Spark SQL
2021-07-04
问题:read.json无法读取json
Exception in thread “main” org.apache.spark.sql.AnalysisException: Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the
referenced columns only include the internal corrupt record column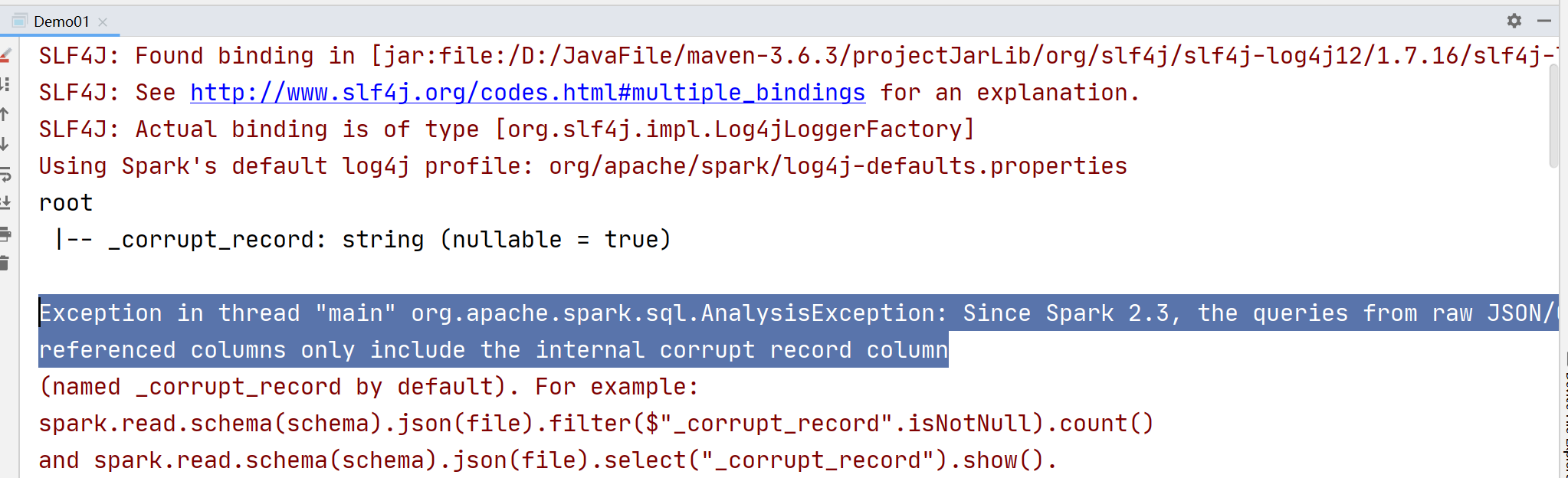
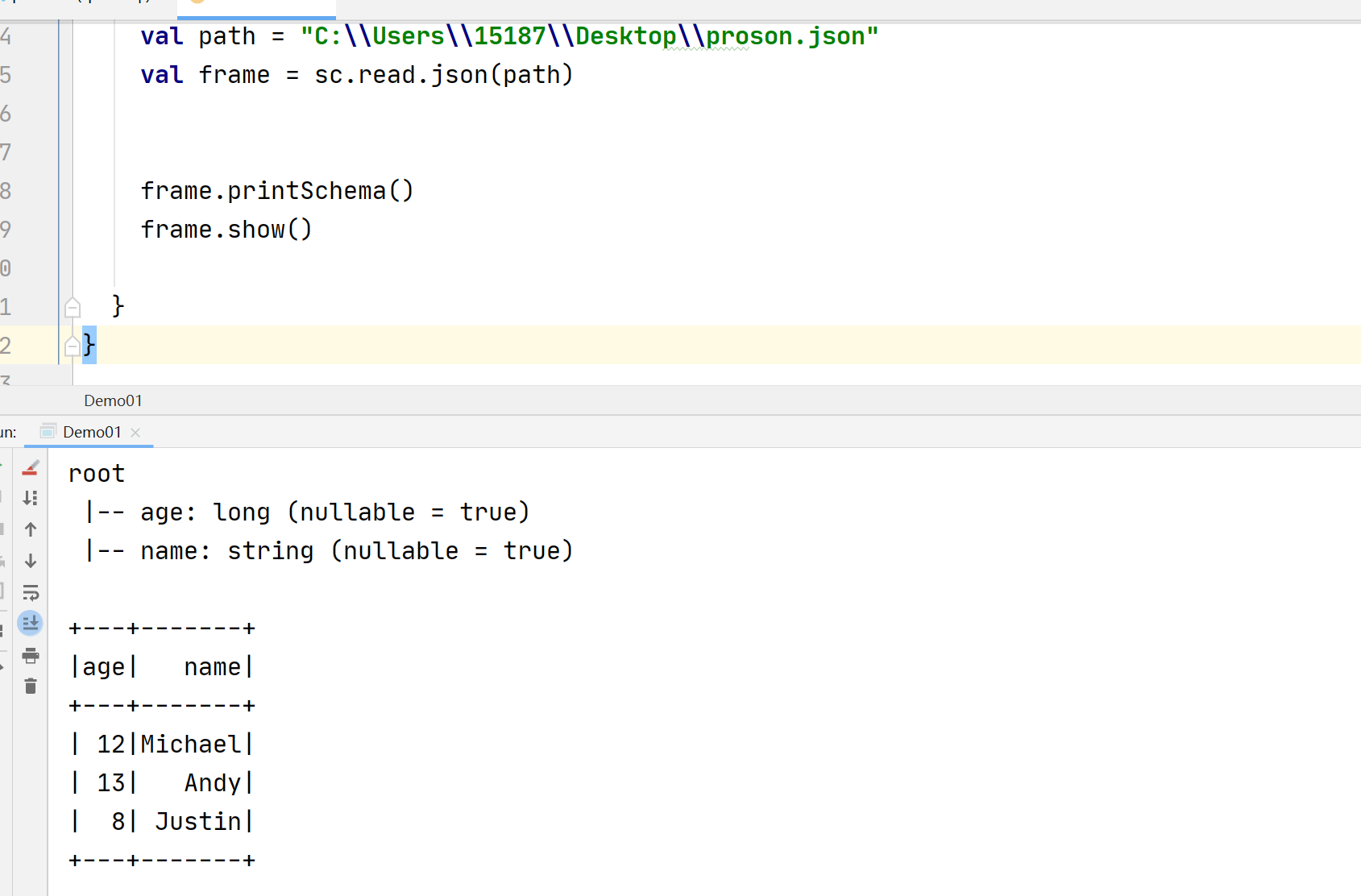
原因:JSON文件格式不对(中文需要特殊处理,要加空格)
2021-07-11
问题:运行时读取的数据库不是MySQL
报错内容:
21/07/11 14:13:39 ERROR Schema: Failed initialising database.
