1. redis数据结构
1. 字典Dict
Dict概述
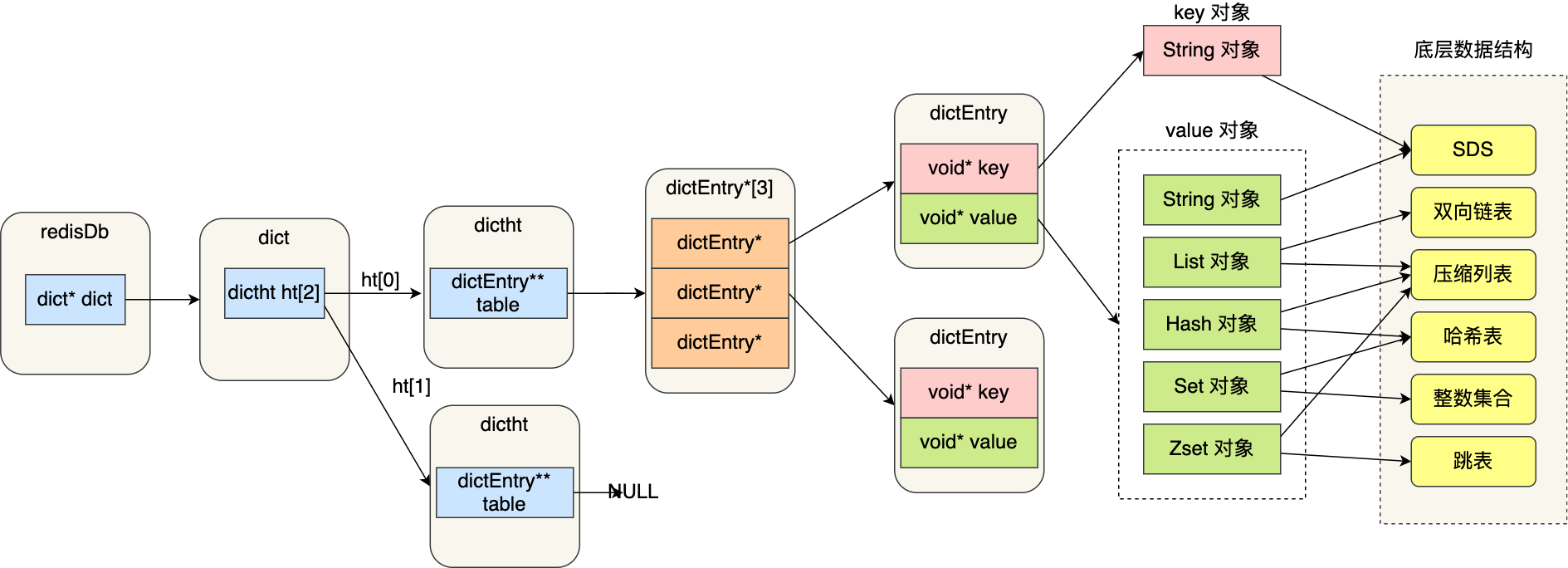
Redis是一个键值型(key-value)数据库,我们可以根据键值对进行增删改查,键值对的映射关系就是通过Dict结构来实现的,Dict分为3部分:字典(dict)、哈希表(dictht)、哈希结点(dictEntry)
typedef struct dict {dictType *type; // dict类型,内置不同的hash函数void *privdata; // 也是用于hash计算的私有数据dictht ht[2]; // 定义一个哈希表数组,容量为2,一个正常使用,一个rehash时使用long rehashidx; // 记录rehash的进度,-1表示未进行rehashint16_t pauserehash;// 1表示rehash暂停,0表示rehash在运行} dict;
typedef struct dictht {// 定义一个二级指针指向dictEntry结点,就相当于java中的dictEntry[] tabledictEntry **table; // 一个*表示指针指向dictEntry,第二个*表示这个dictEntry是个数组unsigned long size; // 哈希表数组长度unsigned long sizemask; // 掩码值 sizemask = size - 1, 用于取余计算unsigned long used; // 哈希表中已经插入的结点的个数} dictht;
typedef struct dictEntry {// void *代表无类型指针,可以指向任何数据void *key; // 键union {void *val;unit64_t u64;int64_t s64;double d;} v; // 值,类型为联合体中的一个struct dictEntry *next; // 指向洗衣歌结点} dictEntry;
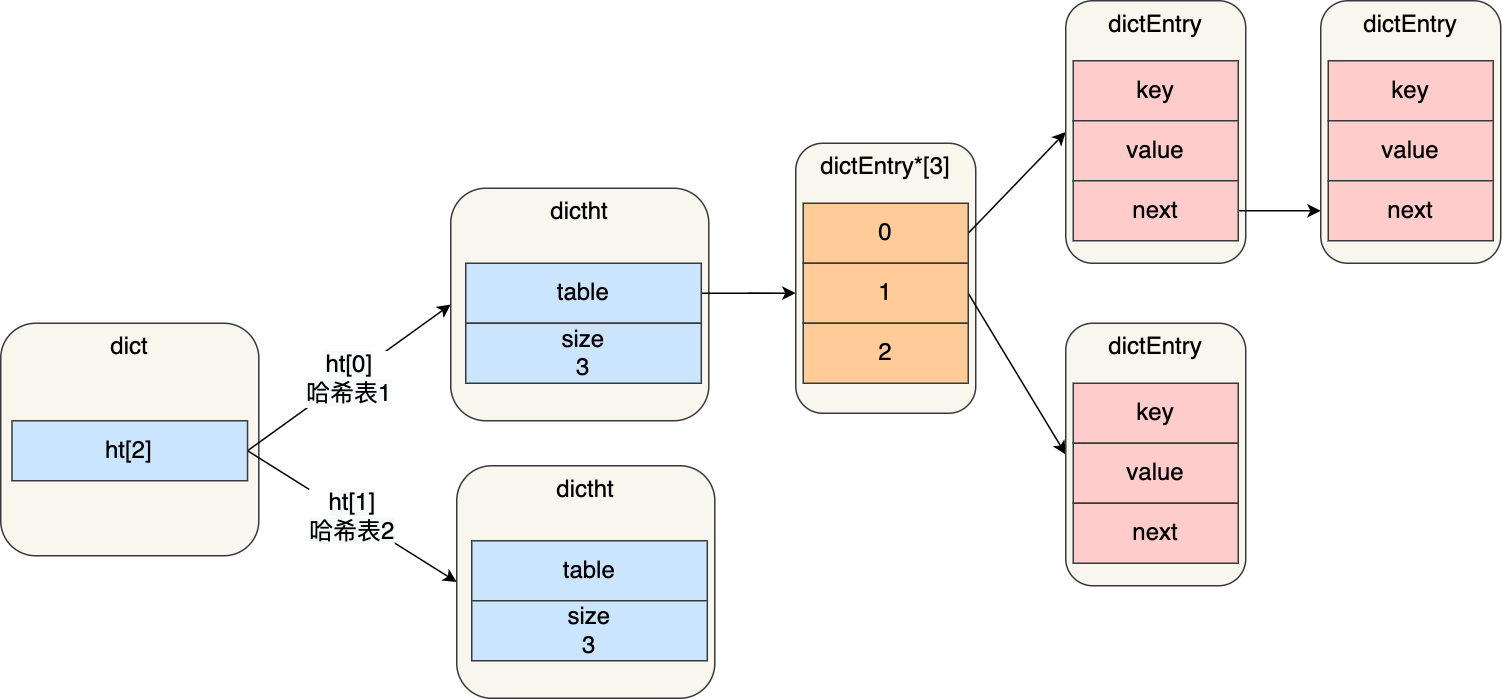
Dict的添加过程
- 当向Dict添加键值对时,Redis首先根据key计算出hash值,然后对数组长度取余获取哈希表索引
-
Dict的扩容过程
与HashMap相同,哈希冲突导致链表过长会使得查询效率大大降低,因此要对数组扩容,以减小链表的长度
在两种情况下会触发redis哈希表的扩容:负载因子(LoadFactor = used/size) 负载因子 >= 1, 并且服务器没有进行BGSAVE等进程;
负载因子 >= 5;
static int _dictExpandIfNeeded(dict *d){/* 如果正在rehashing, 暂停扩容 */if (dictIsRehashing(d)) return DICT_OK;/* 哈希表为空,表示首次创建哈希表,初始数组长度为4 */if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);// d->ht[0].used >= d->ht[0].size: 负载因子 >= 1if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize || // 检查BGSAVE等进程d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) && // 负载因子 >= 5dictTypeExpandAllowed(d)){// 扩容为used+1,实际上会扩容为大于used+1的第一次2^nreturn dictExpand(d, d->ht[0].used + 1);}return DICT_OK;}
Dict的收缩过程
每次删除元素时,如果负载因子 < 0.1, 哈希表会收缩 ```c if (dictDelete((dict*)o->ptr, field) == C_OK) { deleted = 1;
/ 删除完元素后检查负载因子,小于0.1,收缩哈希表 / if (htNeedsResize(o->ptr)) dictResize(o->ptr); }
int htNeedsResize(dict *dict) { long long size, used;
size = dictSlots(dict); // 哈希表容量used = dictSize(dict); // 哈希表已使用量// 如果size > 4并且used/size < 0.1,收缩哈希表return (size > DICT_HT_INITIAL_SIZE &&(used*100/size < HASHTABLE_MIN_FILL));
}
int dictResize(dict *d) { unsigned long minimal; // rehash或者后台进程在bgsave,返回错误 if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; // 获取used minimal = d->ht[0].used; if (minimal < DICT_HT_INITIAL_SIZE) // used < 4, 则收缩至4 minimal = DICT_HT_INITIAL_SIZE; // 收缩至第一个大于等于used的2^n return dictExpand(d, minimal); }
<a name="ZtYK1"></a>#### Dict的rehash过程扩容还是搜索都要重新计算下表,即rehash过程1. 计算哈希表新的size和sizemask1. 根据size申请内存空间,创建dictht,并赋值给dict.ht[1]1. 标记dict.rehashidx=1,表示开始rehash1. 将dict.h[0]中的元素rehash到dict.h[1]中1. 将h[1]赋值给h[0],将h[1]初始化为空哈希表,并释放原来的h[0]内存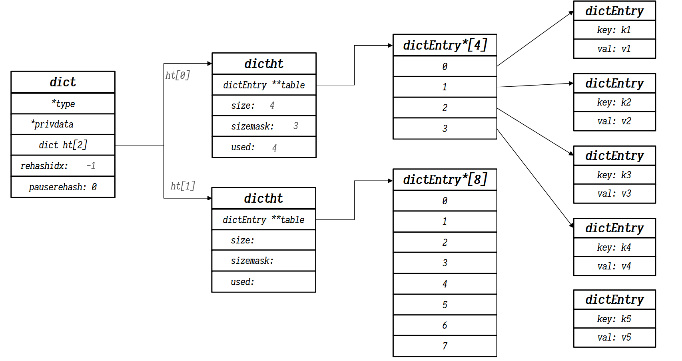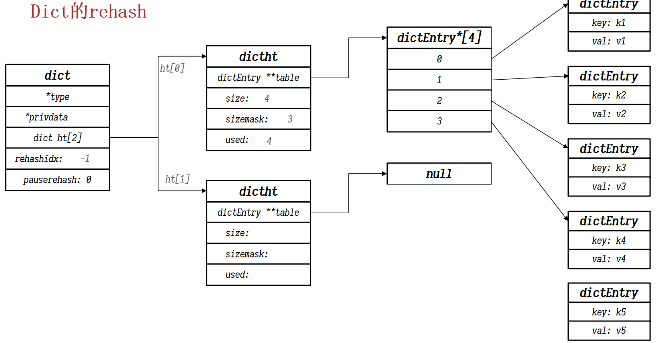<br />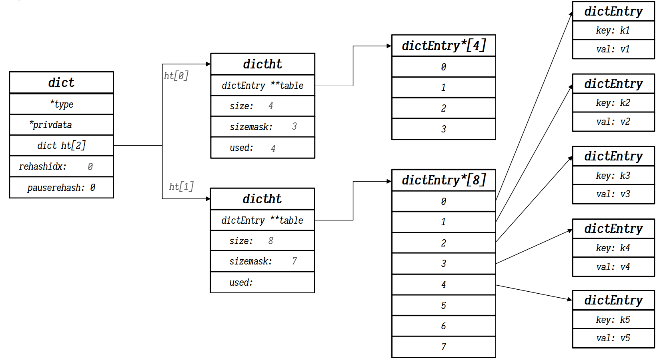<br />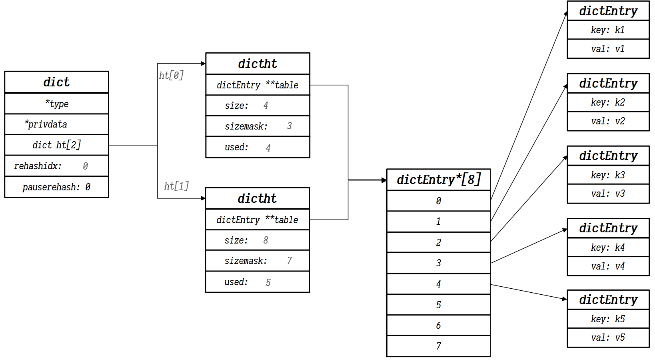<br />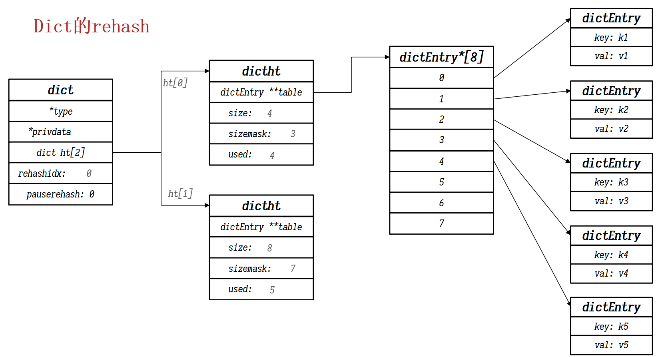<br />渐进式rehash- 由于rehash需要将h[0]中的全部元素转移至h[1]中, 如果哈希表中存有很多数据,这样是十分耗时的- redis在插执行增删改查操作时,会检查dict的rehashidx属性,如果它大于-1,则表明正在rehash,那么就将h[0]中rehashidx对应的链表转移至h[1]上,并将rehashidx++,知道所有的数据都转移至h[1]- rehashidx == -1时,代表rehash结束- 在rehash过程中,新增操作直接添加至h[1]中,查询手改删除则要查询两个哈希表并执行PS: redis中哈希表中采用的是头插法,由于redis是单线程的,所以不用担心HashMap中的并发死链问题<a name="QscCr"></a>### 2. 动态字符串 SDS<a name="fZuWl"></a>#### SDS概述** 为什么redis要自定义字符串?**<br />因为c语言中的字符串存在很多问题:1. c语言字符串底层使用给一个char[]数组,以‘\0’为结束符,获取字符串长度需要手动计算1. 如果定义的字符串出现‘\0’字符将会出现错误,所以c语言字符串非二进制安全1. 由于底层为char型数组,所以长度固定不能够被修改```c//struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; // buf中字符串字节数uint8_t alloc; // buf申请的字节数unsigned char flags; // SDS的类型,用来控制SDS的头大小char buf[];}
