply方法: Array元素类型
添加数据
删除数据
获取数据: 数组名(角标)
修改数据: 数组名(角标) = 值
package tcode.chapter07object $01_ImmutableArray {def main(args: Array[String]): Unit = {//1、通过new创建: new Array[元素类型](数组的长度)val arr = new Array[String](10)println(arr.toList)//2、通过apply方法: Array[元素类型](初始元素,...)val arr2 = Array[Int](10,3,7,9,20)println(arr2.toList)//3、添加元素//添加单个元素val arr3 = arr2.+:(40)println(arr3.toList)println(arr2.toList)println( arr2.eq(arr3) )val arr4 = arr2.:+(50)println(arr4.toList)//添加一个整个集合val arr5 = arr2.++(Array(100,200,300))println(arr5.toList)val arr6 = arr2.++:(Array(600,700,800))println(arr6.toList)//2、删除//3、获取元素println(arr2(0))//4、修改元素arr2(0) = 100println(arr2.toList)arr2.update(1,30) // 只改变原集合,不会生成新集合println(arr2.toList)//不可变转可变val arr10 = arr2.toBufferprintln(arr10)}}
可变数组
可变数组的创建:
1、通过new: new ArrayBuffer元素类型
2、通过apply方法: ArrayBuffer元素类型
package tcode.chapter07import scala.collection.mutable.ArrayBufferobject $02_MutbaleArray {def main(args: Array[String]): Unit = {//1、通过new: new ArrayBuffer[元素类型]()val arr = new ArrayBuffer[Int]()//2、通过apply方法: ArrayBuffer[元素类型](初始元素,...)val arr2 = ArrayBuffer[Int](10,4,5,2,9)println(arr.toList)println(arr2.toList)//添加元素val arr3 = arr2.+:(10)println(arr3.toList)println(arr2.toList)val arr4 = arr2.:+(30)println(arr4.toList)arr2.+=(60)println(arr2.toList)arr2.+=:(90)println(arr2.toList)//添加一个集合val arr5 = arr2.++( Array(100,200) )println(arr5.toList)val arr6 = arr2.++:( Array(100,200) )println(arr6.toList)arr2.++=( Array(500,600) )println(arr2.toList)arr2.++=:( Array(500,600) )println(arr2.toList)//删除val arr7 = arr2.-( 500 )println(arr7.toList)arr2.-=( 600 )println(arr2.toList)val arr8 = arr2.-- ( Array(500,600,600))println(arr8.toList)arr2.--=( Array(500,600,2,9) )println(arr2.toList)arr2.remove(0,3)//获取元素println(arr2(0))//修改元素arr2(0)=900println(arr2.toList)arr2.+=(500)arr2.+=(500)arr2.+=(600)println(arr2.toList)//可变转不可变val arr10 = arr2.toArrayprintln(arr10.toList)//多维数组的创建val arr11 = Array.ofDim[Int](3,4)println(arr11.length)println(arr11(0).length)}}
Seq集合(List)
不可变list
创建:<br /> 1、apply方法: List[元素类型](初始元素,。。。)<br /> 2、初始元素 :: 初始元素 :: ... :: 不可变List/Nil(空的不可变list)<br />添加位置:看元素处于::的位置<br /> :: 最右边必须是不可变List或者是Nil<br /> Nil是空集合,Nil与List的关系类似Null与String的关系<br /> ** Nil一般可以用于给不可变List变量赋予初始值, Nil给不可变List变量赋予初始值的时候**必须指定变量类型<br /> <br /> :: 与 ::: 的区别:<br /> ::是添加单个元素<br /> ::: 是添加一整个集合(array、list等)所有元素
list转array
println(list10.toBuffer)
