模块安装
Window : 推荐Anaconda
Ubuntu : 解决一些依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
模块简介
维基百科简介: Wikipedia
Scrapy(/ˈskreɪpi/ SKRAY-pee[2]是一个用Python编写的自由且开源的网络爬虫框架。它在设计上的初衷是用于爬取网络数据,但也可用作使用API来提取数据,或作为生成目的的网络爬虫[3]。该框架目前由网络抓取的开发与服务公司Scrapinghub公司维护。
Scrapy项目围绕“蜘蛛”(spiders)建构,蜘蛛是提供一套指令的自包含的爬网程序(crawlers)。遵循其他如Django框架的一次且仅一次精神[4],允许开发者重用代码将便于构建和拓展大型的爬网项目。Scrapy也提供一个爬网shell,开发者可用它测试对网站的效果。[5]
使用Scrapy的知名公司和产品有:Lyst[6][7]、Parse.ly[8]、Sayone Technologies[9]、Sciences Po Medialab[10]、Data.gov.uk的世界政府数据网站[11]等。
Scrapy诞生于网络聚合和电子商务公司Mydeco,它由Mydeco和Insophia公司的员工开发和维护。2008年8月首次以BSD许可证公开发布,2015年6月发布有里程碑意义的1.0版本[12]。2011年,Scrapinghub成为新的官方维护者[13][14]。
运行流程
- 首先从爬虫获取初始的请求
- 将请求放入调度模块,然后获取下一个需要爬取的请求
- 调度模块返回下一个需要爬取的请求给引擎
- 引擎将请求发送给下载器,依次穿过所有的下载中间件
- 一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。
- 引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
