:::info 💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考
:::
1. Hadoop集群操作
1.1 启动Hadoop集群
1.1.1 格式化文件系统
如果集群是第一次启动,需要在hadoop100节点格式化NameNode。
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。

1.1.2 启动Hadoop进程
Hadoop集群的启动,需要启动其内部的两个集群框架,HDFS集群和YARN集群。启动方式有单节点逐个启动和使用脚本一键启动两种。- 启动HDFS
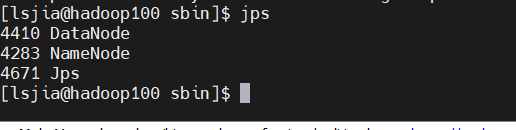
- 启动YARN

1.2 监控Hadoop集群
Hadoop集群有相关的服务监控端口,方便用户对Hadoop集群的资源、任务运行状态等信息有更直观的了解,具体如下表:| 服务 | Web接口 | 默认端口 |
|---|---|---|
| NameNode | http://namenode_host:port/ | 9870 |
| ResourceManager | http://resourcemanager_host:port/ | 8088 |
|---|---|---|
| MapReduce JobHistoryServer | http://jobhistroyserver_host:port/ | 19888 |
1.2.1 HDFS监控
Web端查看HDFS的NameNode:(a)浏览器中输入:http://hadoop100:9870
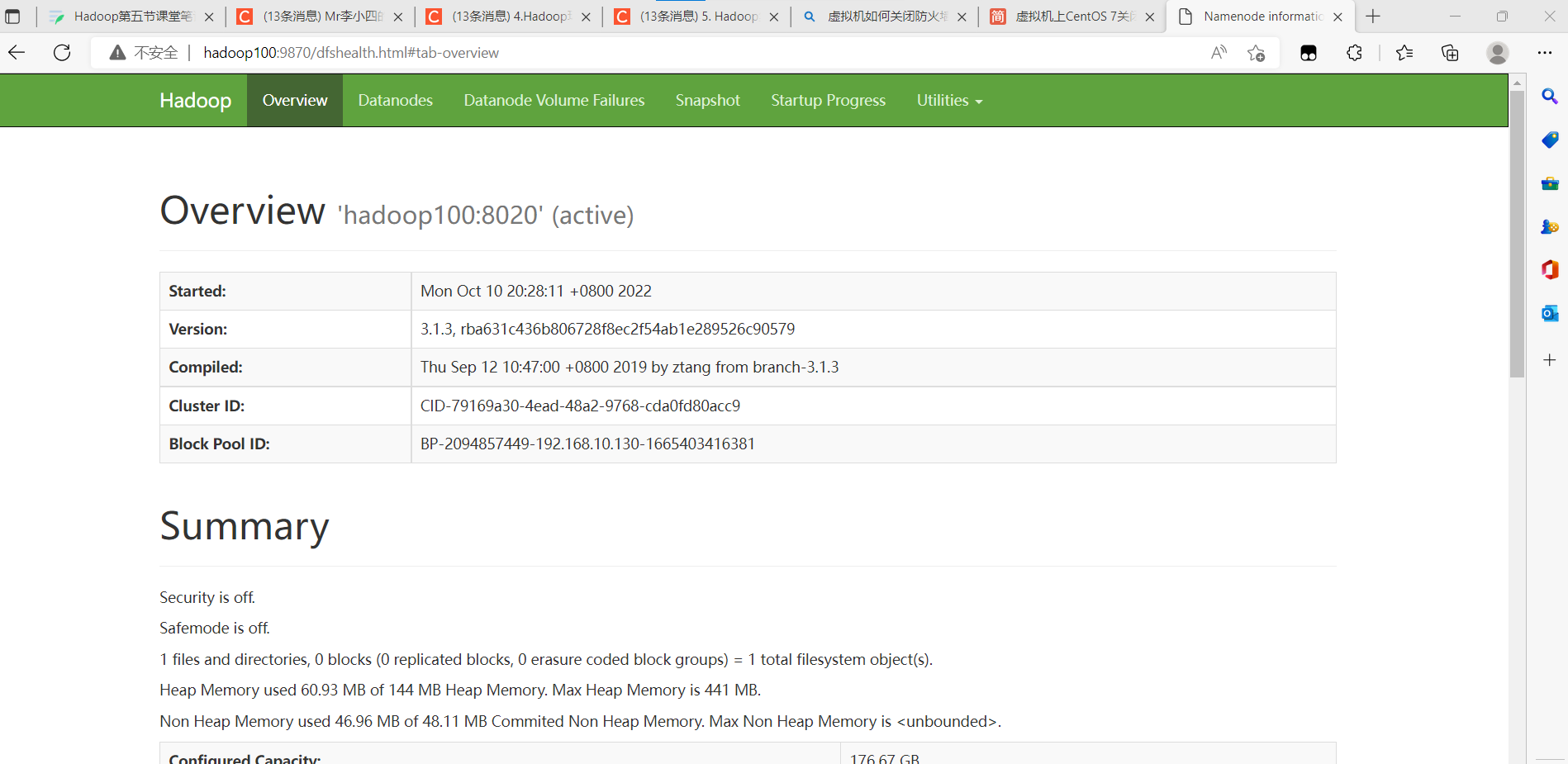 + Overview
记录了NameNode的启动时间、版本号、编译版本等一些基本信息。
+ Summary
记录集群信息。
提供了当前集群环境的一些有用信息,同时还标注了当前集群环境中DataNode的信息,对活动状态的DataNode也专门进行了记录。
+ NameNode Storage