package tcode.chapter07object $03_ImmutableList {def main(args: Array[String]): Unit = {//1、apply方法: List[元素类型](初始元素,。。。)val list = List[Int](10,3,6,7,2)var list2:List[Int] = Nillist2= list//2、初始元素 :: 初始元素 :: ... :: List/Nilval list3 = 10 :: 5 :: 6 :: Nilprintln(list3)//3、添加元素val list4 = list3.+:(20)println(list4)val list5 = list3.:+(40)println(list5)val list6 = 40 :: list3println(list6)val list7 = list3.++(Array(10,20,30))println(list7)val list8 = list3.++:(Array(10,2030))println(list8)val list9 = List(50,60,70) ::: list3println(list9)val list10 = List(50,60,70) :: list3println(list10) // 两个冒号的结果是List(List(10,20,30),10,5,6)//删除:无//获取元素println(list9(0))//修改元素//list9(0)=100,没办法通过这种方式获取值//println(list9)val list10 = list9.updated(0,100)// 获取给新list,0:索引,100:值println(list9)println(list10)//List转Arrayprintln(list10.toBuffer)}}
可变list
package tcode.chapter07import scala.collection.mutable.ListBufferobject $04_MutableList {/*** 创建可变List: ListBuffer[元素类型](初始元素,...)*/def main(args: Array[String]): Unit = {val list = ListBuffer[Int](10,20,3,5,9)println(list)//添加元素val list2 = list.+:(30)println(list2)val list3 = list.:+(50)println(list3)list.+=(100)println(list)list.+=:(300)println(list)val list4 = list.++(Array(100,200,300))println(list4)val list5 = list.++:(Array(100,200,300))println(list5)list.++=(List(11,22,33))println(list)list.++=:(List(44,55,66))println(list)//删除元素val list6 = list.-( 55 )println(list6)list.-=(66)println(list)val list7 = list.--(List(44,300,11))println(list7)list.--=(List(10,20,22,33))println(list)//获取元素println(list(0))//修改元素list(0)=100println(list)//可变转不可变println(list.toList)}}
set集合
不可变set
package tcode.chapter07object $05_ImmutableSet {//Set的特性: 无序,不重复//def main(args: Array[String]): Unit = {//创建Set: Set[元素类型](初始元素,...)val set = Set[Int](10,2,2,5,1,9)println(set)//添加元素val set2 = set.+(20)println(set2)val set3 = set.++(List(100,94,20,99))println(set3)val set4 = set.++:(List(100,94,20,99))println(set4)//删除元素val set5 = set.-(10)println(set5)val set6 = set.--(List(5,1,9))println(set6)//获取元素,只能通过遍历获得// println(set6(10)) // 返回true/falsefor(e<- set){println(e)}//修改元素,无法修改}}
可变set
package tcode.chapter07import scala.collection.mutableobject $06_MutableSet {def main(args: Array[String]): Unit = {//创建: mutable.Set[元素类型](初始元素,。。。。)val set = mutable.Set[Int](10,3,7,2,9,20)println(set)//添加val set2 = set.+(100)println(set2)set.+=(100)println(set)val set3 = set.++(List(200,87,65))println(set3)val set4 = set.++:(List(200,87,65))println(set4)set.++=(List(200,87,65))println(set)//删除val set5 = set.-(2)println(set5)set.-=(100)println(set)val set6 = set.--(List(2,3,7))println(set6)set.--=(List(2,3,7))println(set)//修改元素//set.update(200,false),这个update执行的是新增操作,无法修改元素,true则添加元素//println(set)}}
元祖:
/*
元组创建:
1、通过()方式创建: (初始元素,…)
2、通过->方式创建[只能在二元元组使用]: K->V
scala中二元元祖对应KV键值对
元组中最多只能存放22个元素
元组一旦定义就不可变[元素不可变,长度不可变]
元组获取值: 元组名._角标 [元组的角标从1开始] 如 : r._1
*/
