Immutable.js与函数式编程概念介绍
原文Introduction to Immutable.js and Functional Programming Concepts,作者Sebastián Peyrott
这几年函数式编程逐渐火了起来。例如Clojure、Scala和Haskell这些编程语言已经吸引了很多对新技术着迷的程序员们的眼球,因为他们在某些方面有着巨大的优势。Immutable.js的目标是把其中的一些优势通过简单直观的API带到Javascript中来。请跟着我们通过这篇文章来学习这些(benefits)并运用到你的项目中。
介绍:不可变(immutability)和Immutable.js
尽管函数式编程的特变不仅仅在于其不可变,但很多的函数式语言都把不可变作为一个重点。例如Clojure和Haskell,都对数据如何改变和何时能够改变做出了严格的编译时限制。正因这一点,许多开发者便放弃了这些语言。对于那些能够忍受住最初的煎熬的人们来说,解决问题的新方式开始变得多样起来。特别是对于初次接触的人来说,数据结构是函数式范式的主要的争议点。
在这篇文章的末尾,是关于可变与不可变数据结构的比较,充满了冷酷的、复杂的数学概念。让逻辑分析告诉我们到底是哪一种数据结构最适合处理哪些问题。然而仅通过语言自身的支持来帮助实现这些数据结构可能会绕一段远路。集合了多范式语言优点的Javascript语言,为可变和不可变数据结构都提供了一个方便的平台。其它的一些语言,比如C语言,虽然也能够实现不可变数据结构,但是,这个语言本身的限制让这样变得很笨重。
那么到底什么是“变化(mutation)”呢?对于数据或者数据结构来说,“变化”是它们的一种内在的改变。而对于不可变来说,在改变之前必须要先对目标数据或者数据结构做一份拷贝

那么函数是数据结构的信条是什么呢?是什么使得不可变如此重要?它们的正确使用方式是什么?这些问题我们下边会提到。
注意:你可能在你的Javascript代码中已经使用了某个函数式编程语言的结构,但是你可能并不知道这一点。举个例子,
Array.map通过对一个数组中的每一个元素提供一个函数,然后返回一个新的数组,但在这个过程中不会修改原始数据。函数式编程喜欢使用一等(first-class)函数,它们能被传入到别的函数中,并且返回已存在数据的新版本,这实际上就是Array.map所做的工作。这种处理数据的方式也喜欢函数式编程中的另一个核心概念——组合。
核心内容
这些是函数式编程的核心内容,通过这篇文章,你会知道这些概念如何适用在Immutable.js和其他的函数式类库的设计和使用之中的。
不可变
不可变是指在数据(和管理它的数据结构)被实例化之后,不允许“变化”发生。在实践中,“变化”能够分为两派:可见变化和不可见变化。可见变化是指那些可以被外部观察者通过API记录下来的,数据或者数据结构的变化。相对的,不可见变化是指那些不能够被外部观察者通过API(缓存数据结构是一个很好的例子)。在某种意义上,不可见变化能看作是一种副作用(我们将会在下面提到并解释这个概念)。函数式编程的上下文中,不可变通常不允许这两种修改:不仅数据是默认不可变的,而且在数据结构本身一旦在实例化之后也没有改变。
var list1 = Immutable.List.of(1, 2);// 我们需要通过返回值来获取结果:// list1没有被修改!var list2 = list1.push(3, 4, 5);
有趣的优势便体现出来了,因为开发者(编译器/运行时)能够确定数据不能修改,所以:
- 为多线程加锁不再是一个问题:当数据不可变时,再也不需要使用锁来保持多线程的同步了。
- 持久化(下面将提到的一个重要概念)变得容易。
- 拷贝变成了一个常量时间的操作:拷贝只是简单的为已存在的数据结构创建一个新的引用。