提供了NameNode的信息,最后的State标示此节点为活动节点,可正常提供服务。
依次选择“Utilities”→“Browse the file system”命令可以查看HDFS上的文件信息。
+ Overview
记录了NameNode的启动时间、版本号、编译版本等一些基本信息。
+ Summary
记录集群信息。
提供了当前集群环境的一些有用信息,同时还标注了当前集群环境中DataNode的信息,对活动状态的DataNode也专门进行了记录。
+ NameNode Storage
提供了NameNode的信息,最后的State标示此节点为活动节点,可正常提供服务。
依次选择“Utilities”→“Browse the file system”命令可以查看HDFS上的文件信息。
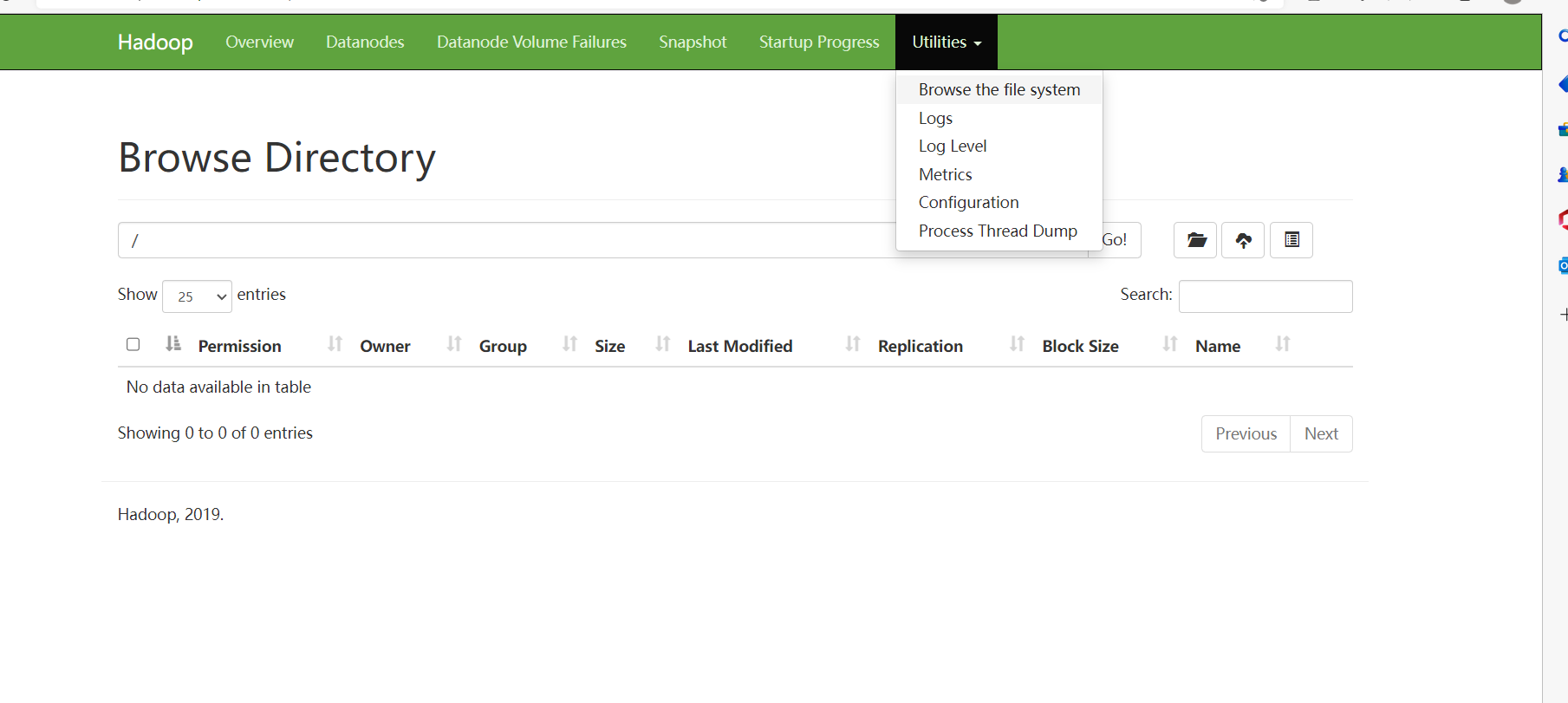 (b)查看HDFS上存储的数据信息
(b)查看HDFS上存储的数据信息
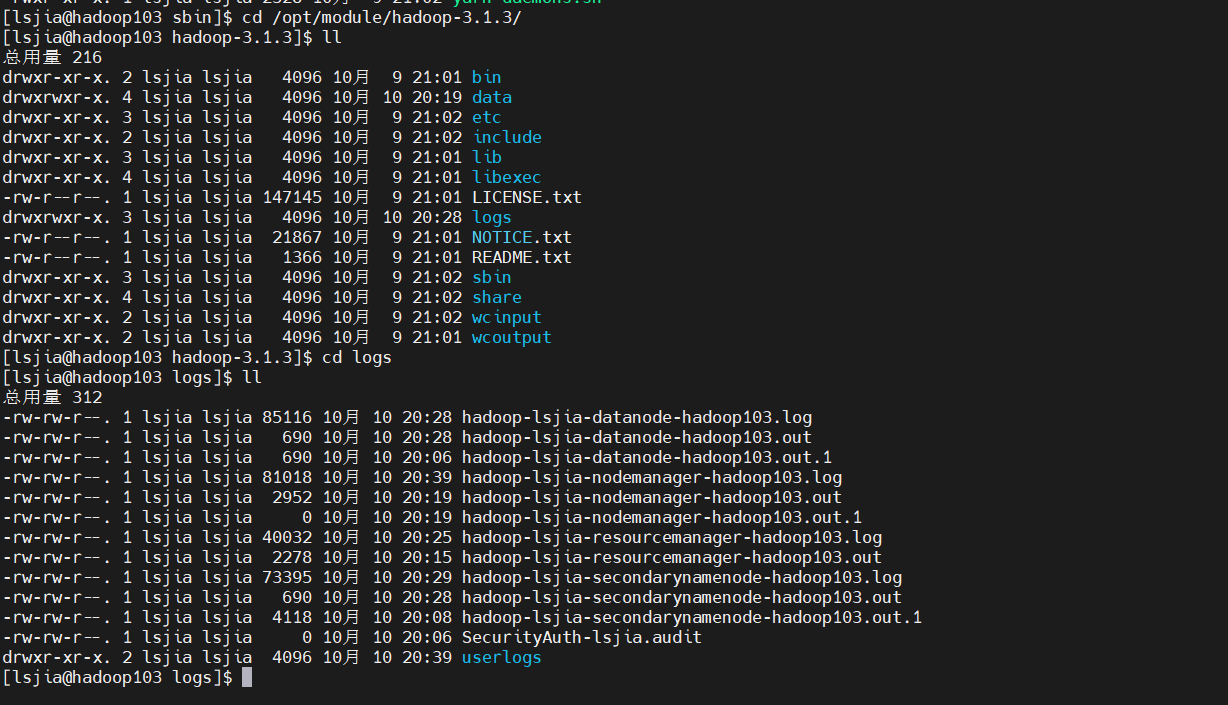