- 爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
- 引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
- 该过程重复,直到调度程序不再有请求为止。
简单使用
创建项目
scrapy startproject dbtest dbtest2
dbtest2是子目录, dbtest是父目录
创建首个目录, 未指定父目录,则子父同名
scrapy startproject db
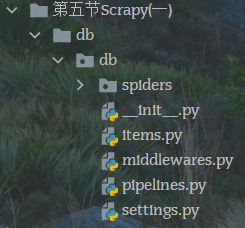
命令说明
scrapy <command> [options] [args]
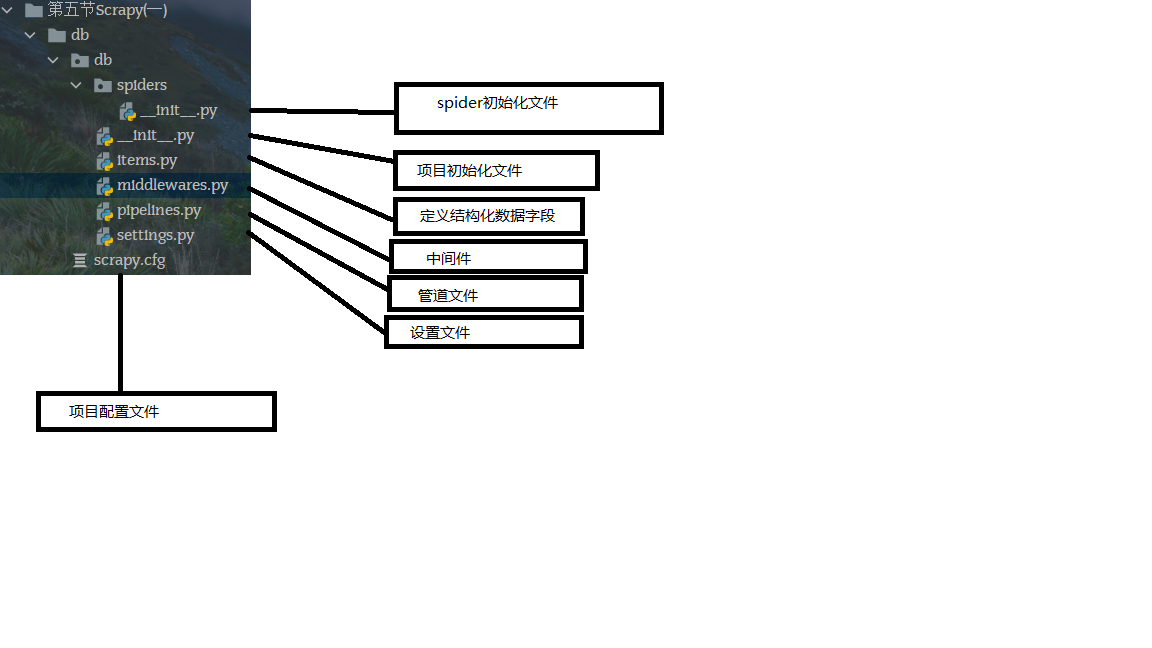
创建爬虫文件
注意事项:为了目录结构清晰,需要切换到指定文件夹再开始创建,下面是一个错误演示
创建命令:
从模板中创建爬虫文件
cd dbscrapy genspider db250 https://movie.douban.com

正确示范

运行爬虫文件
scrapy crawl db250
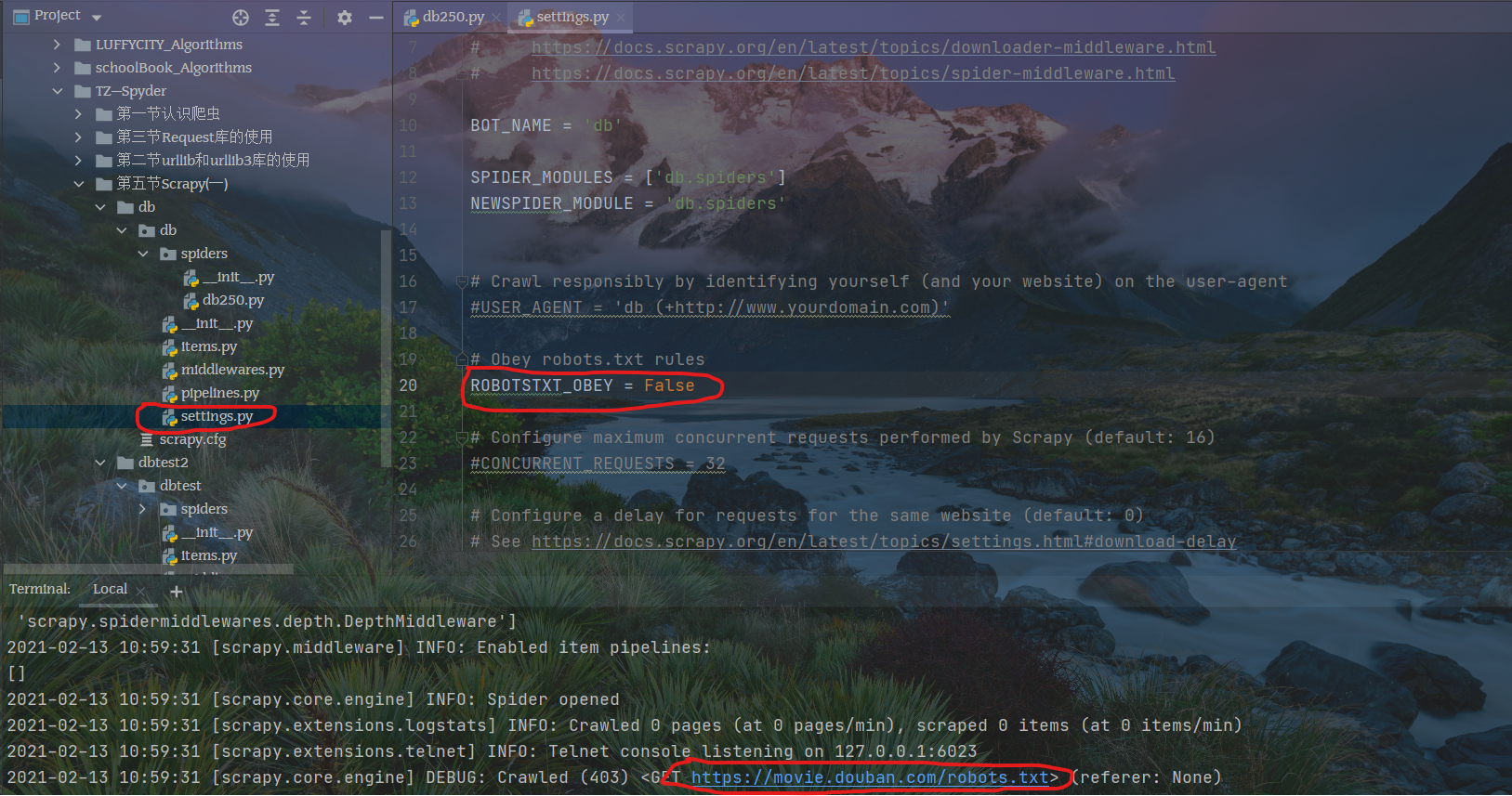
修改配置文件
修改robot.text设置,在项目的settings.py内,不遵循robot协议才能爬取数据
修改默认请求头,获取response响应数据
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63"
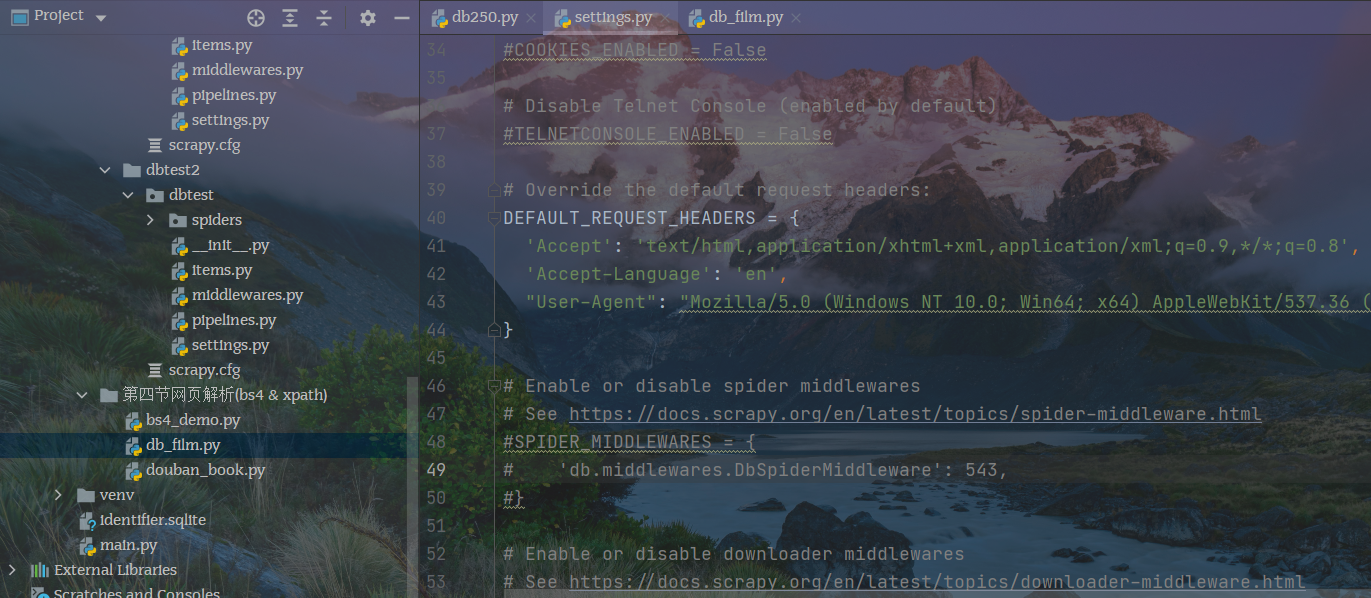
查看日志文件,状态码200表示请求已成功,请求所希望的响应头或数据体将随此响应返回

开始测试网页
开启测试:
scrapy shell https://movie.douban.com/top250
打印响应文件
response.text
解析指定源码块
response.xpath('//div[@class = "info"]')