- 值比较在特定的情况下可以被简化:此时运行时或编译器能确保,一个特定的实例只有在指向相同的引用时才会是相等的,便能通过引用比较来替代深层比较。这通常只可用在编译或者加载时数据可用的情况下。这样的优化也可以被手动控制(React和Angular就是这样做的,在文章末尾会做出解释)
你已经在使用一个不可变数据结构:String
在javascript中String是不可变的。在String的所有原型方法要么是只读操作,要么返回一个新的String。
一些Javascript运行时使用这个优势来增强性能:在加载或者JIT编译阶段,运行时能把String之间的比较(通常是在字符串字面值之间)简化为引用不叫。你通过一个简单的JSPerf测试看看你的浏览器是否是这样处理的。
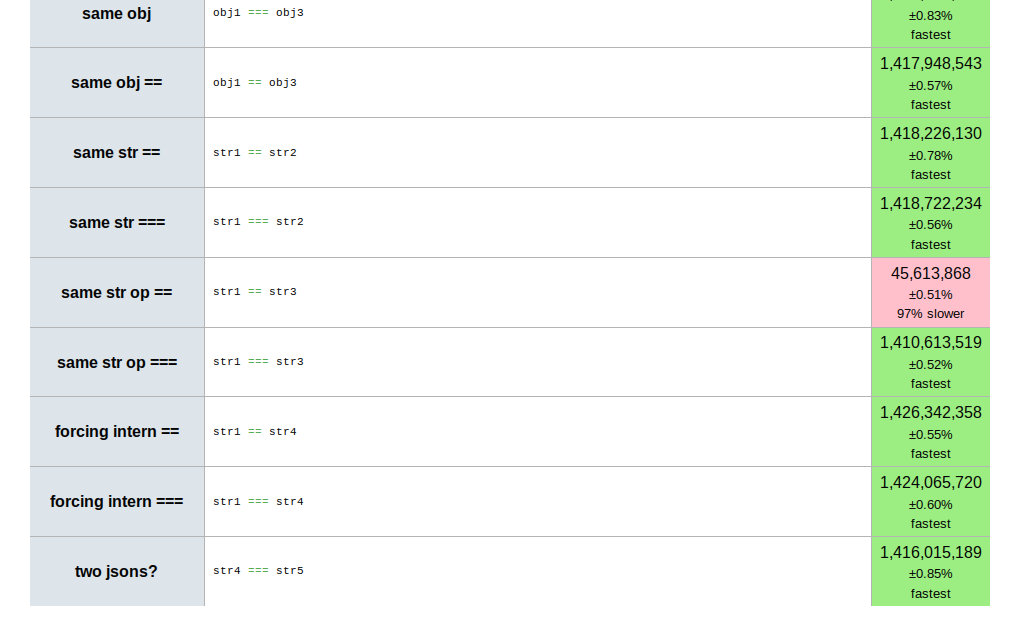
不可变与Object.freeze()
Javascript是一个动态、弱类型的语言(或者是无类型,如果你熟悉编程语言理论的话)。正因如此,有时难以强制对对象和数据的某些约束。Object.freeze()帮我们解决了这个问题。对Object.freeze的调用标志着这个对象的所有属性都成为不可变的。对它的修改要么不成功,要么抛出一个异常(在严格模式下)。如果你正写一个不可变对象,在完成初始化之后调用Object.freeze能帮上忙。
请牢记Object.freeze()是浅操作:这个对象的子对象依然能够被修改。为了解决这个问题,Mozilla提供了这个函数的一个deepFreeze版本,如下:
function deepFreeze(obj) {// 取出这个对象中的所有propertyvar propNames = Object.getOwnPropertyNames(obj);// 在冻结自己之前,先把所有的property冻结propNames.forEach(function(name) {var prop = obj[name];// 如果是一个object,则冻结if (typeof prop == 'object' && prop !== null) {deepFreeze(prop);}});// 冻结自己(如果已被冻结则什么也不会发生)return Object.freeze(obj);}
副作用
在编程语言理论中,对任意操作(通常是一个函数或者方法调用)的副作用是指可以在这个函数外部被观察到的改变。换句话来说,就是能够在调用后找到状态中的变化。每一个调用都会改变一些状态。与“不可变”的概念作对比,“不可变”通常与数据或者数据结构有联系,而副作用通常与整个程序的状态有关联。保护一个数据结构实例的函数会导致副作用发生。缓存函数(caching functions)或者说记忆函数(memoization)便是这样一个很好的例子。即使对于外部观察者来说这好像不会导致什么改变发生,但是更新一个全局或者局部缓存会更新其内部数据结构,以便让缓存起效,而这也是一个副作用(让运算加速也算是一个副作用)。开发者们需要注意到这些副作用并且合适地处理这些问题。
举个缓存的例子:一个不可变数据结构有一个作为前端的缓存,那么它将不能自由地传递到不同的线程中。这个缓存必须要支持多线程,否则将得到不可预知的结果。
函数式编程范式喜欢使用无副作用的函数。函数必须只对传入给自身的数据进行操作,并且这个操作的修改只能被调用者发现。不可变数据结构调用一个接一个的无副作用函数。
var globalCounter = 99;// 这个函数改变了全局状态function add(a, b) {++globalCounter;return a + b;}// 上面那个看起来无辜的add函数调用可能会对// 这个控制台的打印结果产生异常的修改function printCounter() {console.log(globalCounter.toString());}