1.2.2 YARN监控
Web端查看YARN的ResourceManager:(a)浏览器中输入:http://hadoop103:8088
 (b)查看YARN上运行的Job信息
(b)查看YARN上运行的Job信息

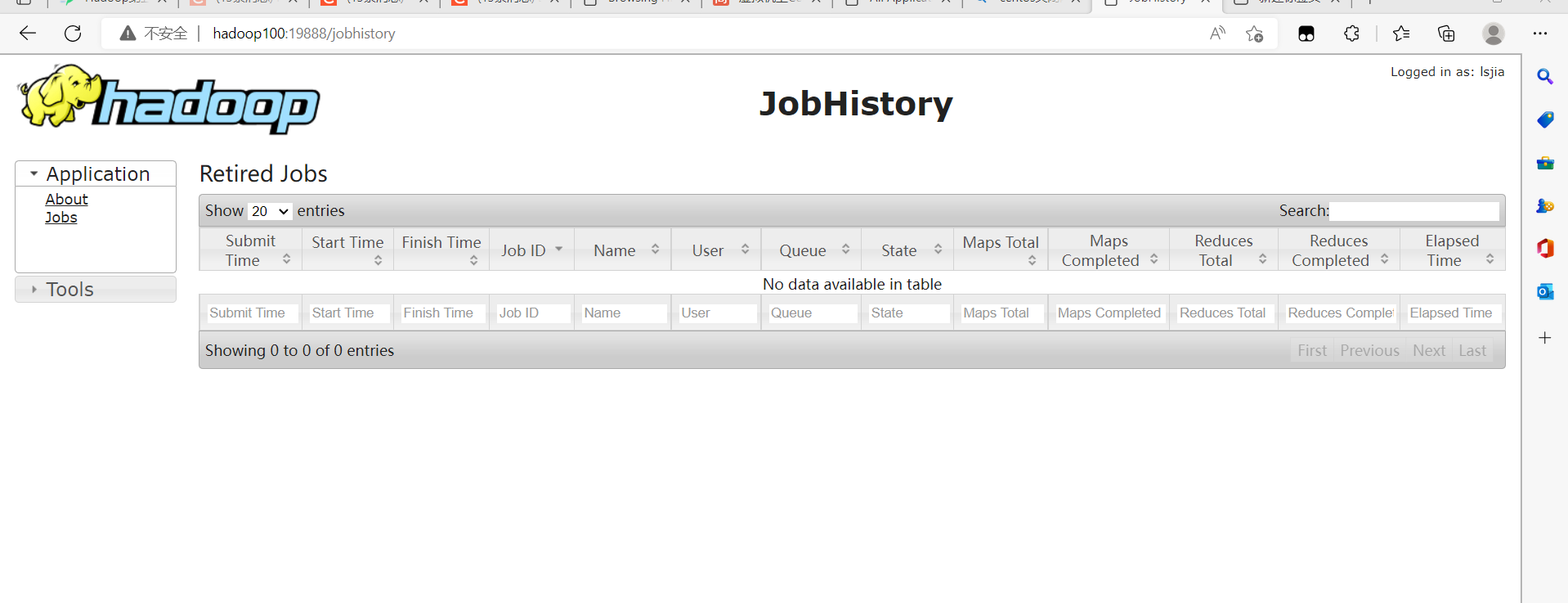
1.2.3 日志监控
Web端查看Hadoop的日志监控界面即JobHistroy:(a)在浏览器中地址栏中输入http://hadoop100:19888
 ## 1.3 Hadoop集群基本测试
### 1.3.1 上传文件到集群
1. 创建input目录,上传小文件
## 1.3 Hadoop集群基本测试
### 1.3.1 上传文件到集群
1. 创建input目录,上传小文件