package tcode.chapter07object $07_Tuple {def main(args: Array[String]): Unit = {//元组创建:val t1 = ("zhangsan",20,"shenzhen")val t2 = "zhagnsan"->20println(t1)println(t2)println(t1._1)val logs = List("1 zhangsan 20 shenzhen","2 wagnwu 30 beijing","3 zhaoliu 44 shenzhen")val persons = for(e<- logs) yield {val arr = e.split(" ")(arr(0),arr(1),arr(2).toInt,arr(3))}// persons: list((1,zhangsan,20,shenzhen),(。。。),(。。。))for(e<- persons){println(e._3)}val list2 = List[Region](new Region("宝安区",new School("宝安中学",new Clazz("大数据班",new Student("zhangsan",20)))),new Region("宝安区",new School("宝安中学",new Clazz("大数据班",new Student("wangwu",20)))),new Region("宝安区",new School("宝安中学",new Clazz("大数据班",new Student("zhaoliu",20)))))val ts = List[(String,(String,(String,(String,Int))))](("宝安区",("宝安中学",("大数据班",("zhangsan",20)))),("宝安区",("宝安中学",("大数据班",("wangwu",20)))),("宝安区",("宝安中学",("大数据班",("zhaoliu",20)))))for(element<- ts){println( element._2._2._2._1 )}}class Region(name:String,school:School)class School(name:String,clazz:Clazz)class Clazz(name:String,stu:Student)class Student(name:String,age:Int)}
map集合
不可变map
* 创建方式:<br /> * Map[K的类型,V的类型]( (K,V) ,..)<br /> * Map[K的类型,V的类型]( K->V ,..)<br /> * Option: 提醒外部当前返回结果有可能为空(防止空指针异常),需要进行处理<br /> * Some: 代表有值,值封装在Some中<br /> * None: 代表为空<br /> * Map取值通过getOrElse(key,默认值)[代表key如果在map中存在则取出对应的value值,如果不存在则返回默认值]
package tcode.chapter07object $08_ImmutableMap {/*** 创建方式:* Map[K的类型,V的类型]( (K,V) ,..)* Map[K的类型,V的类型]( K->V ,..)* Option: 提醒外部当前返回结果有可能为空,需要进行处理* Some: 代表有值,值封装在Some中* None: 代表为空* Map取值通过getOrElse(key,默认值)[代表key如果在map中存在则取出对应的value值,如果不存在则返回默认值]**/def main(args: Array[String]): Unit = {val map = Map[String,Int]("aa"->1,"bb"->2,("cc",3) )//添加元素val map2 = map.+( "dd"->4 )println(map2)val map3 = map.++( List( ("ee",10),"oo"->20,"tt"->30,"ff"->20 ) )println(map3)val map4 = map.++:( List( ("ee",10),"oo"->20,"tt"->30,"ff"->20 ) )println(map4)//获取元素// map4.get("ee").get,可以通过get方法获取,但是返回类型是option类型,需要再通过get从some中获得,但是没什么意义println(map4.getOrElse("ee",0))//修改元素//map4("ee")=200 ,不可变map无法通过这种方式修改// updated方法:如果存在key则修改元素,如果不存在Key则不修改元素val map5 = map4.updated("ee",100)println(map4)// println(map5)// 删除元素:无}}
可变map
package tcode.chapter07import scala.collection.mutableobject $09_MutableMap {def main(args: Array[String]): Unit = {val map = mutable.Map[String,Int]("aa"->10,("bb",20),"tt"->50)//添加元素val map2 = map.+( "pp"->60 )println(map2)map.+=( "uu"->33 )println(map)val map4 = map.++( List( "rr"->10,"ll"->20 ))println(map4)val map5 = map.++:(List( "rr"->10,"ll"->20 ))println(map5)map.++=(List( "rr"->10,"ll"->20 ))println(map)map.put("zz",300)println(map)//删除,只需要删除key即可val map6 = map.-("uu")println(map6)map.-=("uu")println(map)val map7 = map.--(List("ll","aa","rr"))println(map7)map.--=(List("ll","aa","rr"))println(map)map.remove("zz")println(map)//获取元素println(map.getOrElse("bb", 200))//修改元素map("bb")=200println(map)map.update("bb",400)println(map)}}
队列
可变队列