检查长度
len(response.xpath('//div[@class = "info"]'))
解析电影名称
node_list = response.xpath('//div[@class="info"]')for node in node_list:film_name = node.xpath("./div/a/span/text()").extract()[0]print(film_name)
注意:为了抓取纯文字,需要在解析代码后面添加一个extract()方法

细节处理
json编码处理 不适用ASCⅡ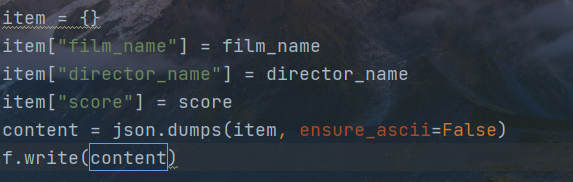
新建终端调试爬虫文件
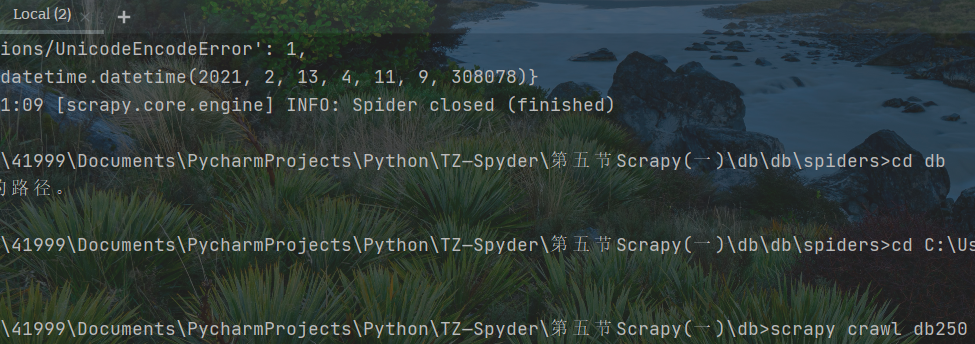
GBK编码报错

解决方案

解决输出文档不换行的问题

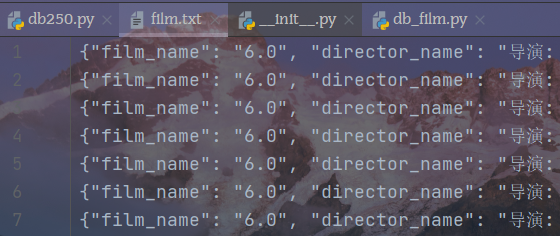
管道存储数据
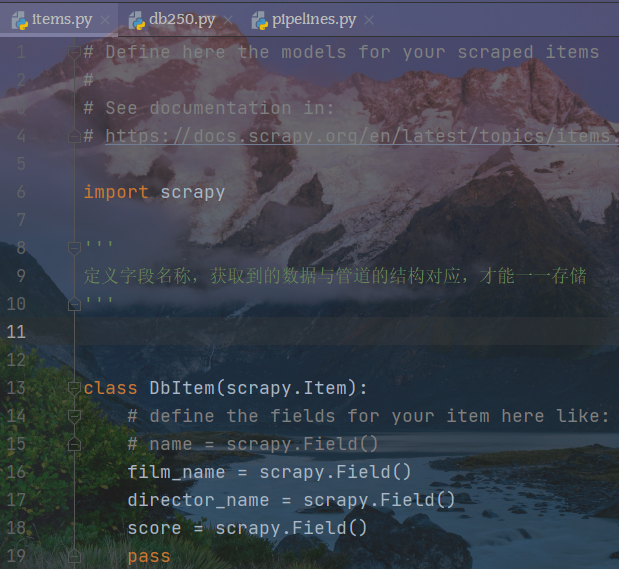
修改items.py
注意:管道结构和文本元素个数完全一致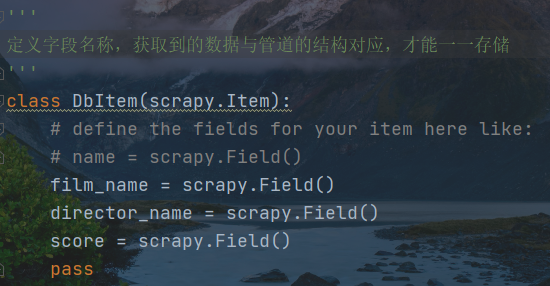
在爬虫文件(db250)中创建管道
注意:需要从items.py中导出DbItem
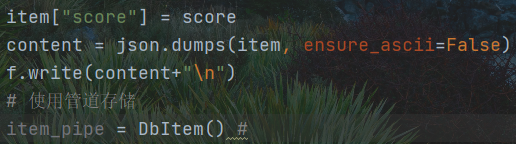
在爬虫文件中生成对应管道
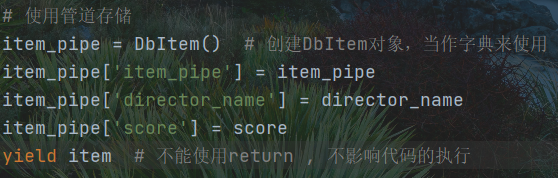
关于数据对应的问题
db250中的item_pipe, item必须和items.py中的item一一对应,尤其是键值对
代码:
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy'''定义字段名称,获取到的数据与管道的结构对应,才能一一存储'''class DbItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()film_name = scrapy.Field()director_name = scrapy.Field()score = scrapy.Field()pass