- 上传大文件到/目录


1.3.2 查看文件
- 查看HDFS文件存储路径


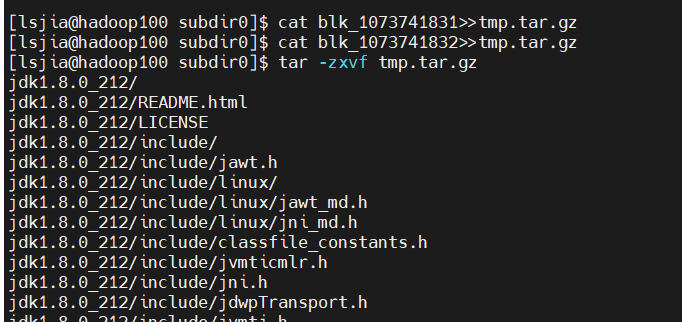
- 查看HDFS在磁盘存储文件内容

- 拼接其他两个数据包,发现文件就是上传的jdk。
1.3.3 下载文件

- 查看文件

- 执行wordcount程序

1.4 停止Hadoop集群
1.4.1 各模块分开启动/停止
在配置ssh的前提下- 整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
- 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
1.4.2 各服务组件逐一启动/停止
- 分别启动/停止HDFS组件
hdfs —daemon start/stop namenode/datanode/secondarynamenode
- 启动/停止YARN
yarn —daemon start/stop resourcemanager/nodemanager
1.5 Hadoop集群常用脚本
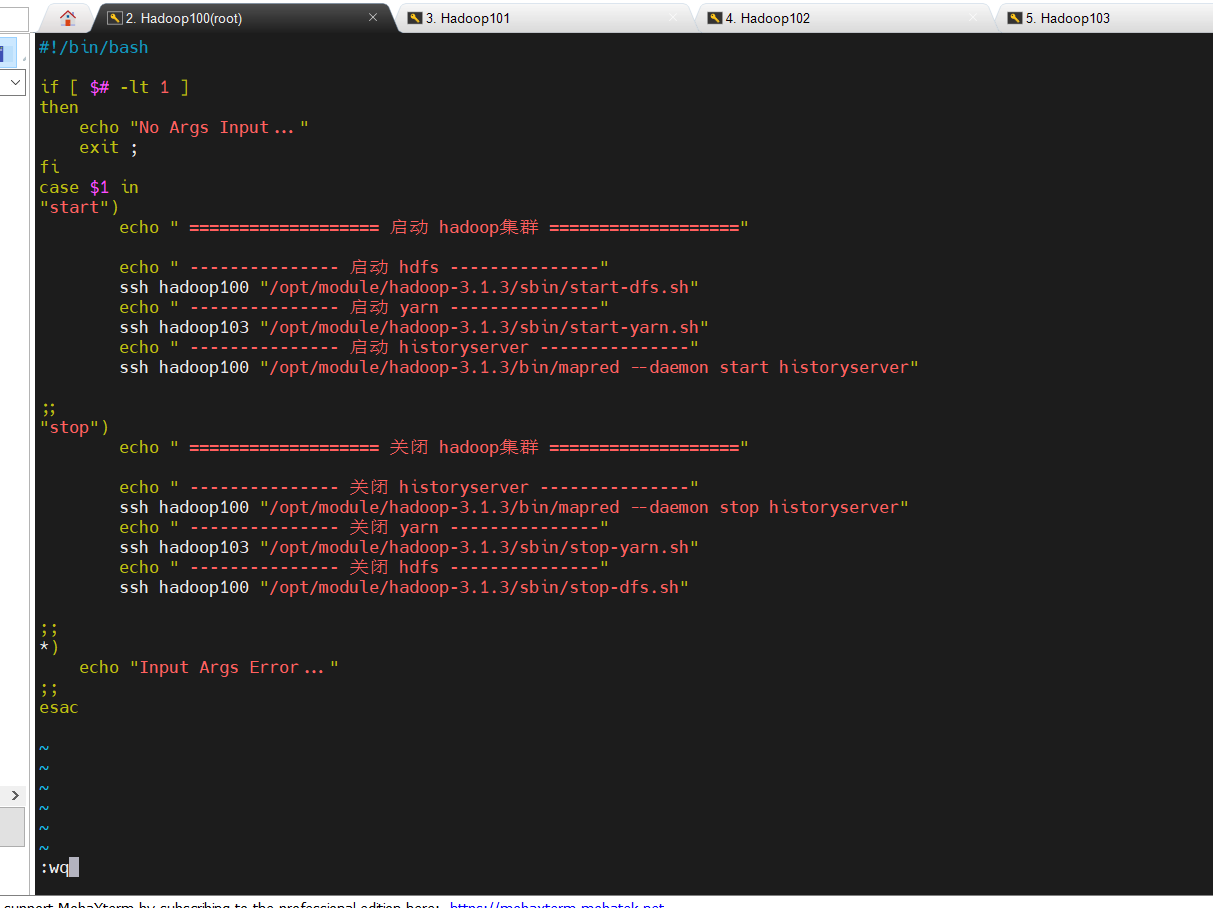
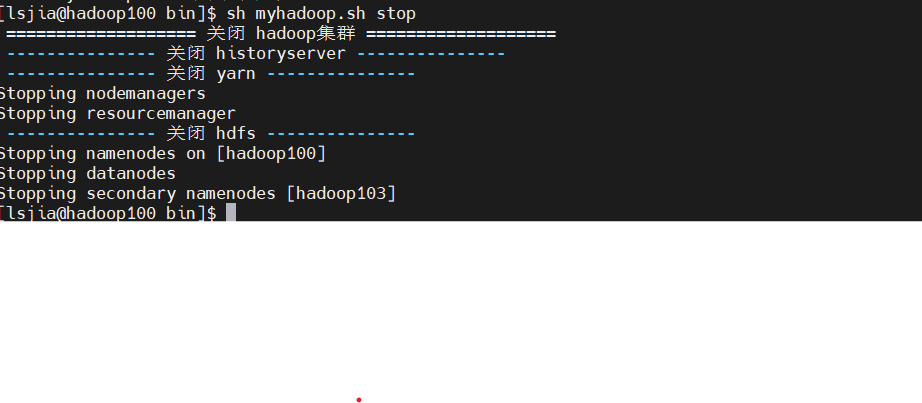
1.5.1 Hadoop集群启停脚本
包含HDFS,Yarn,Historyserver:myhadoop.sh