一个包含字符串“name”的sds结构如下:
PS: attribute ((packed)): 紧凑的内存分配方式
#include <stdio.h>struct test1 {char a;int b;} test1;struct __attribute__((packed)) test2 {char a;int b;} test2;


SDS的优点
- 如果新字符串小于1M,新扩容的字符串长度为原始的两倍 + 1
如果新字符串大于1M,扩容后的长度为原来的长度 + 1M + 1
3. 整数集合 IntSet
Intset概述
整数集合是Set的一种实现方式,基于整数数组实现,长度可变、有序
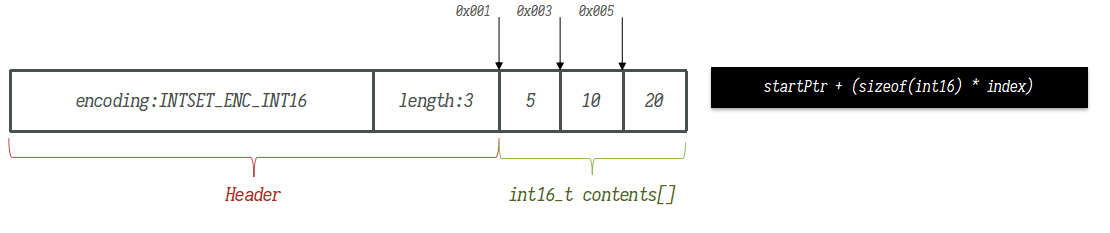
typedef struct intset {uint32_t encoding; // 编码方式,支持存放16位、32位、64位整数uint32_t length; // 集合的长度int8_t contents[]; // 整数数组}
为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:
IntSet升级
当一个新元素插入到Inset中,如果他的类型(int32_t)比原来集合的类型(int16_t)长,需要对整数集合进行升级,就是将所有元素的类型都升级为int32_t,并且要扩展contents数组的长度
举个例子,假设有一个整数集合里有 3 个类型为 int16_t 的元素。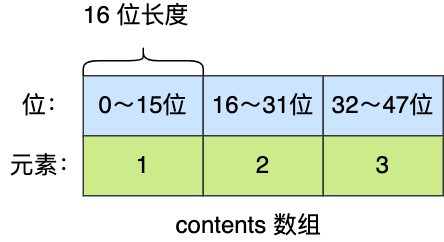
现在,往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容,在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素。
扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下: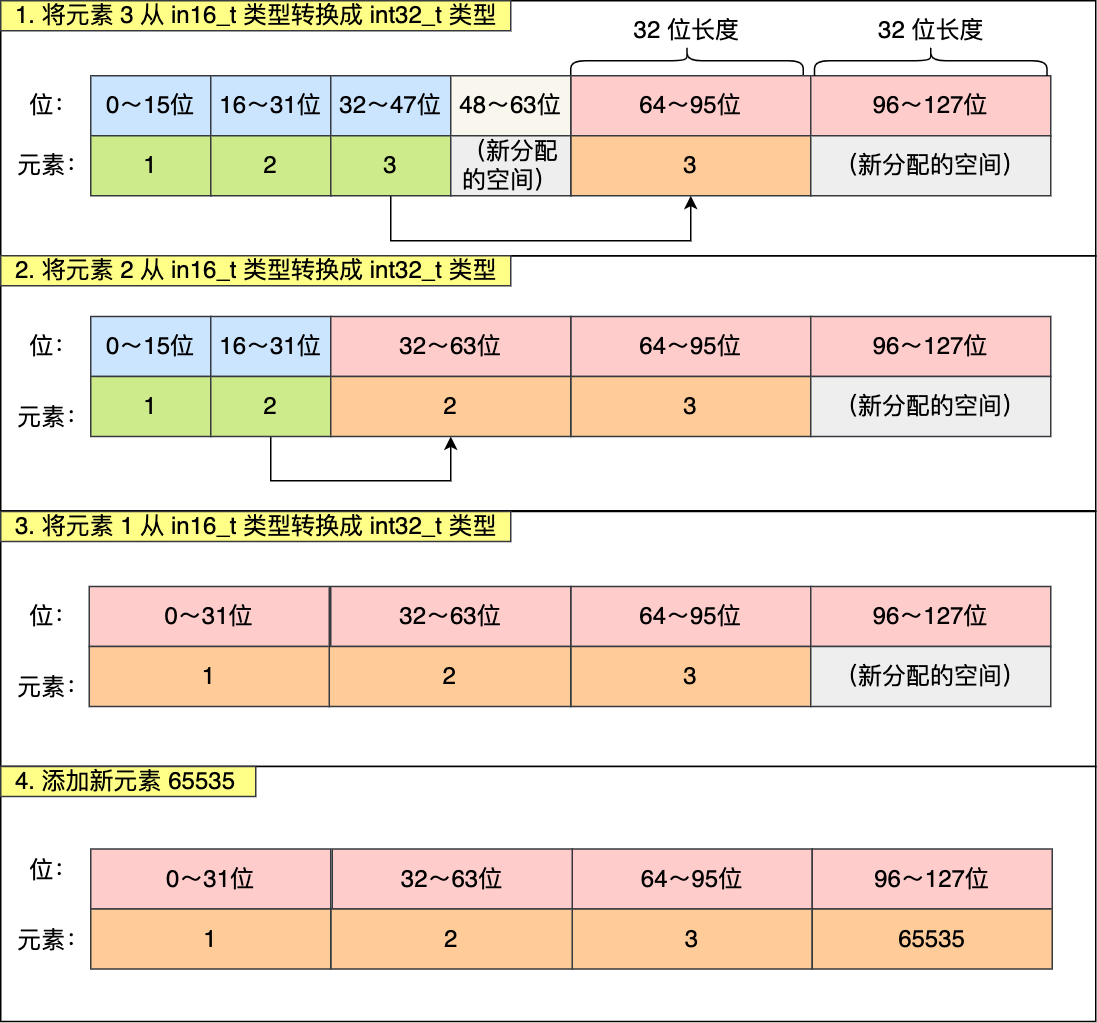
IntSet源码
/* 往集合中添加一个整数 */intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {// 获取添加的整数的编码uint8_t valenc = _intsetValueEncoding(value);// 插入的位置uint32_t pos;if (success) *success = 1;// 判断插入数值的编码是否超过了集合的编码if (valenc > intrev32ifbe(is->encoding)) {// 超过集合编码,进行升级return intsetUpgradeAndAdd(is,value);} else {// 从集合中寻找是否已经存在了valueif (intsetSearch(is,value,&pos)) {if (success) *success = 0;// 存在value,无须插入,直接返回return is;}// 数组扩容is = intsetResize(is,intrev32ifbe(is->length)+1);// 将pos之后的元素移动至pos+1,腾出pos空间,就是整体往后一位if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);}// 插入新的元素_intsetSet(is,pos,value);// 重置元素长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;}
/* 编码升级流程 */static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {uint8_t curenc = intrev32ifbe(is->encoding); // 当前集合编码uint8_t newenc = _intsetValueEncoding(value); // 升级的编码int length = intrev32ifbe(is->length); // 集合长度int prepend = value < 0 ? 1 : 0; // 负数 prepend=1, 插到最首部/* 设置新的编码 */is->encoding = intrev32ifbe(newenc);// 扩容is = intsetResize(is,intrev32ifbe(is->length)+1);// 倒叙将数组拷贝至扩容后正确的位置上while(length--)_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));/* Set the value at the beginning or the end. */if (prepend)// 将元素放到集合首部_intsetSet(is,0,value);else// 将元素放到集合末尾_intsetSet(is,intrev32ifbe(is->length),value);// 修改数组长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;}
4. 链表 List
链表结点
c语言中没有链表,Redis中自己设计了链表结构
typedef struct listNode {struct listNode *prev; // 前一个阶段struct listNode *next; // 下一个结点void *val; // 结点中的值} listNode;
链表结构设计
redis在listNode的基础上封装了list数据结构
typedef struct list {listNode *head; // 头结点listNode *tail; // 尾结点// 结点复制函数// 节点值复制函数void *(*dup)(void *ptr);//节点值释放函数void (*free)(void *ptr);//节点值比较函数int (*match)(void *ptr, void *key);//链表节点数量unsigned long len;} list;
链表的结构
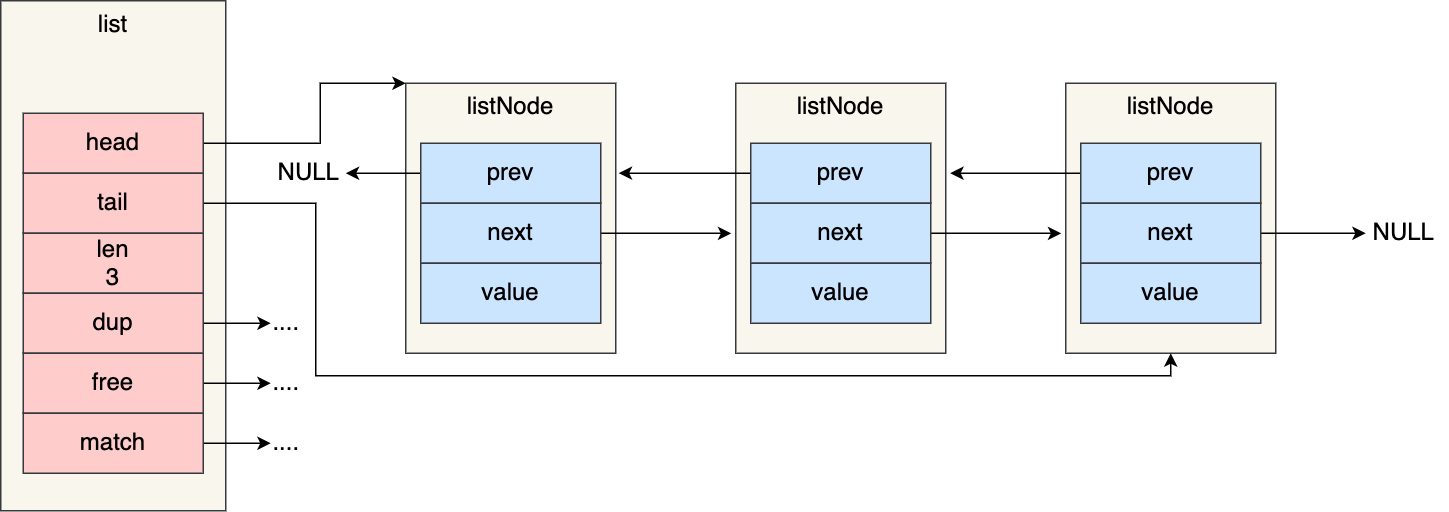
redis链表的优势:
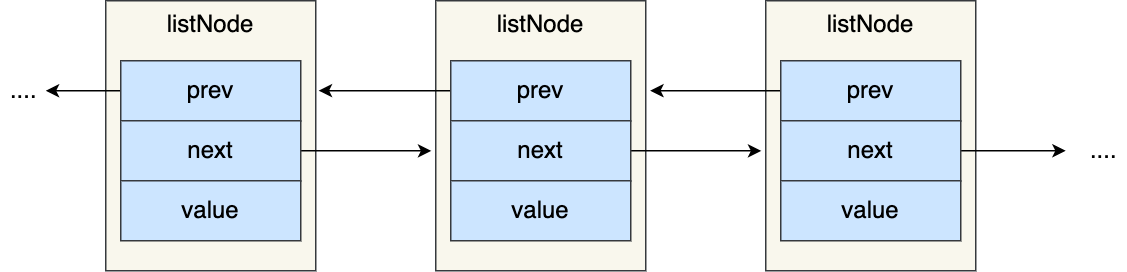
- redis链表中有prev和next两个指针,获取某一结点的前置结点和后置结点的时间复杂度都为O(1)
- list中封装了head和tail,获取头尾结点的时间复杂度为O(1)
- list中记录了链表长度,获取链表长度的时间复杂度为O(1)
- list使用void*存储结点值,所以链表结点可以存储不同类型的值
redis链表的缺点:
- 链表的结点是不连续的,无法利用CPU缓存局部性原理带来的优势
- 封装一个链表结点,需要存储指针,内存消耗较大
5. 压缩列表 ZipList
ZipList结构设计