package tcode.chapter07import scala.collection.immutable.Queueobject $10_ImmutableQueue {def main(args: Array[String]): Unit = {//创建: Queue[元素类型](初始元素,...)val q1 = Queue[Int](1,5,7,9,2)println(q1)//添加元素val q2 = q1.+:( 20 )println(q2)val q3 = q1.:+( 30 )println(q3)val q4 = q1.++(List(100,400,200))println(q4)val a5 = q1.++:(List(100,400,200))println(a5)val q6 = q1.enqueue(1000)println(q6)//删除,dequeue返回值为元祖(A, Queue[A])A为出列的元素,Queue[A]为剩余元素val r = q1.dequeueprintln(r._1)println(r._2)//获取元素println(q1(0))//修改元素//q1(0)=100 // 不可变无法通过下标修改//println(q1)val q9 = q1.updated(0,100)println(q9)}}
不可变队列
package tcode.chapter07import scala.collection.mutableobject $11_MutableQueue {def main(args: Array[String]): Unit = {//创建val queue = mutable.Queue[Int](10,2,5,8,20)//添加元素val queue2 = queue.+:( 30 )println(queue2)val queue3 = queue.:+(40)println(queue3)queue.+=(50)queue.+=:(70)println(queue)val queue4 = queue.++(List(100,300,200))val queue5 = queue.++:(List(100,300,200))queue.++=(List(100,300,200))println(queue4)println(queue5)println(queue)queue.enqueue(55,44,333)println(queue)//删除,dequeue返回值类型:元祖println(queue.dequeue())//获取元素println(queue(0))//修改元素queue(1)=222println(queue)queue.update(0,111)println(queue)}}
par并行集合
/*
并行集合: scala集合默认是单线程操作,如果想要多线程操作集合元素,需要使用并行集合
普通集合转并行集合: 集合名.par
/
package tcode.chapter07object $12_Par {def main(args: Array[String]): Unit = {val list = List(1,2,5,8,20)list.foreach(x=>{println(s"${Thread.currentThread().getName} --- ${x}")} )println("-"*100)val list2 = list.parlist2.foreach(x=>{println(s"${Thread.currentThread().getName} --- ${x}")} )}}
集合常用函数
基本属性操作
package tcode.chapter07object $13_CollectionField {def main(args: Array[String]): Unit = {val list = List(1,5,3,7,10,2)//是否包含某个元素println(list.contains(100))//是否为空println(list.isEmpty)//获取集合长度println(list.length)println(list.size)//将集合转成字符串println(list)println(list.mkString("#"))}}
衍生集合
package tcode.chapter07object $14_CollectionPar {def main(args: Array[String]): Unit = {val list = List(10,2,5,6,3,90,8,4,10)//去重 !!!println(list.distinct)//删除前多少个元素,保留剩余其他元素println(list.drop(3))//删除后多少个元素,保留剩余其他元素println(list.dropRight(3))//获取第一个元素 !!!println(list.head)//获取最后一个元素 !!!println(list.last)//获取除开最后一个元素的所有元素println(list.init)//反转 *****println(list.reverse)//获取子集合println(list.slice(0, 3))//滑窗 !!!//size: 窗口的长度// 内部是元祖,外部是list:List((),(),())//step: 滑动长度println(list.sliding(4, 3).toList)//获取除开第一个元素的所有元素println(list.tail)//获取前多少个元素 !!!println(list.take(3))//获取后多少个元素println(list.takeRight(3))//交集val list2 = List(1,2,3,4,5)val list3 = List(4,5,6,7,8)println(list2.intersect(list3))//并集println(list2.union(list3))//差集[A差B的结果就是A中有B中没有的元素]println(list2.diff(list3))//拉链val list4 = List("aa","bb","cc","dd")val list5 = List(10,20,30)val list6 = list4.zip(list5)println(list6)//反拉链println(list6.unzip)//将元素与角标拉链println(list4.zipWithIndex)}}
集合初级函数
聚合
list.max
list.min
list.sum
list.maxby
list.minby
排序
list.sorted
list.reverse
list.sortBy
list.sortWith