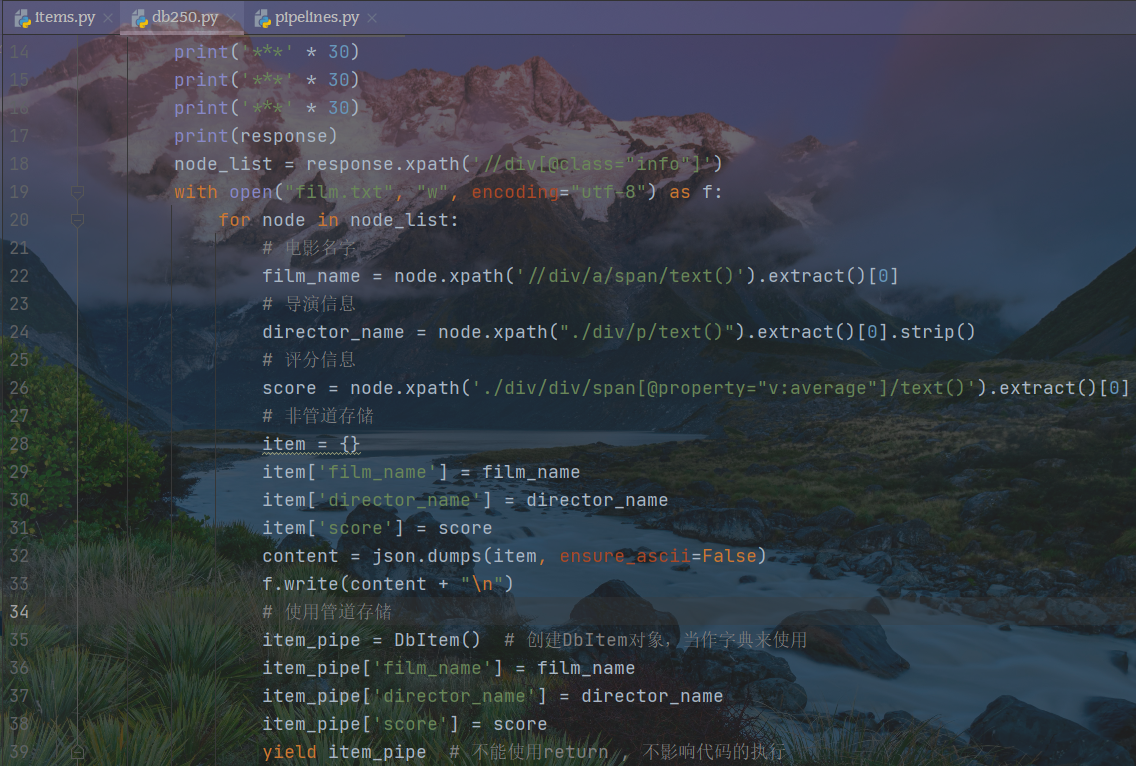
import jsonimport scrapyfrom ..items import DbItem # 是一个安全的字典class Db250Spider(scrapy.Spider): # 继承基础类name = 'db250' # 爬虫文件名字,必须存在且唯一# allowed_domains = ['https://moive.douban.com'] # 允许的域名 相当于防火墙, 可以不存在,可以访问任何网站start_urls = ['https://movie.douban.com/top250'] # 初始URL, 必须存在def parse(self, response): # 解析函数,处理响应数据print('***' * 30)print('***' * 30)print('***' * 30)print(response)node_list = response.xpath('//div[@class="info"]')with open("film.txt", "w", encoding="utf-8") as f:for node in node_list:# 电影名字film_name = node.xpath('//div/a/span/text()').extract()[0]# 导演信息director_name = node.xpath("./div/p/text()").extract()[0].strip()# 评分信息score = node.