压缩列表是一种内存紧凑型的数据结构,由连续内存块组成的顺序型数据结构,类似于数组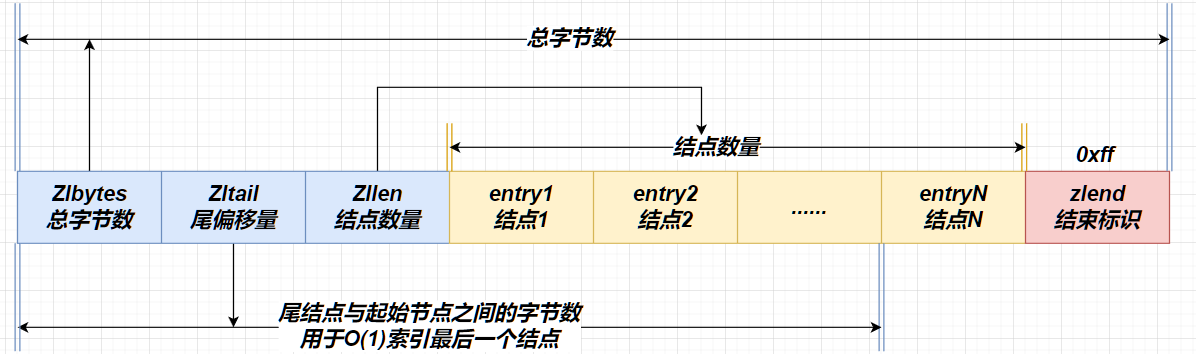
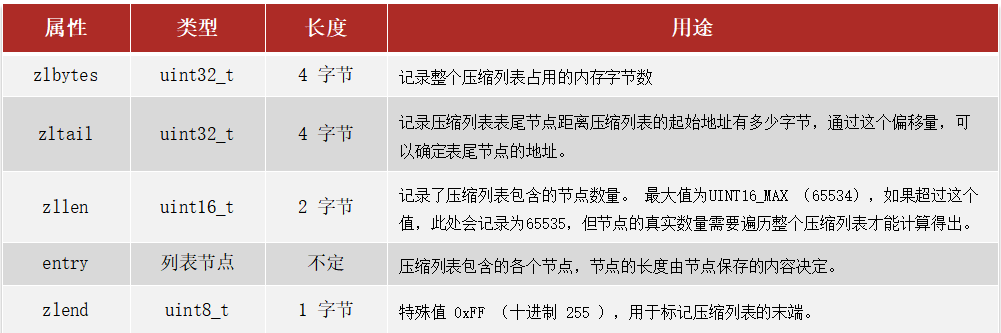
zipListEntry结构
普通链表记录结点需要两个指针,需要16个字节,浪费内存。entry采用了下面的结构:
- previous_entry_length:前一节点的长度,占1个或5个字节
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
- encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
- contents:保存结点,可以是字符串或者整数
Encoding编码
压缩列表的编码方式分为字符串和整数两种
- 字符串
encoding以“00”、“01”或者“10”开头,则证明content是字符串
例如,我们要保存字符串:“ab”和 “bc”

- 整数
如果encoding为“11”,则表明content为整数,encoding固定只占1个字节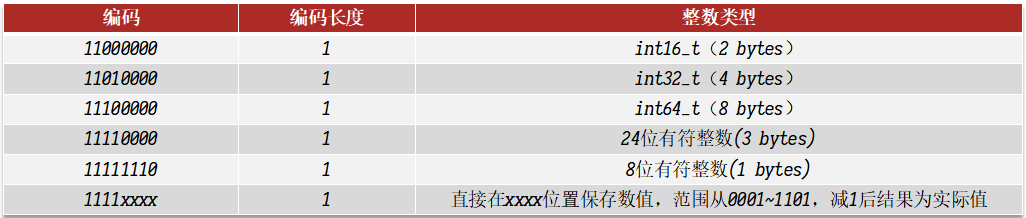
ZipList的连锁更新问题
连锁更新问题
压缩列表插入的元素较大是,可能会导致后序元素的prev_entry_length(前一个结点的长度)占用空间发生变化,进而引起连锁更新问题,导致每个元素的空间都要重新分配,造成压缩列表性能的下降
ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
压缩列表的优缺点
优点:
- 压缩列表占用连续的内存空间,可以利用CPU缓存提升查询性能
- 压缩列表设计紧凑,针对不同长度的数据,进行相应的编码,相对于数组数据长度都相同,可以更有效的节省内存开销
缺点:
- 压缩列表不可以存储过多元素,否则查询效率很低
- 新增或者修改某个元素时,结点占用的内存空间可能会重新分配,甚至引发连锁更新的问题
因此,Redis在存储的元素数量较少,或者元素值不大时,才会使用压缩列表作为底层数据结构
6. 快表 QuickList
QuickList结构
typedef struct quicklist {quicklistNode *head; // quciklist的链表头结点quicklistNode *tail; // quicklist的链表尾结点unsigned long count; // 压缩列表元素个数unsigned long len; // quicklist的结点个数...} quciklist;
typedef struct quicklistNode {struct quicklistNode *prev; // 前一个结点struct quicklistNode *next; // 下一个结点unsigned char *zl; // quicklistNode指向的压缩列表unsigned int sz; // 压缩列表的字节大小unsigned int count : 16; // 压缩列表中元素的个数...} quciklistNode;

向quicklist中添加元素时,会检查插入位置的quicklistNode上的压缩链表能否容下该元素,如果可以,就直接插入这个Node中,不可以的话,就新建一个quicklistNode
QuickList解决了什么?
如果存入大量数据,超过了ZipList的最佳上限,我们可以创建多个分片来存储数据
7. 跳表 SkipList
跳表概述
2. redis持久化
1. RDB快照
RDB:Redis Database Backup file(即Redis数据库备份文件),也可以称之为Redis数据快照
就是把Redis内存中的数据就记录在磁盘中,当Redis实例出现故障时,从磁盘中读取快照文件,恢复数据
RDB触发机制
如何使用RDB快照
Redis提供了两个命令生成RDB文件:save和bgsave,他们的区别在于是否在主线程中执行数据的备份
- 执行save命令,会在主线程中生成RDB文件,与redis操作在同一个线程,所以会阻塞主线程
- 执行bgsave命令,会创建一个子进程,子进程在后台执行数据备份,不会阻塞主线程
在redis.conf中可以配置redis触发机制
# 在900s内,如果有一个key被修改,则执行bgsavesave 900 1save 300 10save 60 10000save "" # 表示禁用RDB-----------------------------------------------------# redis的其他配置# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱rdbcompression yes# RDB文件名称dbfilename dump.rdb# 文件保存的路径目录dir ./
以下几点需要注意:
- RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令。
redis的快照是全量快照,也就是说每次执行快照都会吧内存中的所有数据记录在磁盘中。所以RDB是一个比较中的操作,频繁的执行RDB会对性能产生影响。频次太低,快照之间的数据可能会因为服务器的宕机丢失很多。
RDB实现原理

当bgsave开始执行时,会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后将内存数据写入RDB文件。
所谓fork,就是新建一个子进程,然后复制主进程的页表,这样主进程与子进程映射的就是同一块物理内存。并且这一块物理内存时只读(read-only)的,fork完毕后,子进程就开始吧内存中的数据写到磁盘中。持久化的过程中,如果主进程对内存进行写操作时,是不可以直接写的,因为子进程正在读取数据,这样可能会出现脏数据。fork中使用了copy-on-write技术,也就是说在发生写操作时,从原来的数据中拷贝一份数据,将数据写到拷贝的内存中,主进程读取数据时也从这个拷贝的数据中读取!
简单来说,bgsave的流程为:fork主进程得到一个子进程,复制页表,共享一片内存空间
- 子进程读取内存数据,写入一个新的rdb文件
- 将新的rdb文件替换掉旧的rdb文件
RDB的缺点
- RDB执行期间间隔长,两次RDB之间的数据可能会丢失
- fork子进程、写RDB文件都比较耗时
几点需要注意:
- fork主进程创建子进程,会阻塞主进程,复制页表,不复制内存,也是为了加速子进程的创建
- redis在执行bgsave的过程中,如果发生了写操作,这次写操作不会记录在此次bgsave中,只能等到下一次bgsave才能存储;如果系统恰好在rdb文件创建完后崩溃了,redis将丢失主进程在快照期间的写操作
-
2. AOF日志
AOF:Append Only File(追加文件),redis处理的每一条写命令都会记录在AOF文件,可以看作日志记录文件
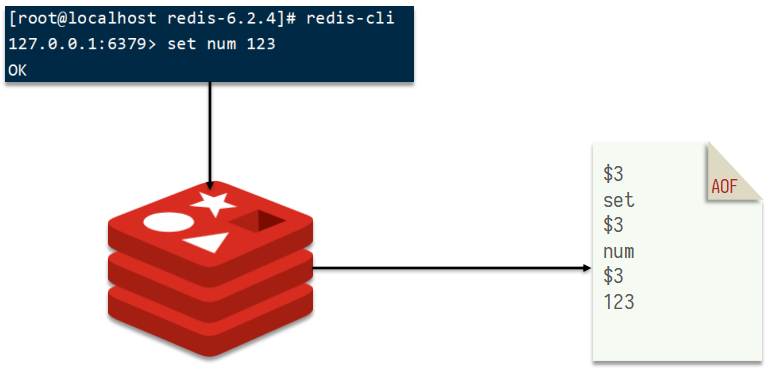
AOF配置
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
是所示# 是否开启AOF功能,默认是noappendonly yes# AOF文件的名称appendfilename "appendonly.aof"
由于AOF记录的是命令,所以AOF文件要比RDB文件大的多,并且AOF会记录对一个key的多次写操作,但是只有最后一次的写操作才是有意义的。redis提供了bgrewriteaof命令,让AOF执行重写功能,以最少的命令实现相同的效果!