package tcode.chapter07import scala.math.Orderingobject $15_CollectionLowFunction {def main(args: Array[String]): Unit = {val list = List(10,3,5,7,2,20)//获取最大值println(list.max)//获取最小值println(list.min)//求得总和println(list.sum)//根据指定字段获取最大值//maxBy(func: 集合元素类型 => B )//maxBy是根据函数的返回值进行排序之后取最大元素//后续会将集合每个元素当做参数传递给函数,maxBy中的函数是集合有多少元素就调用多少次val list2 = List[(String,Int,Int)](("zhangsan1",20,3000),("zhangsan4",16,4000),("zhangsan4",30,4000),("zhangsan2",15,2500),("zhangsan3",33,1500))val func = (x:(String,Int,Int)) => x._2println(list2.maxBy(func))//直接传递函数值println(list2.maxBy((x:(String,Int,Int)) => x._2))//省略函数参数类型println(list2.maxBy((x) => x._2))//函数参数只有一个,()可以省略println(list2.maxBy( x => x._2))// 使用_代替println(list2.maxBy( _._2))//根据指定字段获取最小值//minBy(func: 集合元素类型=>B )//minBy是根据函数的返回值排序之后取最小值//后续会将集合每个元素当做参数传递给函数,minBy中的函数是集合有多少元素就调用多少次println(list2.minBy(x => {x._3}))//排序//1、直接根据元素本身排序,默认升序【sorted】val list3 = list.sortedprintln(list3)//降序println(list3.reverse)println(list2.sorted)//2、根据指定字段排序[sortBy],默认升序 *****//sortBy(func: 集合元素类型 => B )//sortBy是根据函数的返回值进行排序//后续会将集合每个元素当做参数传递给函数val ordering = new Ordering[Int]{override def compare(x: Int, y: Int): Int = {if(x>y) -1else if(x==y) 0else 1}}println(list2.sortBy(x => {x._3 // 一定要在花括号内(之前因可省略而删除)打断点才能看到函数体的值})(ordering))//3、根据自己比较排序 sortWith// 升序: 第一个参数>第二个参数// 降序: 第一个参数<第二个参数println(list.sortWith((x, y) => {x > y}))}}
集合高阶函数
过滤: filter(func: 集合元素类型=>Boolean)
filter是针对每个元素操作,后续会将集合每个元素当做函数的参数值传入<br /> filter是集合有多少个元素就调用多少次<br /> filter保留是函数返回值为true的数据
映射: map(func: 集合元素类型=> B ),
其实就是:val func = 集合元素类型 => B , map(func)
map的应用场景: 一对一
map中的函数也是针对集合每个元素操作,后续会将集合每个元素当做函数的参数值传入
val B = A.map( ..) 此时B集合的长度=A集合的长度
map一般用于转换[值的转换、类型的转换]
一般用于抽出(集合)元素进行操作
压平: flatten
flatten是针对集合嵌套集合的场景,会将第二层集合去掉<br /> flatten的场景: 一对多
压平转换类型 flatMap(func: 集合元素类型 => 集合) = map + flatten
flatMap中的函数是针对集合每个元素进行操作,集合有多少个元素,函数就调用多少次<br /> flatMap的应用场景: 一对多<br /> flatMap与flatten的区别:<br /> flatMap是先对元素进行转换之后再压平,flatten是直接压平不转换
遍历 foreach(func: 集合元素类型 => B ):Unit : 遍历
foreach中的函数是针对集合每个元素操作<br /> foreach与map的区别:<br /> map有返回值,foreach是没有返回值
分组 groupBy(func: 集合元素类型=> K): 根据指定字段分组
groupBy里面的函数是针对集合每个元素进行操作,groupBy分组是根据函数的返回值进行分组<br /> groupBy的结果是Map[K,V] 【K就是函数的返回值,也就是分组的key,V是分组的key对应原集合中的所有元素】
聚合reduce\fold
reduce(func: (集合元素类型,集合元素类型)=>集合元素类型): 从左向右计算
reduce是对集合中所有元素进行聚合<br /> reduce函数第一个参数第一次计算的时候初始值 = 集合第一个元素,第N次计算的时候第一个参数的值 = 第N-1次的结果<br /> reduceRight(func: (集合元素类型,集合元素类型)=>集合元素类型): 从右向左计算<br /> reduceRight是对集合中所有元素进行聚合.<br /> reduceRight函数第二个参数第一次计算的时候初始值 = 集合最后一个元素,第N次计算的时候第二个参数的值 = 第N-1次的结果
fold(初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型): 从左向右计算
fold是对集合中所有元素进行聚合<br /> fold函数第一个参数第一次计算的时候初始值 = 指定默认值,第N次计算的时候第一个参数的值 = 第N-1次的结果<br /> foldRight(初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型): 从右向左计算<br /> foldRight是对集合中所有元素进行聚合<br /> foldRight函数第二个参数第一次计算的时候初始值 = 指定默认值,第N次计算的时候第二个参数的值 = 第N-1次的结果