1.5.2 查看进程脚本
查看三台服务器Java进程脚本:jpsall
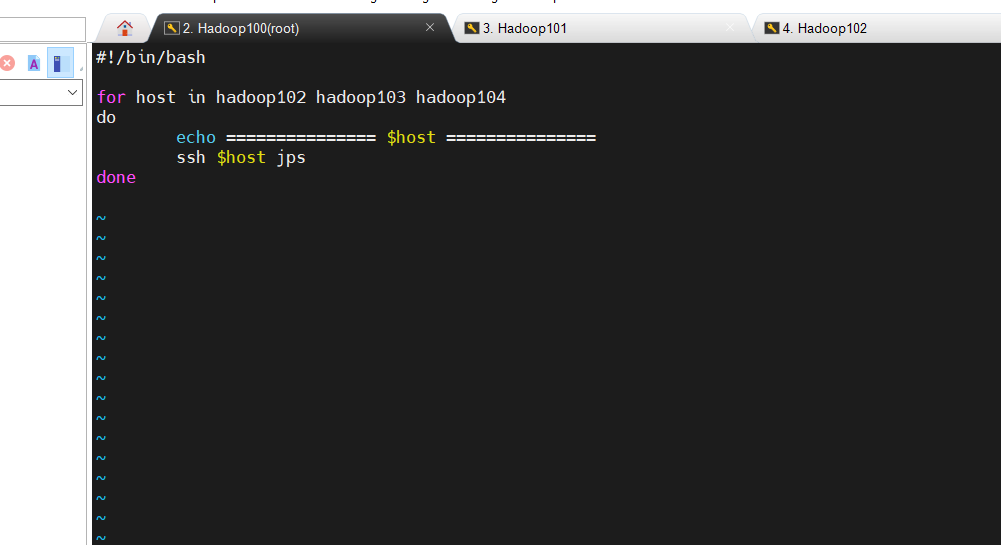

1.5.3 脚本分发
分发/home/li/bin目录,保证自定义脚本在三台机器上都可以使用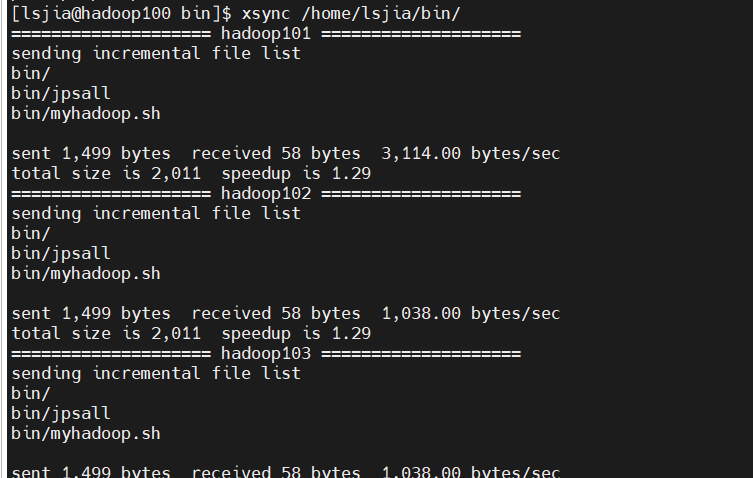

若有收获,就点个赞吧
0 人点赞