redis触发阈值时会自动重写AOF文件,可在redis.conf中配置# AOF文件比上次文件 增长超过多少百分比则触发重写auto-aof-rewrite-percentage 100# AOF文件体积最小多大以上才触发重写auto-aof-rewrite-min-size 64mb
AOF持久化的两个风险
当redis没有来的即将AOF文件写入到内存中,服务器就宕机了,此时数据就会有丢失的风险
redis执行命令和写日志是同步进行的,瑞国写日志时间过长,下一条redis命令将会被阻塞
AOF写回策略
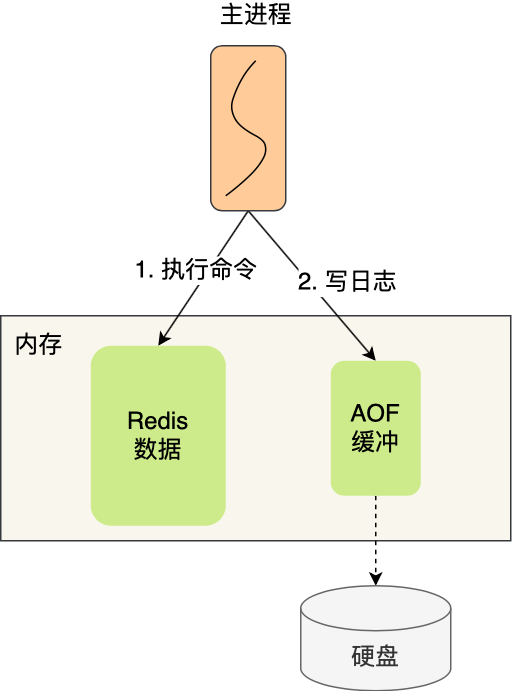
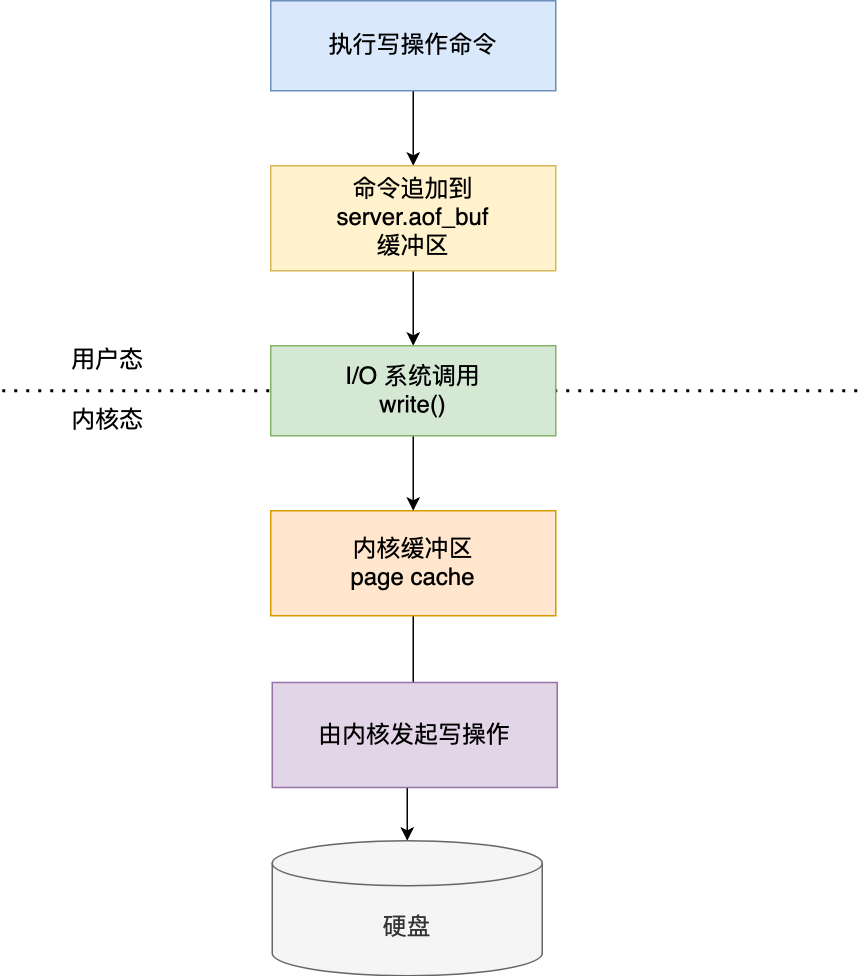
redis执行完写操作命令后,会将命令追加至server.aof_buf缓冲区中
- 然后通过write()系统调用,将aof_buf缓冲区中的数据添加至内核缓冲区page cache中,等待将数据写入硬盘
- 具体什么时候将内核缓冲区中的数据持久化到磁盘中,有内核决定
Redis 提供了 3 种写回硬盘的策略,控制的就是上面说的第三步的过程。
redis.conf文件中可以设置3中协会策略
# 表示每执行一次写命令,立即记录到AOF文件appendfsync always# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案appendfsync everysec# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘appendfsync no

- 如果需要高性能,就选择no
- 如果需要高可靠,就选择Always
- 如果允许数据丢失一系诶,同时又想要性能高,就选择everysec
这三种策略只是在控制 fsync() 函数的调用时机
当应用程序向文件写入数据时,内核通常先将数据复制到内核缓冲区中,然后排入队列,然后由内核决定何时写入硬盘。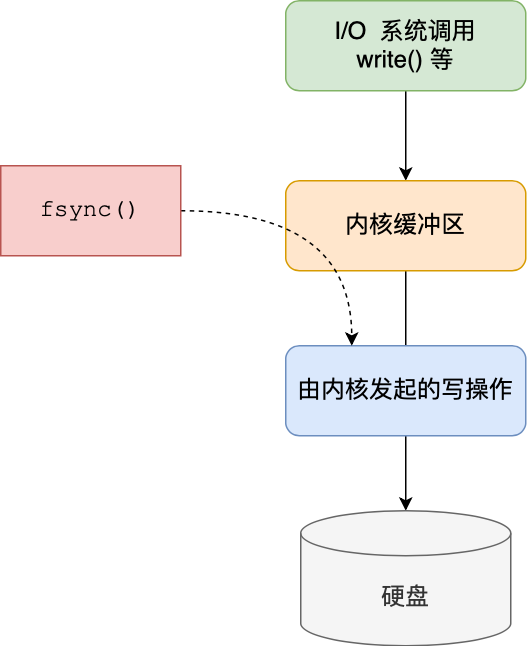
- Always 策略就是每次写入 AOF 文件数据后,就执行 fsync() 函数;
- Everysec 策略就会创建一个异步任务来执行 fsync() 函数;
-
AOF重写机制
AOF日志是一个文件,随着写操作的命令越来越多,文件也会越来越大。而文件过大会带来性能问题,如果redis重启后,读取redis加载数据,如果文件过大,加载过程就会很慢。
如果多次对一个key进行写入操作,只有最后一个是有效的
- 多次写入操作后,出现一个delete操作,所有操作无效
所以,为了消除这些无用的操作,redis启用了重写机制,来压缩AOF文件。
AOF重写机制:读取当前数据库的键值对,将键值用一条命令记录在记录到新的AOF文件中,全部记录完后,用新的AOF文件覆盖旧的AOF文件。这样就可以在多个键值对被反复修改,只保存最后一条,大大减少的AOF的命令数量
AOF后台重写
写入AOF的操作是在主线程中完成的,但是重写AOF文件实在后台的子进程bgrewriteaof中完成的,因为重写AOF文件是很耗时的!
与RDB的bgsave后台持久化一样,AOF也是使用fork()子进程使用copy-on-write技术重写的AOF
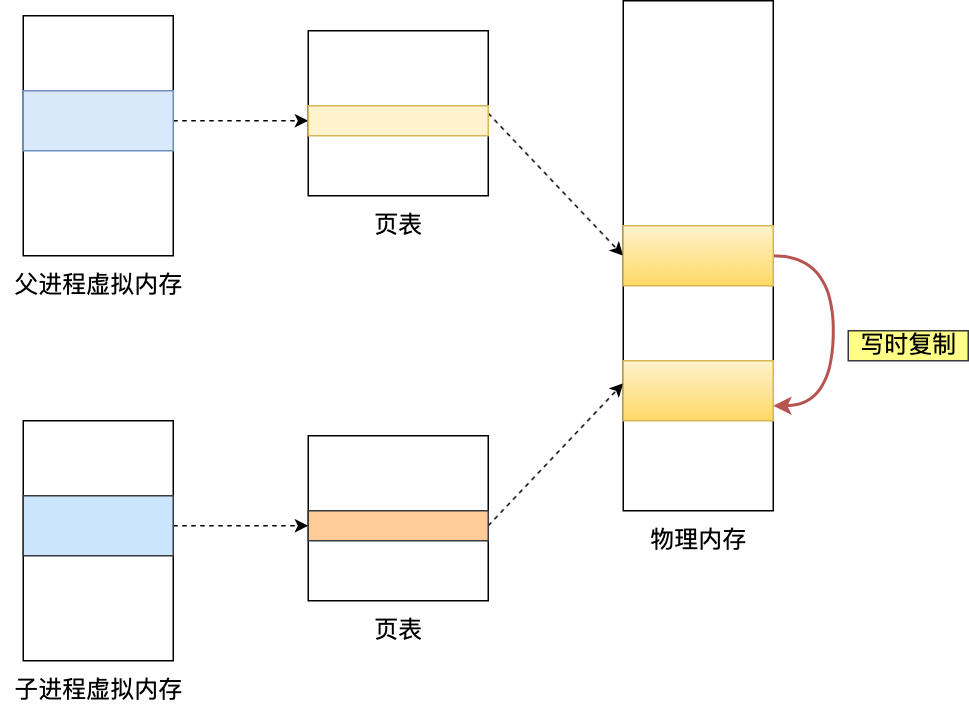
主进程通过fork()调用生成bgwriteaof子进程,操作系统将主进程的页表复制给子进程,这样主进程与子进程映射到同一片内存空间。这样主进程在进行增删改查的操作时,子进程可以在后台执行AOF读写,就不会阻塞redis的主进程了。同样,当主进程进行写操作时,会将被写的屋里内存拷贝一份,读写操作都作用在拷贝的内存上。
但是这样又带来了一个问题,重写AOF过程中,如果主进程修改了已经存在的key-value,此时子进程中的内存数据就和主进程中的内存数据不一致了,为了解决数据不一致问题,redis引入了AOF重写缓冲区,这个缓冲区在bgwriteaof进程之后使用。在重写AOF期间,redis执行完一个写命令后,会将这个命令写入AOF缓冲区和AOF重写缓冲区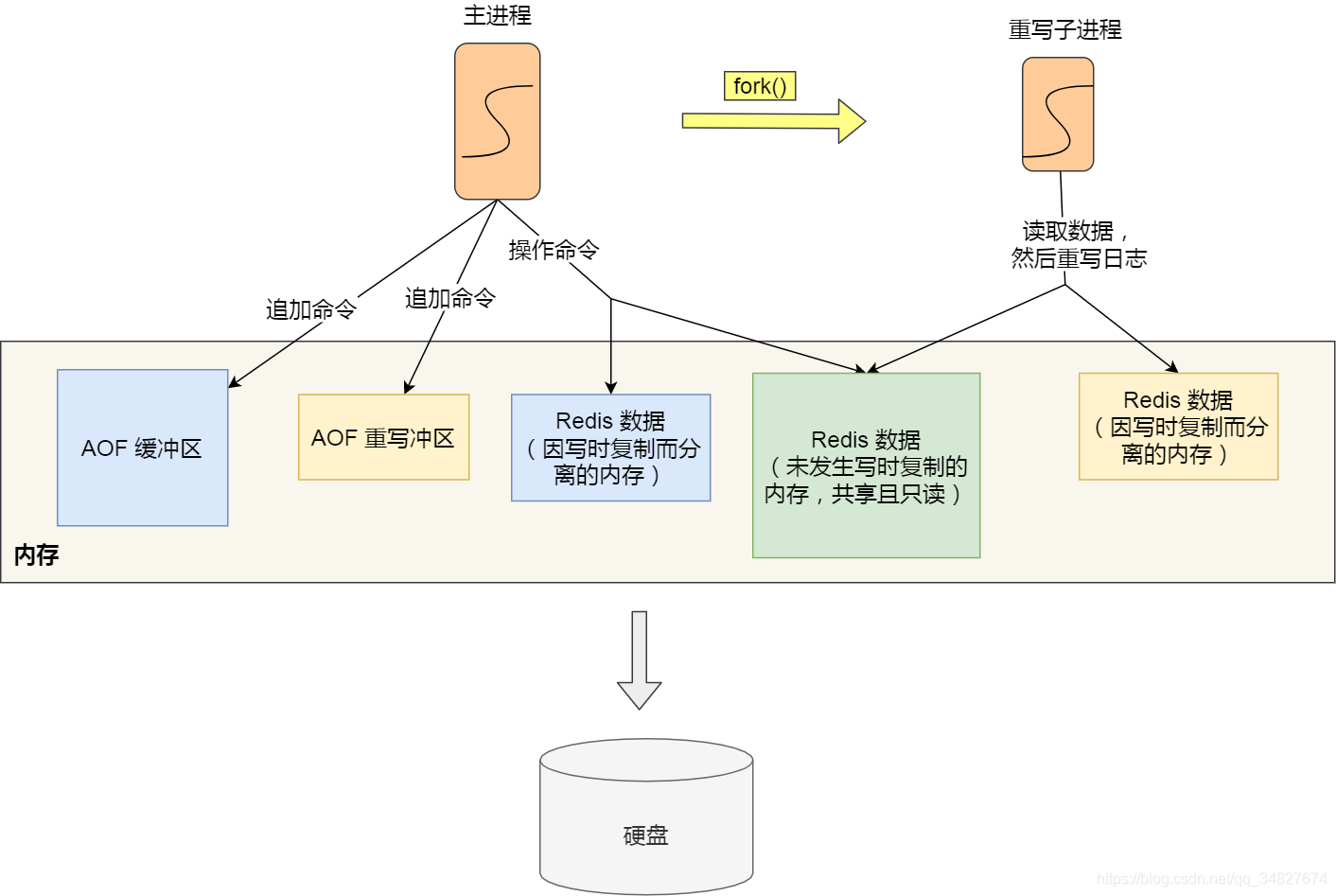
当bgrewriteaof执行完AOF重写工作后,会将AOF重写缓冲区中的内容添加至新的AOF文件中,保证AOF记录与数据库的一致性,然后用新的AOF文件覆盖旧的文件
3. redis缓存
本节以项目tust-bilibili为背景,为项目添加redis缓存
1. 添加redis缓存
首页视频添加redis缓存

/*** 分頁獲取視頻列表,在首頁瀑布流展示*/@GetMapping("/videos")public JsonData<PageResult<Video>> pageListVideos(Integer size, Integer no, String area) {PageResult<Video> videos = videoService.pageListVideos(size, no, area);return new JsonData<>(videos);}/*** 分页查询视频列表* @param size 分页查询的数量* @param no 第几页表* @param area 视频分区信息* @return 分页查询的结果*/@Overridepublic PageResult<Video> pageListVideos(Integer size, Integer no, String area){if(size == null || no == null) {throw new CustomException("参数异常");}Map<String, Object> map = new HashMap<>();map.put("start", (no - 1) * size);map.put("limit", size);map.put("area", area);Integer total = videoMapper.pageCountListVideos(map);List<Video> videoList = new ArrayList<>();if(total > 0) {videoList = videoMapper.pageListVideos(map);}return new PageResult<>(total, videoList);}
添加redis缓存的代码