纯
纯是一个可以被强加在函数中的附加条件:纯函数只依赖那些明确作为参数传入的参数来产生一个结果。换种说法,纯函数一定不能依赖全局状态或者可通过其他方式来访问的状态。
var globalValue = 99;// 这个函数是不纯的:如果globalValue改变,它的结果也会发生改变,// 即使传入的值a和b与之前的相同。function sum(a, b) {return a + b + globalValue;}
引用透明
一个具有无副作用的纯函数是引用透明的。在任何时候把相同的参数传递给一个引用透明的函数可以获取相同的结果,因为这一整个计算过程不可能发生改变。
你可能已经注意到了,这对于数据和代码的行为有着更高的约束。即使这些导致了灵活性的降低,但要意识到这在分析和证明中的重要优势。很容易证明具有无副作用的不可变数据结构能被传入不同的线程之中,而且不必担心是否需要加锁等。
function add(a, b) {return a + b;}// 下面的调用能被它的结果3所取代。因为它的引用透明让这样成为可能。换句话说,它是无副作用的纯函数var r1 = add(1, 2); // r1 = 3;
持久化(Persistence)
我们在前面已经看到,不可变使得某些操作变得更简便。使用不可变数据结构的另一个优势是持久化。在数据结构的上下文中,持久化指原始的数据结构在进行更新后,仍旧能够保持原来的样子。
我们前面提到,当对不可变数据结构进行写入操作时,与其让数据结构本身或者其数据发生变化,不如让它返回更新后的数据结构。然而在大多数情况下,相对数据或者数据结构的大小来说,改变都是非常微不足道的,进行一次整个数据结构的深拷贝操作不是最优的解决办法。大多数不可变数据结构算法,都是利用原始数据不可变的优势,只对需要修改的数据(和数据结构的某些部分)进行拷贝操作。
部分持久化数据结构支持对一个数据的最新版本进行修改及对它旧版本的只读操作。完全持久化数据结构则允许对数据的所有版本进行读写。注意在所有情况下,对数据的写入或修改操作意味着为这个数据结构创建一个新的版本。
可能不是很明显,之前的数据结构都被垃圾回收了,而不是保持引用计数或者需要手动进行内存管理。当每一次改变产生一个新的版本时,因为之前的版本也需要依然可用,所以在每次改变发生时,都需要对原数据创建一个新的引用。在手动内存管理方案下,快速追踪那些已存在引用的部分非常麻烦。另一方面,从开发者的角度来看,引用计数使得工作变得容易许多,但从算法的角度来看,这却是非常低效的:每当改变发生时,必须要对已改变数据的引用计数进行更新。更何况这个不可见的改变实际上也是一个副作用。正因如此,它限制了某些优势的适用范围。在另一方面,垃圾回收也没有带来这些问题。你可以自由地对已存在数据进行引用。
在下面的例子中,在原始List创建后的每一个版本都是可用的(通过每次的变量绑定):
var list1 = Immutable.List.of(1, 2);var list2 = list1.push(3, 4, 5);var list3 = list2.unshift(0);var list4 = list1.concat(list2, list3);
惰性求值
惰性操作是不可变所带来的另一个不那么显而易见的优势。惰性操作是指在需要获取操作结果(通常是指一个需要立即进行的求值操作)之前,不进行任何的操作。不可变在惰性操作上下文中起了很大的作用,因为惰性求值通常只在之后执行一次操作。如果数据与此操作有关联,那么在操作的开始和结束之间,若数据发生改变,那么这个操作便不能正常地执行。不可变数据能帮助我们解决这个问题,因为惰性操作能被构造成不发生改变的确定的数据。换种说法,不可变允许惰性求值作为一种求值策略。