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]# 非管道存储item = {}item['film_name'] = film_nameitem['director_name'] = director_nameitem['score'] = scorecontent = json.dumps(item, ensure_ascii=False)f.write(content + "\n")# 使用管道存储item_pipe = DbItem() # 创建DbItem对象,当作字典来使用item_pipe['film_name'] = film_nameitem_pipe['director_name'] = director_nameitem_pipe['score'] = scoreyield item_pipe # 不能使用return , 不影响代码的执行
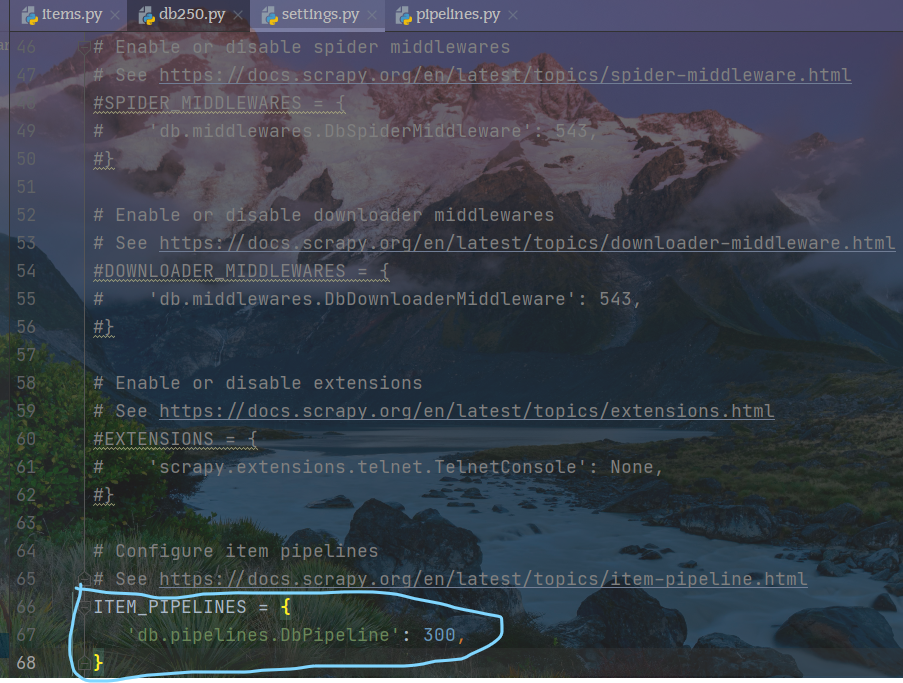
在settings.py中开启管道
发起多个页面的请求
避免被封IP地址,先获取两页
最后一个语句生成网页访问,提交网页给引擎,引擎拿到网页将做出访问,将响应数据传递给parse解析
主文件代码(db250)
import jsonimport scrapyfrom ..items import DbItem # 是一个安全的字典class Db250Spider(scrapy.Spider): # 继承基础类name = 'db250' # 爬虫文件名字,必须存在且唯一# allowed_domains = ['https://moive.douban.com'] # 允许的域名 相当于防火墙, 可以不存在,可以访问任何网站start_urls = ['https://movie.douban.com/top250'] # 初始URL, 必须存在page_num = 0def parse(self, response): # 解析函数,处理响应数据print('***' * 30)print('***' * 30)print('***' * 30)print(response)node_list = response.xpath('//div[@class="info"]')with open("film.txt", "w", encoding="utf-8") as f:for node in node_list:# 电影名字film_name = node.xpath('./div/a/span/text()').extract()[0]# 导演信息director_name = node.xpath("./div/p/text()").extract()[0].strip()# 评分信息score = node.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]# 非管道存储item = {}item['film_name'] = film_nameitem['director_name'] = director_nameitem['score'] = scorecontent = json.dumps(item, ensure_ascii=False)f.write(content + "\n")# 使用管道存储item_pipe = DbItem() # 创建DbItem对象,当作字典来使用item_pipe['film_name'] = film_nameitem_pipe['director_name'] = director_nameitem_pipe['score'] = scoreyield item_pipe # 不能使用return , 不影响代码的执行# 发起新一页的请求# 构造URLself.page_num += 1if self.page_num == 3:returnpage_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num*25)print(page_url)yield scrapy.Request(page_url)

若有收获,就点个赞吧
0 人点赞