@Overridepublic PageResult<Video> pageListVideosWithRedis(Integer size, Integer no, String area){if(size == null || no == null) {throw new CustomException("参数异常");}Map<String, Object> map = new HashMap<>();map.put("start", (no - 1) * size);map.put("limit", size);map.put("area", area);// 1. 从redis中查询缓存String key = PAGE_VIDEO_KEY_PREFIX + size + "-" + no + "-" + area;String s = stringRedisTemplate.opsForValue().get(key);// 2. 判断缓存是否命中if (!StringUtils.isNullOrEmpty(s)) {// 3. 命中,直接返回PageResult pageResult = JSONUtil.toBean(s, PageResult.class);return pageResult;}// 4. 未命中,根据map查询数据库Integer total = videoMapper.pageCountListVideos(map);List<Video> videoList = new ArrayList<>();if(total > 0) {videoList = videoMapper.pageListVideos(map);// 5. 存在信息,写回redisPageResult<Video> result = new PageResult<>(total, videoList);stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(result), 5,TimeUnit.MINUTES);}return new PageResult<>(total, videoList);}
根据videoId查询视频添加redis缓存
逻辑是一样的
/*** 获取视频详情* @param videoId 视频id* @return 视频信息和用户信息*/@Overridepublic Map<String, Object> getVideoDetailWithRedis(Long videoId){// 1. 从redis中根据videoId查询视频信息String key = VIDEO_ID_KEY_PREFIX + ":" + videoId;String s = stringRedisTemplate.opsForValue().get(key);// 2. 判断redis中是否包含数据if (!StringUtils.isNullOrEmpty(s)) {// 3. 命中, 直接返回return JSONUtil.toBean(s, Map.class);}// 4. 未命中,查询数据库// 4.1. 根据videoId获取视频信息Map<String, Object> result = new HashMap<>();Video video = videoMapper.getVideoById(videoId);if(video != null) {// 4.2. 根据视频信息获取userIdLong userId = video.getUserId();// 4.3. 根据userId获取用户信息UserVO userInfoById = userService.getUserInfoById(userId);UserInfo userInfo = userInfoById.getUserInfo();// 4.4. 将视频信息和用户信息封装在map中result = new HashMap<>();result.put("video", video);result.put("userInfo", userInfo);}// 5. 将查询结果,写入redisif(result != null) {stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(result));}return result;}
2. 缓存更新
使用redis缓存会存在数据的一致性问题,比如对数据库中的数据进行更新操作,而查询redis缓存仍是原来的数据,这就就出现了数据的还不一致,因此在更新数据库时,需要对redis缓存进行更新!
那么应该更新缓存还是删除缓存呢?
- 更新缓存:如果每次更新数据库都更新缓存,只有最后一次更新是有效的,那么就对进行了多次无效写操作
- 删除缓存:更新数据库时,删除缓存,再次查询时再更新缓存
如果不查询数据,都没有必要对数据进行更新,所以应该选择删除缓存
需要注意的点:
- 操作数据库和删除缓存需要同时成功或者同时失败,所以要加上事务注解@Transactional
- 应先更新数据库,再删除缓存
为什么要先更新数据库,再删除缓存?
因为在多线程情况下,更新数据库和删除缓存会出现数据不一致的问题,如果先删除缓存,在没有更新数据库的情况下,新的线程查询缓存,会将数据库中原始值更新到缓存中,而这样更新数据库的值就与缓存中的数据不一致,由于查询缓存和写入缓存都非常快,所以这样的线程安全问题出现的可能性高。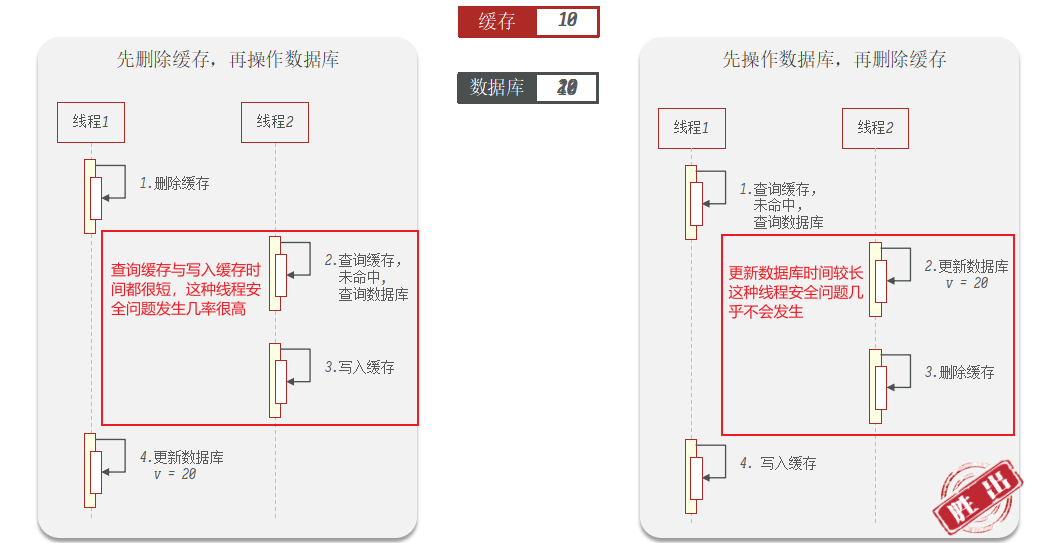
/** 解决缓存更新问题 **/@Transactionalpublic void updateVideoDetailWithRedis(Video video) {if(video == null) {throw new CustomException("参数不合法");}// 1. 操作数据库videoMapper.updateVideo(video);// 2. 删除缓存stringRedisTemplate.delete(VIDEO_ID_KEY_PREFIX + video.getId());}
3. 缓存穿透
缓存穿透:指请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,请求就会都打进数据库中
解决方案:
- 缓存空对象:
- 优点:实现简单、维护方便
- 缺点:占用了额外的内存消耗,会有短暂的数据不一致
- 布隆过滤器
- 优点:内存占用少,redis中没有多余的key
- 缺点:会出现误判,被放行的数据可能不在数据库中,拒绝的数据一定不在数据库中
布隆过滤器:布隆过滤器是数据库中的数据的哈希映射,使用较好的空间可以判断数据库中是否存有某个数据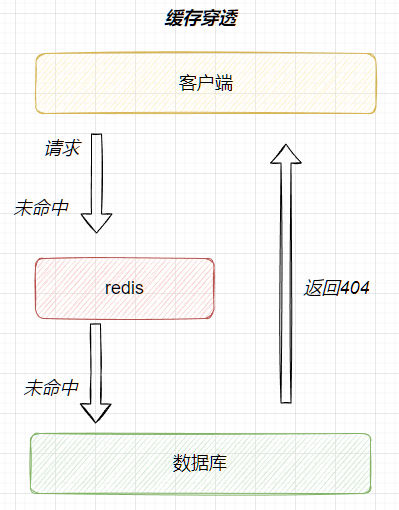

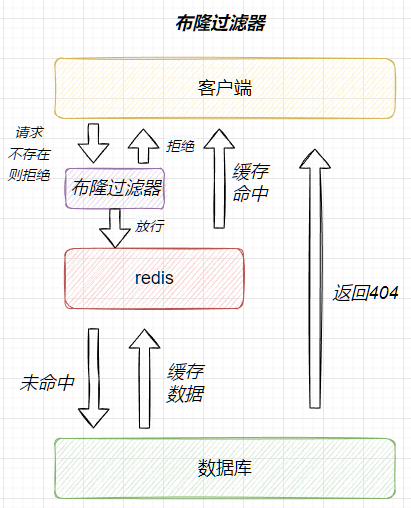
缓存空对象流程图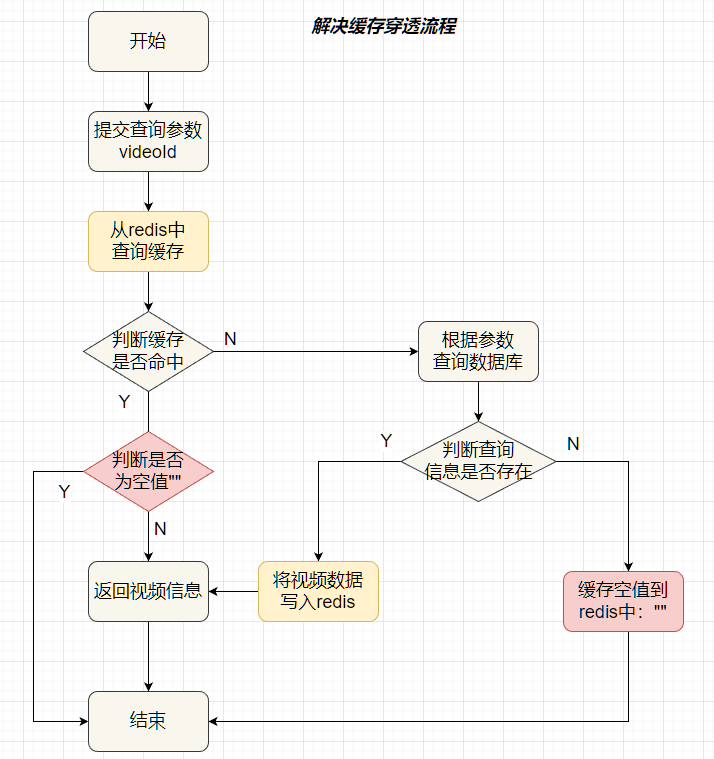
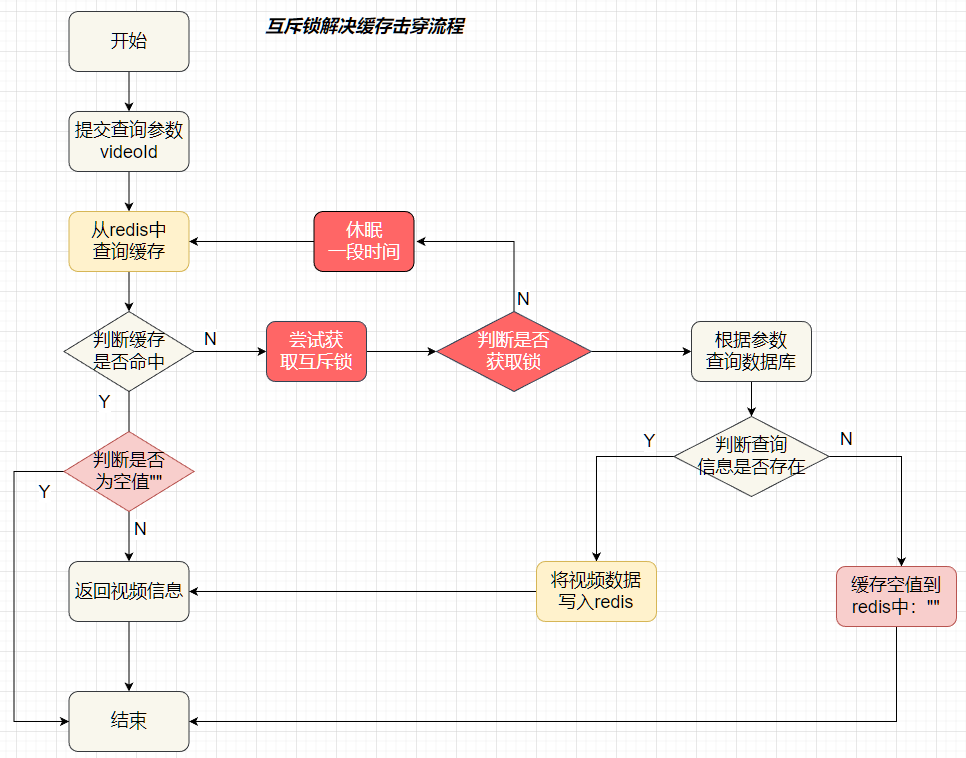
/*** 解决缓存穿透*/@Overridepublic Map<String, Object> getVideoDetailWithRedisPassThrough(Long videoId){if(videoId == null) {throw new CustomException("参数不合法");}// 1. 从redis中根据videoId查询视频信息String key = VIDEO_ID_KEY_PREFIX + videoId;String s = stringRedisTemplate.opsForValue().get(key);// 2. 判断redis中是否包含数据if (!StringUtils.isNullOrEmpty(s)) {// 3. 命中, 直接返回return JSONUtil.toBean(s, Map.class);}// 这里的s可能出现的情况(s == null, s == "")if(s != null) {// s != null 就意味着 s == "",即s为空值,直接返回return null;}// 4. 未命中,查询数据库,s == null// 4.1. 