在Immutable.js中支持惰性操作:
var oddSquares = Immutable.Seq.of(1,2,3,4,5,6,7,8).filter(x => x % 2).map(x => x * x);// 只有在需要获取结果的时候才会进行计算操作console.log(oddSquares.get(1)); // 9
惰性求值有一些优势,最重要的优势便是不需要的数值不会参与计算。例如,想象一个由1到10组成的List,然后对其中的每个元素执行两个不同的函数。我们把第一个函数命名为plusOne,第二个命名为plusTen。这两个函数的意思很明显,前者把参数加1,后者加10。
function plusOne(n) {return n + 1;}function plusTen(n) {return n + 10;}var list = [1,2,3,4,5,6,7,8,9,10];var result = list.map(plusOne).map(plusTen);
你可能已经注意到了,这很没有效率:在map中的循环进行了两次,即使result还没有被用上。假设你只需要第一个元素,在立即求值的情况下会进行两个完整的循环求值操作。如果是惰性求值,直到请求的结果被返回,才会进行循环操作,如果只需要获取result[0]的值,每个循环只会调用一次plus...操作。
惰性求值也可以支持无穷数据结构。在惰性求值的支持下,一个从1到无穷大的序列能够被安全地表达出来。惰性求值也能允许无效数据:如果无效数据在一次计算过程中没有被用到,那么只会对那些有效数据进行操作(但这可能导致异常或者其他错误情况)。
某些函数式编程语言也能在可以使用惰性求值时进行高级优化,例如deforestration或者循环合并操作。实质上这些优化把多个循环操作转变成了单个循环,或者换种说法,移除了中间数据结构。在上面的例子中,两次map函数调用实际上转变为了一次map调用,在一个循环中调用了plusOne和plusTen两个函数。干得漂亮,对吧?
然而,对于惰性求值来说,也不是十全十美的:对任意表达式的求值和计算进行的时机变得不是那么好把控。分析某个复杂的惰性操作可能会异常困难。另一个坏处是空间泄漏:因为要存储接下来计算必须用到的数据从而导致泄漏。某些惰性结构可能导致数据无限增长,这也可能导致问题。
组合
在函数式编程语言中,组合指的是把多个不同的函数组合成一个全功能的函数。一等函数(函数能像数据一样被平等对待,能够传递给其他函数),闭包和柯里化(可以认为是Function.bind操作)是组合中必须用到的工具。对于组合来说,Javascript的语法与某些函数式编程语言相比不是很方便,但它也能达成目的。合适的API设计同样能产生好的结果。
不可变的惰性与组合相结合,产生了方便的、可读性好的Javascript代码:
Immutable.Range(1, Infinity).skip(1000).map(n => -n).filter(n => n % 2 === 0).take(2).reduce((r, n) => r * n, 1);
备用方式:变化
尽管不可变提供了一些好处,但是某些操作和算法只在可变时有效。不可变是大多数函数式编程语言(与命令式语言相对)的默认行为,因为变化通常会影响这些操作的实现。
var list1 = Immutable.List.of(1,2,3);var list2 = list1.withMutations(function (list) {list.push(4).push(5).push(6);});
算法考虑
在算法和数据结构的领域没有免费的午餐。在一个方面内取得进步通常会导致另一方面的退步,不可变也不例外。我们已经讨论了不可变的一些优势:易持久化,简化推理,避免锁的使用等,那么它的劣势是什么呢?