Unable to open a test connection to the given database. JDBC url = jdbc:derby:;databaseName=metastore_db;create=true, username = APP. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ———
java.sql.SQLException: Failed to start database ‘metastore_db’ with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@b1f36e5, see the next exception for details.
原因:在hive-site.xml里面,搜索不到MySQL的配置(主要发生在CDH的cm安装上,其他情况一般不会)
解决办法:手动把MySQL的信息配置即可。
<!--upsert into --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://10.168.1.12:3306/metastore</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>password</value></property>
问题:动态分区导致无法创建
报错内容:
Exception in thread “main” org.apache.spark.SparkException: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:157)
原因:
因为要做动态分区, 所以要先设定partition参数
由于default是false, 需要额外下指令打开这个开关
default是strick, 表示不允许动态分区, 所以要改成nostrick
解决方式:代码中设定
// 做动态分区, 所以要先设定partition参数// default是false, 需要额外下指令打开这个开关ss.sqlContext.setConf("hive.exec.dynamic.partition;","true");ss.sqlContext.setConf("hive.exec.dynamic.partition.mode","nonstrict");
Tips:在获取连接时指定config,或者连接后设置setConf均可。
2021-07-21
问题:SparkStreaming序列化Kafka数据失败
java.io.NotSerializableException: org.apache.kafka.clients.consumer.ConsumerRecordSerialization stack:- object not serializable (class: org.apache.kafka.clients.consumer.ConsumerRecord, value: ConsumerRecord(topic = demoTopic, partition = 0, offset = 73724625, CreateTime = 1626837252102, serialized key size = 8, serialized value size = 59, headers = RecordHeaders(headers = [], isReadOnly = false), key = 73637709, value = 2021-07-21 11:14:12,2021-07-21,73637709,刘慕青,31.941786))- element of array (index: 0)- array (class [Lorg.apache.kafka.clients.consumer.ConsumerRecord;, size 11)at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
解决方式:在构造SaprkConf的时候,添加序列化方法:
.set(“spark.serializer”,”org.apache.spark.serializer.KryoSerializer”)
val ssc = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("Kafka_To_Kudu").set("spark.serializer","org.apache.spark.serializer.KryoSerializer"), Seconds(1))
2021-08-31
问题:SparkSQl读取Kudu写入Hive分区报错
21/08/31 10:00:20 ERROR main.JustMain$: Output Hive table `realtimebakup`.`dcs_unit1_bakup` is bucketed but Spark currently does NOT populate bucketed output which is compatible with Hive.;org.apache.spark.sql.AnalysisException: Output Hive table `realtimebakup`.`dcs_unit1_bakup` is bucketed but Spark currently does NOT populate bucketed output which is compatible with Hive.;at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:180)
解决:取消分桶,同时取消排序
beeline> set hive.enforce.bucketing=false;beeline> set hive.enforce.sorting=false;
也可以修改hive-site.xml
<property><name>hive.enforce.bucketing</name><value>false</value></property><property><name>hive.enforce.sorting</name><value>false</value></property>
代码中修改:
// 做动态分区, 所以要先设定partition参数// default是false, 需要额外下指令打开这个开关ss.sqlContext.setConf("hive.exec.dynamic.partition;", "true");// 非严格模式ss.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict");// 设置关闭分桶与排序操作,否则写入hive会报错:// ... is bucketed but Spark currently does// NOT populate bucketed output which is compatible with Hivess.sqlContext.setConf("hive.enforce.bucketing","false")ss.sqlContext.setConf("hive.enforce.sorting","false")log.info("获取SparkSession:" + ss)
问题:SparkSQL在HDFS生成多个文件
解决方式:使用groupby + 设置reduce数量
spark控制小文件的原理和hive一致,执行group by或distribute by强制触发reduce操作,达到控制小文件的目的。
insert into table TABLE_NAMEselect ...... group by col;insert into table TABLE_NAMEselect ...... distribute by rand();
设置reduce数量的语法和hive稍有不同
set spark.sql.shuffle.partitions=X;
如果reducer的数量设置的过小,而数据本身较大的情况下,可能会出现数量大量流入少量的几个节点,导致程序在最后的环节运行缓慢,因此也不是X设置的越小越好,需要视具体情况权衡选择。
2021-12-13
问题:IDEA无法运行Spark程序
报错内容:
scalac: Token not found: C:\Users\xjr76\AppData\Local\JetBrains\IdeaIC2021.1\compile-server\tokens\3200
原因未知(可能是太久没运行了),解决办法:plugin里面,禁用Scala,然后启用,根据提示重启IDEA。

若有收获,就点个赞吧
0 人点赞