根据videoId获取视频信息Map<String, Object> result = new HashMap<>();Video video = videoMapper.getVideoById(videoId);if(video != null) {// 4.2. 根据视频信息获取userIdLong userId = video.getUserId();// 4.3. 根据userId获取用户信息UserVO userInfoById = userService.getUserInfoById(userId);UserInfo userInfo = userInfoById.getUserInfo();// 4.4. 将视频信息和用户信息封装在map中result = new HashMap<>();result.put("video", video);result.put("userInfo", userInfo);}// 5. 将查询结果,写入redisif(result == null) {// 解决缓存击穿:查询结果video为null,缓存空值到redis中stringRedisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES);}stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(result));return result;}
4. 缓存雪崩
5. 缓存击穿
缓存击穿:缓存击穿问题也叫热点key问题,就是一个key被高并发访问并且缓存重建时间较长,导致大量的key同时访问数据库并进行缓存重建,给数据库带来巨大的冲击!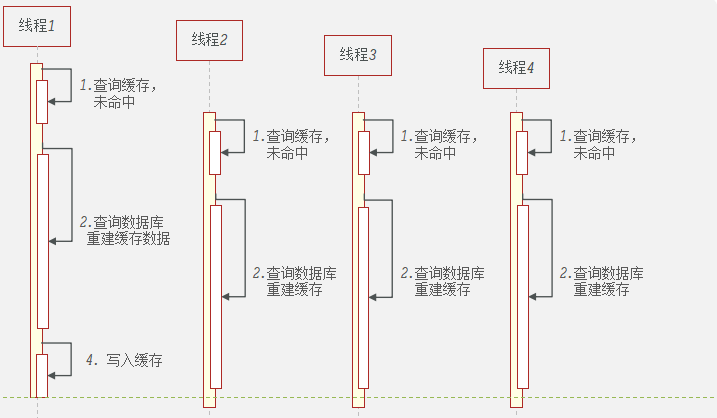
模拟缓存击穿
使用Jmeter压力测试,在5s中内执行1000个线程访问videoId=38的视频详情信息,理想情况下第一次访问redis未命中,查询数据库重建缓存,后面都应该从redis中读取数据。但是查询数据库和重建缓存都是需要时间的,在此期间发送的请求又会多次的请求数据库,重建缓存,从下图可以看到,数据库被访问了几十上百次!这就是缓存击穿问题,解决缓存击穿问题,就要只访问一次数据库!
缓存击穿的解决方案:
- 互斥锁
-
互斥锁
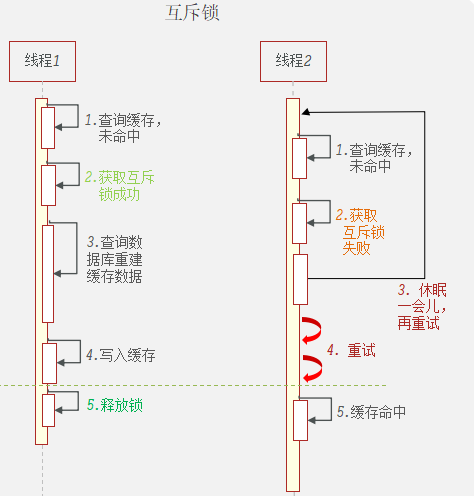
使用redis里的setnx作为互斥锁
只有当key不存在时才可以设置键值对,key存在时,不可以修改redis:0>setnx lock 1"1"redis:0>get lock"1"redis:0>setnx lock 2"0"redis:0>setnx lock 3"0"
 ```java
/**
```java
/**解决缓存击穿:互斥锁 */ public Map
if(videoId == null) { throw new CustomException(“参数不合法”); }
// 1. 从redis中根据videoId查询视频信息 String key = VIDEO_ID_KEY_PREFIX + videoId; String s = stringRedisTemplate.opsForValue().get(key);
// 2. 判断redis中是否包含数据 if (!StringUtils.isNullOrEmpty(s)) { // 3. 命中, 直接返回 return JSONUtil.toBean(s, Map.class); }
if(s != null) { return null; }
// 4. 未命中,查询数据库,缓存重建 String lock = VIDEO_MUTEX_KEY_PREFIX + key; Map
// 没有获取到互斥锁,休眠Thread.sleep(50);// 递归重新查询redis缓存return getVideoDetailWithRedisMutex(videoId);
}
// 获得互斥锁,查询redis是否命中 s = stringRedisTemplate.opsForValue().get(key);
// 这里重新查询了一遍redis,防止获取锁的时候,redis已经重建好缓存 if (!StringUtils.isNullOrEmpty(s)) {
// 3. 命中, 直接返回return JSONUtil.toBean(s, Map.class);
}
if(s != null) {
return null;
} // 查询数据库 // 4.1. 根据videoId获取视频信息 result = new HashMap<>(); Video video = videoMapper.getVideoById(videoId);
if(video != null) {
// 4.2. 根据视频信息获取userIdLong userId = video.getUserId();// 4.3. 根据userId获取用户信息UserVO userInfoById = userService.getUserInfoById(userId);UserInfo userInfo = userInfoById.getUserInfo();// 4.4. 将视频信息和用户信息封装在map中result = new HashMap<>();result.put("video", video);result.put("userInfo", userInfo);
} // 5. 将查询结果,写入redis if(result == null) {
// 解决缓存击穿:查询结果video为null,缓存空值到redis中stringRedisTemplate.opsForValue().set(key, "", 2, TimeUnit.MINUTES);
} stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(result)); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 释放锁 unlock(lock); } return result; }
/ 互斥锁 / public boolean trylock(String key) { // 互斥锁,设置10s,10s后销毁,以防出现问题永远存在redis里 Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, “1”, 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); }
/ 解锁,就是将redis里的lock删除 / public void unlock(String key) { stringRedisTemplate.delete(key); }