当听论算法时,时间复杂度可能是你应该最先考虑的。不可变数据结构有着不同的运行时特性。特别是当考虑持久运行需求的情况下,不可变数据结构通常有着更优异的运行时特性。
以单链表作为例子便能体现出它们的不同之处。单链表是由多个结点组成的List,其中每一个结点都指向下一个结点(但不会指向前一个)。
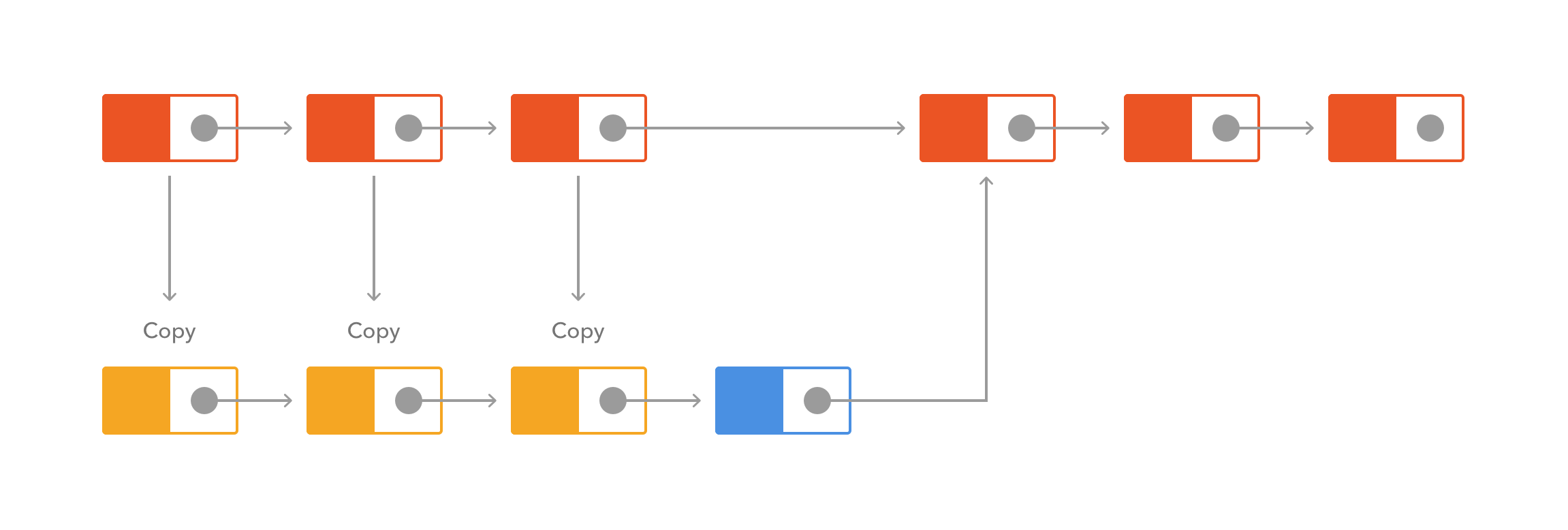
一个可变的单链表有如下的时间复杂度(最坏情况下,假设前、后和插入的结点都已知):
- 头部插入:O(1)
- 尾部插入:O(1)
- 中间插入:O(1)
- 查找:O(n)
- 拷贝:O(n)
相比之下,一个不可变数据结构的单链表有如下的时间复杂度(最坏情况下,假设前、后和插入的结点都已知):
- 头部插入:O(1)
- 尾部插入:O(n)
- 中间插入:O(n)
- 查找:O(n)
- 拷贝:O(1)
如果你还不熟悉时间复杂度分析和大O表示法,请阅读这篇文章
这里没有为不可变数据结构画一张图,但是,最坏情况时间复杂度分析没有考虑到持久运行的需求。换种说法,如果可变数据结构遵守这个需求的话,运行时复杂度也很可能和不可变的一样(至少对于这些操作来说)。写时复制和其他的技术可以优化这些操作的平均时间,但这并不在最坏情况分析的考虑范围内。
进行最坏情况分析可能不能代表数据结构的真正水平,平摊分析(Amortized analysis)把数据结构作为一组操作来考虑。通过好的平摊分析,数据结构虽然偶尔可能显示出最坏的时间的情况,但是仍然比其他方式要好很多。在一个动态的数组扩充到到它原始长度的两倍时,一个元素需要被移动到这个数组的尾部,这时便能体现出平摊分析的有理之处。最坏情况分析为尾部插入给出了O(n)的时间复杂度,而平摊分析能给出O(1)的时间复杂度,因为N/2次插入操作能在一个O(n)的时间内作为一次插入进行。一般来说,如果你的用例要求确定的运行时间,就不能考虑平摊分析了。其他情况下,通过平摊分析来对你的需求进行细致的分析会有更好的表现。
时间复杂度分析也忽略了其他一些重要的考虑因素:使用某个数据结构是如何影响到它周围的代码?比如说,当使用一个不可变数据结构时,在多线程环境中锁就是没有必要的了。
CPU缓存考虑
针对于高性能计算机来说,另一个需要考虑的事就是数据结构是如何与隐含的CPU缓存协同工作的。一般来说,可变数据结构的局部性是更好的(除非持久化被过度使用),这使得写操作的性能更高。
内存使用
不可变数据结构导致了天生的内存使用不稳定。在每次修改之后,都要进行拷贝操作。如果这些拷贝是不必须的,垃圾回收器会在下一次清理中回收旧的数据碎片。只要旧的、未被使用的数据拷贝未被回收,就会导致这样的情况发生。在需要持久化的情况下就不会发生这样的情况。
你可能已经注意到了,当考虑持久化的时候,不可变就变得非常有吸引力。
示例:React DBMon跑分
以我们之前的进行过的跑分为基础,我们决定在合适的地方使用Immutable.js来更新我们的React DBMon跑分。从实质上来讲,在每一次的迭代之后都会更新所有的数据,选择React+Immutable.js并不会获得什么优势:在状态改变后,不可变使得React能够避免深度相等检查,如果所有的状态在每一次迭代后都进行了修改,那么不可能会让这有什么优势。因此,我们修改例子,随机跳过一些状态修改。
// 通过跳过一些更新来测试重新渲染状态检查var skip = Math.random() >= 0.25;Object.keys(newData.databases).forEach(function (dbname) {if (skip) {return;}//(...)});