package tcode.chapter07object $16_CollectionHightFunction {def main(args: Array[String]): Unit = {val list = List(10,2,5,6,7,9)//过滤: filter(func: 集合元素类型=>Boolean)// filter是针对每个元素操作,后续会将集合每个元素当做函数的参数值传入// filter是集合有多少个元素就调用多少次// filter保留是函数返回值为true的数据val list2 = list.filter(x=> {println(s"x=${x}")x%2==0})println(list2)//映射: map(func: 集合元素类型=> B )//map的应用场景: 一对一//map中的函数也是针对集合每个元素操作,后续会将集合每个元素当做函数的参数值传入//val B = A.map( ..) 此时B集合的长度=A集合的长度//map一般用于转换[值的转换、类型的转换]val list3 = List("spark","hadoop","flume","kafka")val list4 = list3.map( x => x.length )println(list4)//压平: flatten//flatten是针对集合嵌套集合的场景,会将第二层集合去掉//flatten的场景: 一对多val list5 = List[List[Int]](List(1,2),List(4,5),List(7,8))val list6 = list5.flattenprintln(list6)val list7 = List[List[List[Int]]](List(List(1,2),List(5,6)),List(List(7,8),List(9,10)))val list8 = list7.flatten.flattenprintln(list8)val list9 = List("aa","cc")println(list9.flatten)//flatMap(func: 集合元素类型 => 集合) = map + flatten//flatMap中的函数是针对集合每个元素进行操作,集合有多少个元素,函数就调用多少次//flatMap的应用场景: 一对多//flatMap与flatten的区别:// flatMap是先对元素进行转换之后再压平,flatten是直接压平不转换val list10 = List("hadoop spark flume","kafka flink hello")// val list11 = list10.map(x=> x.split(" "))// val list12 = list11.flatten// println(list12)// 上面等价于:val list11 = list10.flatMap(x=>x.split(" "))println(list11)//结果:List(hadoop,spark,flume,kafka,flink,hello)//遍历:foreach(func: 集合元素类型 => B ):Unit : 遍历//foreach中的函数是针对集合每个元素操作//foreach与map的区别:// map有返回值,foreach是没有返回值list.foreach(x=>println(x))//groupBy(func: 集合元素类型=> K): 根据指定字段分组//groupBy里面的函数是针对集合每个元素进行操作,groupBy分组是根据函数的返回值进行分组//groupBy的结果是Map[K,V] 【K就是函数的返回值,也就是分组的key,V是分组的key对应原集合中的所有元素】val list13 = List( ("lisi","man","shenzhen"),("wangwu","woman","beijing"),("zhaoliu","man","beijing") )val map2 = list13.groupBy(x=> x._3)println(map2)//reduce//reduceRight//fold//foldRight//聚合//reduce(func: (集合元素类型,集合元素类型)=>集合元素类型): 从左向右计算//reduce是对集合中所有元素进行聚合//reduce函数第一个参数第一次计算的时候初始值 = 集合第一个元素,第N次计算的时候第一个参数的值 = 第N-1次的结果val result = list.reduce((agg,curr) => {println(s"agg=${agg} curr=${curr}")agg-curr})println(result)//reduceRight(func: (集合元素类型,集合元素类型)=>集合元素类型): 从右向左计算//reduceRight是对集合中所有元素进行聚合//reduceRight函数第二个参数第一次计算的时候初始值 = 集合最后一个元素,第N次计算的时候第二个参数的值 = 第N-1次的结果println("-"*100)val r1 = list.reduceRight((curr,agg)=>{println(s"agg=${agg} curr=${curr}")agg-curr})println(r1)//fold(初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型): 从左向右计算//fold是对集合中所有元素进行聚合//fold函数第一个参数第一次计算的时候初始值 = 指定默认值,第N次计算的时候第一个参数的值 = 第N-1次的结果println("*"*100)list.fold(100)((agg,curr)=>{println(s"agg=${agg} curr=${curr}")agg+curr})println("+"*100)//foldRight(初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型): 从右向左计算// foldRight是对集合中所有元素进行聚合//foldRight函数第二个参数第一次计算的时候初始值 = 指定默认值,第N次计算的时候第二个参数的值 = 第N-1次的结果list.foldRight(200)((curr,agg)=>{println(s"agg=${agg} curr=${curr}")agg+curr})}}

若有收获,就点个赞吧
0 人点赞