使用互斥锁后,只查询了一次数据库<br /><a name="n77WS"></a>#### 逻辑过期逻辑过期是在存储数据中设置一个过期时间,可以认为设置,他不是redis的TTL,理论上可以永远存在。先人为的将要缓存的数据存储到redis中,(例如双11时,将抢购的商品数据预先缓存至redis中)<br />当查询缓存时发现逻辑时间已经过期,表明需要重建缓存了。此时加上互斥锁,开启一个新的线程来中兴重建缓存操作,主线程中直接返回旧的数据。其他线程查询缓存获取互斥锁失败,也返回原来的过期数据。这样使用逻辑过期,就可以只重建一次缓存,并且可以保证每次请求可以快速响应,但是会有数据的不一致!<br />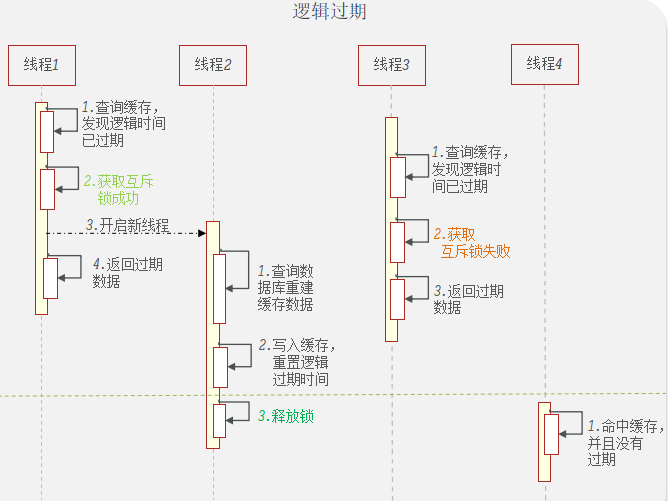<br />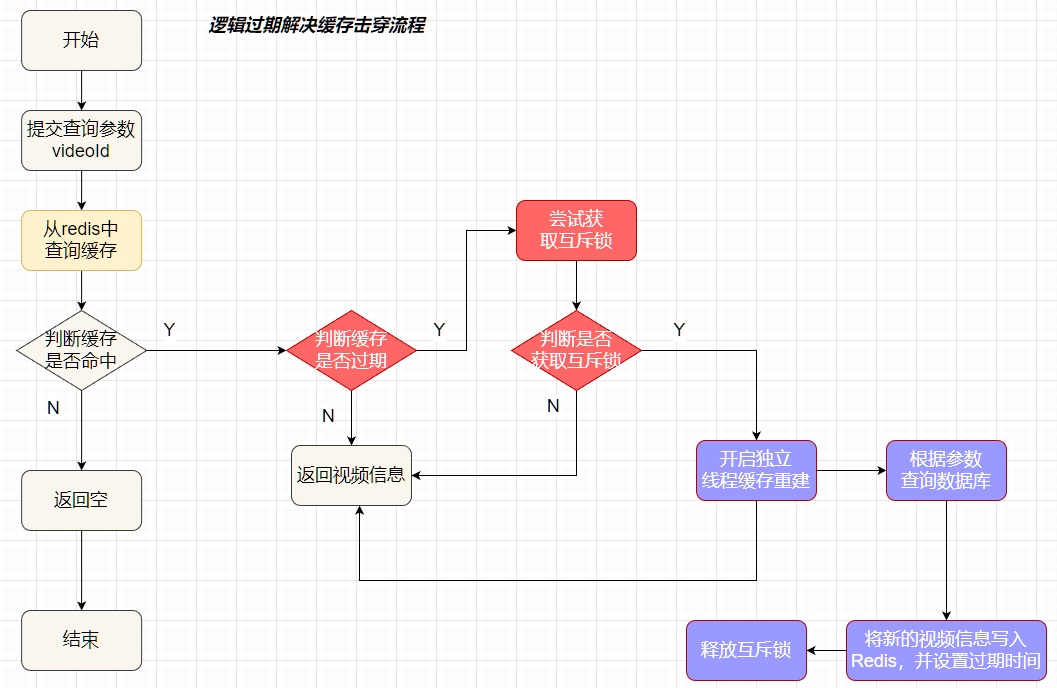<a name="Biitc"></a>### 6. redis缓存工具封装<a name="zHi18"></a>## 4. redis集群<a name="VnpK8"></a>### 1. redis主从集群单点redis的并发能力是有上限的,搭建redis主从集群,实现读写分离,可以提高redis的并发能力<br />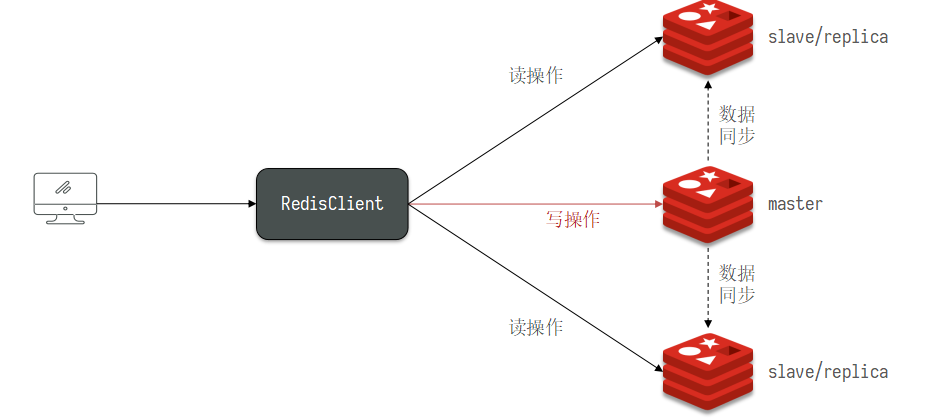<a name="iXurB"></a>#### 主从数据同步原理主从同步第一次是全量同步<br />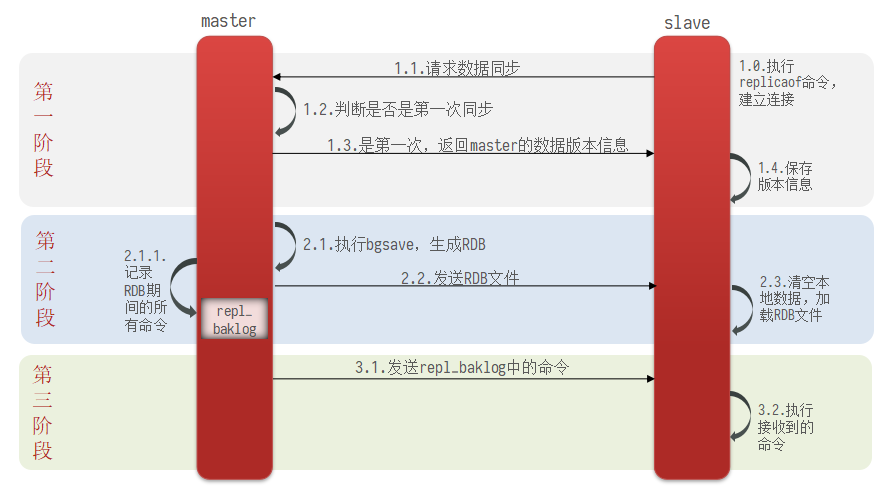<br />master如何判断接结点是不是第一次同步?- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。<br />**简述全量同步的流程**1. slave结点请求全量同步时,会发送自己的replid和offset,master结点判断自己的replid与slave结点是否相同,不相同的话,表明是第一次访问,开始全量同步1. master结点将主节点的replid和offset发送给slave结点,slave结点保存信息1. master结点在后台执行bgsave生成RDB文件,让后发送给slave结点1. slave结点接收到RDB文件后,清空本地数据,加载RDB文件1. master将RDB期间的命令保存在rep_baklog中,并将log发送给slave结点1. slave结点执行接收到的命令redis重启后,进行的是增量同步<br />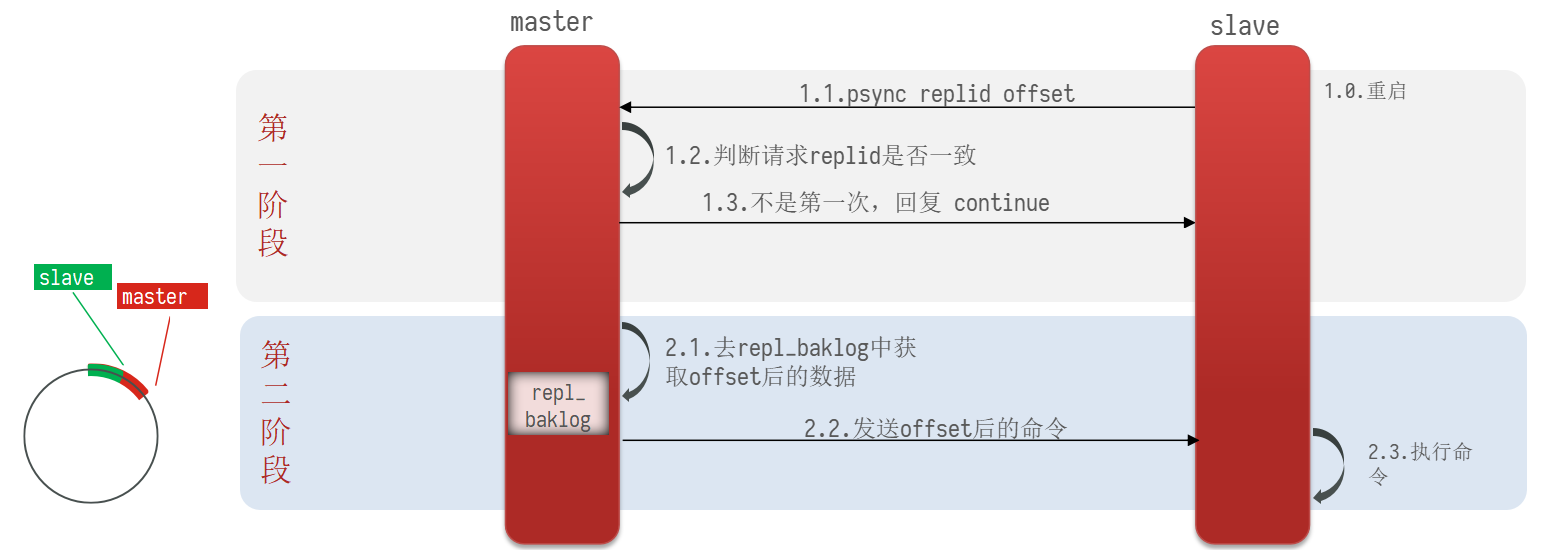<br />**简述增量同步流程**1. slave结点的redis重启后,携带repIid和offset向master结点申请同步1. master发现repIid结点与slave的一致,所以不是第一次同步,开始增量同步1. master到repl_baklog中寻找offset之后的命令,并将offset之后的命令发送给slave结点1. slave结点执行命令repl_baklog<br />repl_baklog是一个环形数组,用于增量更新,其内部维护一个master的offset,记录master写到什么位置了,当slave的offset发送过来后,就将偏移量之间的数据发送给slave节点<br />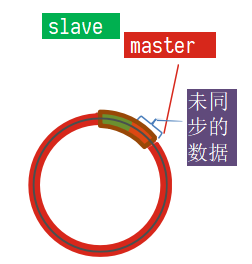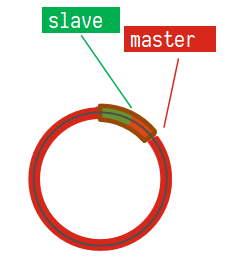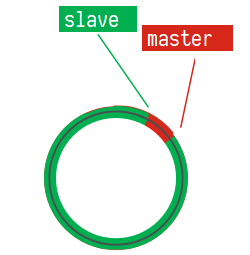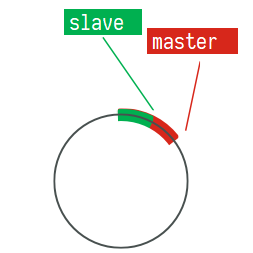<br />repl_baklog是有上限的,写满后就会覆盖最早的数据,如果slave结点断开时间太长,就会导致为备份的数据被覆盖掉,就无法基于log进行增量同步,就应该使用去量同步<a name="KBO1Z"></a>#### redis主从集群搭建这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:| **IP** | **PORT** | **角色** || --- | --- | --- || 192.168.150.101 | 7001 | master || 192.168.150.101 | 7002 | slave || 192.168.150.101 | 7003 | slave |要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。<a name="cjapC"></a>##### 1)创建目录我们创建三个文件夹,名字分别叫7001、7002、7003:```shell# 进入/tmp目录cd /temp# 创建目录mkdir 7001 7002 7003

2)恢复原始配置
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
# 开启RDB# save ""save 3600 1save 300 100save 60 10000# 关闭AOFappendonly no
3)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝cp redis-6.2.4/redis.conf 7001cp redis-6.2.4/redis.conf 7002cp redis-6.2.4/redis.conf 7003# 方式二:管道组合命令,一键拷贝echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/home\/project\/redis-cluster\/7001\//g' 7001/redis.confsed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/home\/project\/redis-cluster\/7002\//g' 7002/redis.confsed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/home\/project\/redis-cluster\/7003\//g' 7003/redis.confsed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.confsed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下
# redis实例的声明 IPreplica-announce-ip 172.26.34.179
每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
sed -i '1a replica-announce-ip 172.26.34.179' 7001/redis.conf# 逐一执行sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.confsed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.confsed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf# 或者一键修改printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 172.26.34.179' {}/redis.conf
3)启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个redis-server 7001/redis.conf# 第2个redis-server 7002/redis.conf# 第3个redis-server 7003/redis.conf
启动后: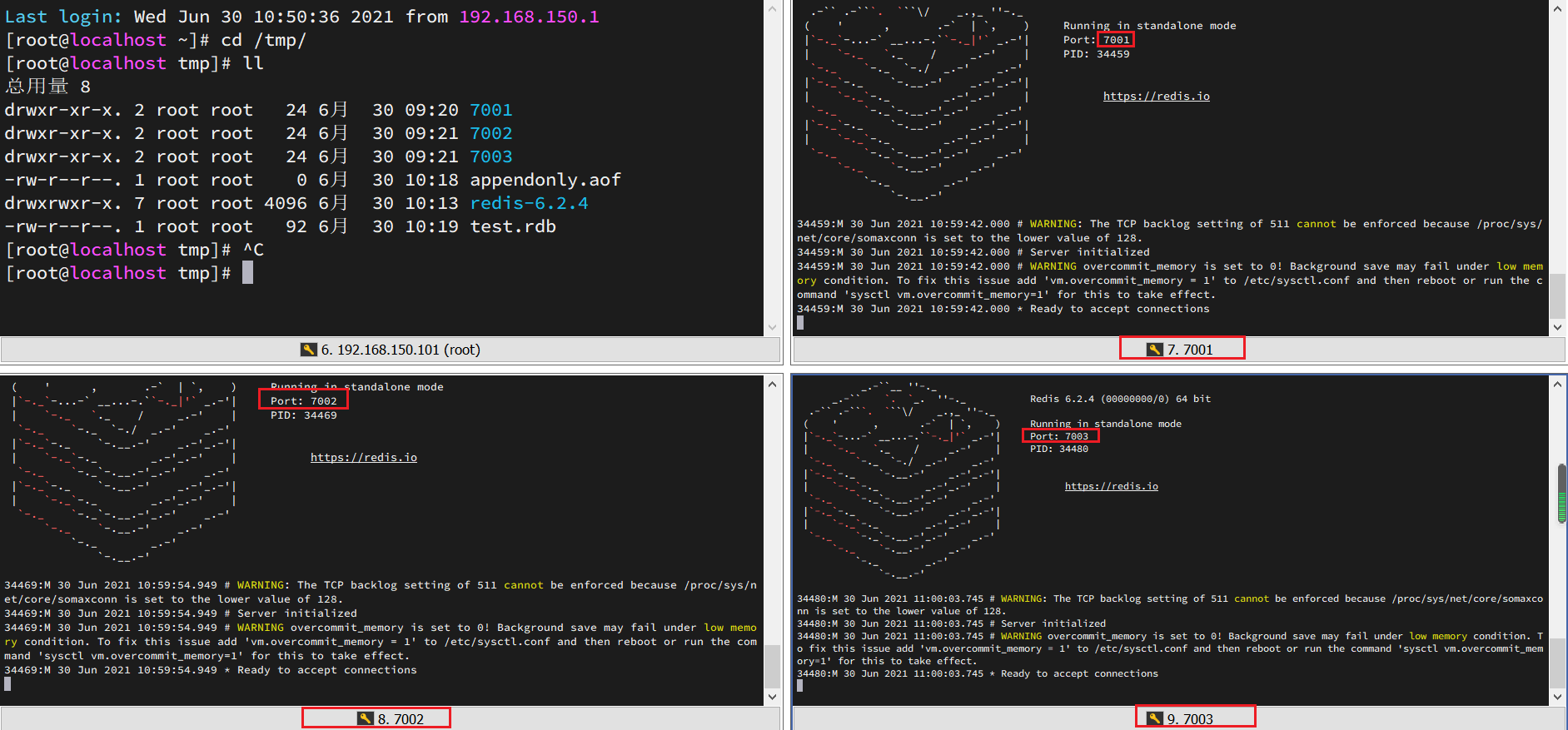
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
4)开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
- 修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
- 使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
如果redis设置密码的话,必须在redis.conf中,加入auth密码认证,如下:slaveof <masterip> <masterport>
masterauth <password>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002redis-cli -p 7002# 执行slaveofslaveof 192.168.150.101 7001
通过redis-cli命令连接7003,执行下面命令:
# 连接 7003redis-cli -p 7003# 执行slaveofslaveof 172.26.34.179 7001
然后连接 7001节点,查看集群状态:
# 连接 7001redis-cli -p 7001# 查看状态info replication
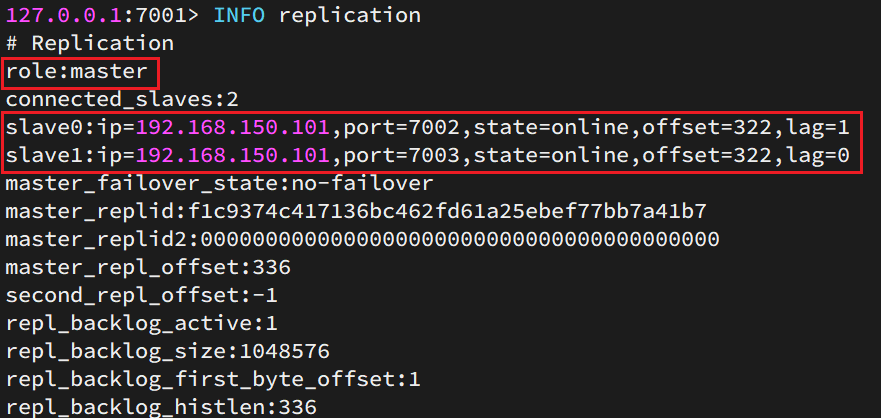
6) 测试
执行下列操作以测试:
- 利用redis-cli连接7001,执行
set num 123 - 利用redis-cli连接7002,执行
get num,再执行set num 666 - 利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
2. redis哨兵集群
redis哨兵作用与原理
redis从结点宕机了,可以使用master结点来同步数据
如果master主节点宕机了,该怎么办呢,redis哨兵就是解决这个问题的!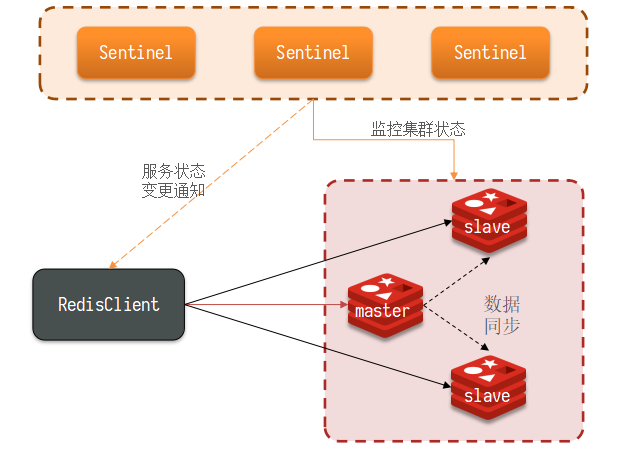
redis的哨兵机制主要是为了实现主从集群中主节点宕机自动恢复故障,哨兵sentinel机制的作用有:
- 监控:哨兵不断检查主从结点是否正常工作
- 自动恢复故障:如果master故障,哨兵会将一个slave结点晋升为master,故障恢复后仍以新的master为主
- 通知:当集群发生故障转移时,哨兵会将最新消息推送给redis客户端
可以看到哨兵承担着监控master的重任,因此它也必须是高可靠的,所以哨兵也要部署集群
哨兵是如何监控redis的状态的
sentinel通过心跳机制监测服务状态,每隔1s向每隔redis实例发型ping命令:
- 主观下线:某个哨兵结点发现某redis实例没有响应,就认为该结点主观下线
- 客观下线:超过指定数量(quorum)的哨兵结点发现某个redis实例没有响应,就认为它客观下线,就是真的宕机了
quoruo值最好超过哨兵实例的一半,其实就是一个投票机制
选举新的master
一旦master发生故障,redis会从slave中选择一个结点成为新的master,选择依据是:
- slave的offset值越大,说明slave结点中的数据越新,就选择它作为新结点
如何实现故障转移
当选择一个新的slave作为master后,
- 哨兵结点会向选择的slave结点,发送slave no one指令,让该节点成为新的master
- 哨兵向其他的所有结点发送指令,使得其他结点都成为新的master的从节点,并从新的master上同步数据
- 最后哨兵将故障结点标记为slave,故障恢复后,它也会成为master的slave节点
redis哨兵集群搭建
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
1)准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
# 进入/tmp目录cd /tmp# 创建目录mkdir s1 s2 s3
如图:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001sentinel announce-ip 172.26.34.179sentinel monitor mymaster 172.26.34.179 7001 2sentinel down-after-milliseconds mymaster 5000sentinel failover-timeout mymaster 60000dir "/home/project/redis-cluster/s1"dir "/tmp/s1"
解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝cp s1/sentinel.conf s2cp s1/sentinel.conf s3# 方式二:管道组合命令,一键拷贝echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.confsed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
2)启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个redis-sentinel s1/sentinel.conf# 第2个redis-sentinel s2/sentinel.conf# 第3个redis-sentinel s3/sentinel.conf

3)测试
尝试让master节点7001宕机,查看sentinel日志: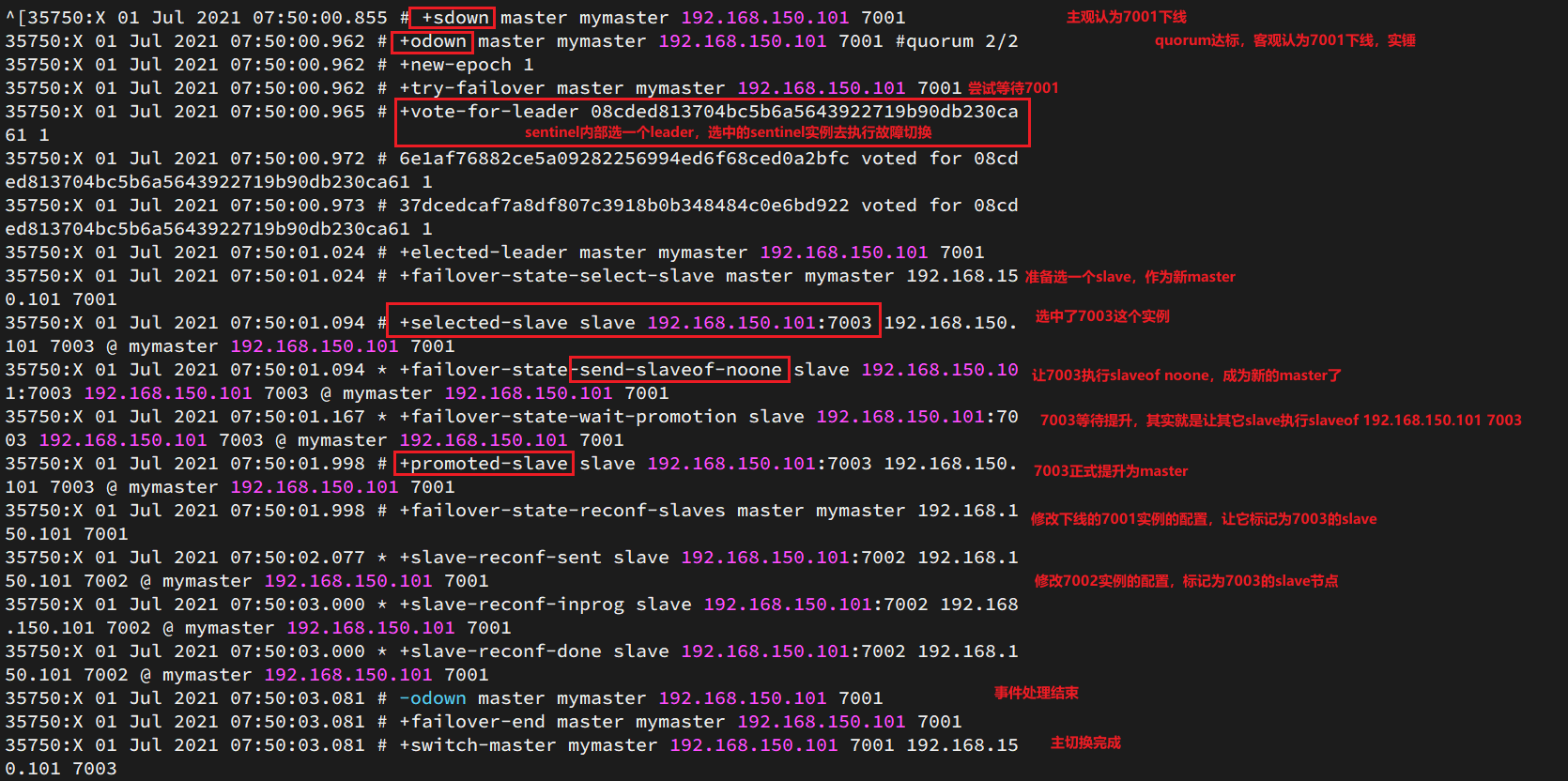
查看7003的日志: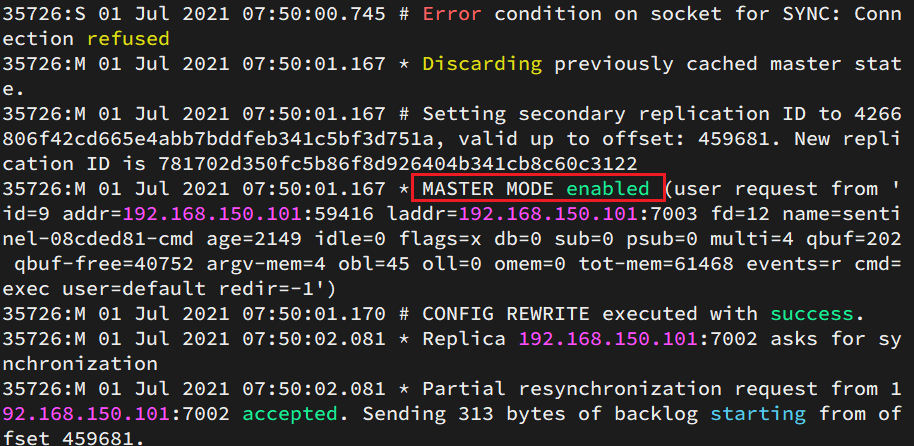
查看7002的日志: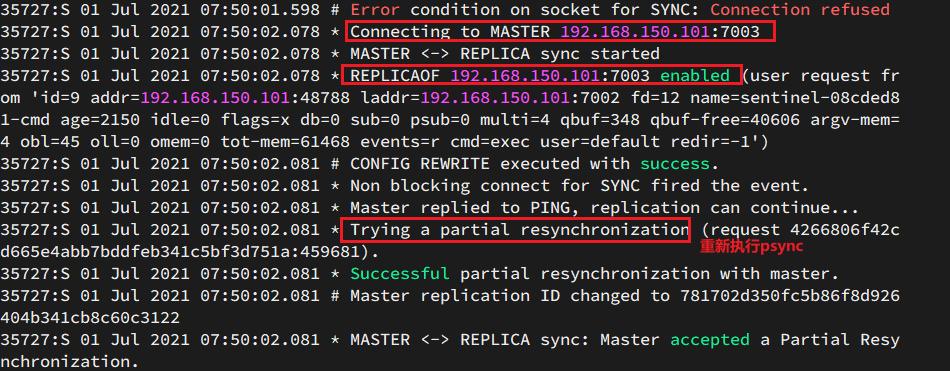
3. redis分片集群
分片集群结构
主从和哨兵解决了高并发和高可用的问题,但是仍有问题:
- 海量数据存储问题:主从同步耗时,存储海量数据将会使得性能下降
- 高并发写的问题:只有一个master结点,在高并发写的情况下,性能会下降
分片集群的特征
- 集群中有多个master,每个master上保存不同的数据
- 每个master上有多个slave结点
- master之间彼此通过心跳监测健康状态
- 客户端可以访问集群的任意结点,最终都会转发至正确的结点上

散列插槽
redis把每一个结点映射到0-16383共16384个插槽上,查看集群信息可以看出:
数据的key不是与结点绑定,而是与插槽绑定,redis通过哈希算法获取一个hash值,然后对16384取余,就可以得到插槽值
key中包含”{}”,且“{}”中至少包含1个字符,“{}”中的部分是有效部分,就只使用{}的值计算slot
集群伸缩
通过redis-cli —cluster中的集群命令,可以向集群中添加结点或者删除结点
比如,添加节点的命令: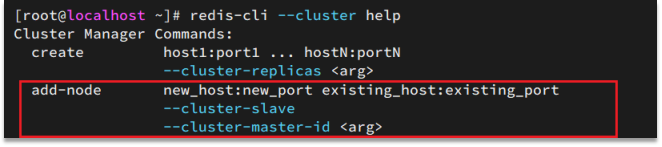
故障转移
当分片集群中的一个redis宕机时,会选择它的一个slave结点升级为master结点
使用cluster failover可以手动让集群中的某个master宕机
5. redis网络模型

若有收获,就点个赞吧
0 人点赞