我们改变数据结构,把例子中原有的Javascript数组改变为不可变List。这个List作为一个参数传入一个待渲染的组件中。当React的PureRenderMixin被加入到这个组件中后,就可能使比较更有效率。
if (!this.state.databases[dbname]) {this.state.databases[dbname] = {name: dbname,samples: Immutable.List()};}this.state.databases[dbname].samples =this.state.databases[dbname].samples.push({time: newData.start_at,queries: sampleInfo.queries});if (this.state.databases[dbname].samples.size > 5) {this.state.databases[dbname].samples =this.state.databases[dbname].samples.skip(this.state.databases[dbname].samples.size - 5);}
var Database = React.createClass({displayName: "Database",mixins: [React.PureRenderMixin],render: function render() {//(...)}//(...)});
这种情况包含了不可变的所有优势。如果数据没有被修改,那么就不需要再对DOM树进行重绘。
和我们之前的跑分一样,我们使用browser-perf来检测它们的差异,这是Javascript代码运行的总时间:

可以在这里查看完整的跑分情况
题外话:在Auth0中Immutable.js的运用
爱的Auth0,我们总是尝试使用新库,Immutable.js也不例外。在我们的lock-next(我们的下一代lock库,仍然在进行内部开发)和lock-passwordless项目中,Immutable.js已经有了它独一无二的使用方式。这两个库都是通过React来开发的。由于对相等判断的优化,使得用不可变数据来渲染React组件可以获得极大的性能提高:当两个对象有着相同的引用,并且都是不可变对象时,就能够确定其内部的数据没有发生改变。React取决于是否对象发生改变来重新渲染对象,不可变对象使得它没有了深度判断的必要。
在Angular.js应用中也能使用相似的优化
结论
感谢函数式编程语言,它们将不可变和其它相关概念的优势都使用到了。在使用Clojure、Scala和Haskell等编程语言开发的项目逐渐发展起来之后,这些语言所大力提倡的相关概念带来了较高的占有率。不可变便是这些干点之一:对于分析、持久化、拷贝和比较来说都带来了显而易见的优势,不可变数据结构都有了自己的特殊使用情况,甚至已经运用在你的浏览器当中。与往常一样,当到了算法和数据结构中,就需要对不同情景的仔细分析,来选择正确的工具。基于性能、内存使用、CPU缓存行为以及对数据进行操作的形式的考虑都变得非常有必要,以便让你决定不可变是否适合你的情况。Immutable.js和React结合使用的例子便清晰地展示了其在项目中的巨大优势。
如果这篇文章激起了你对于函数式编程和数据结构方面的兴趣,我就不得不强力推荐Chris Okasaki的Purely Functional Data Structures。这是一本非常棒的书籍,介绍了函数式数据结构在这样场景下是如何工作的,以及如何有效地使用它们。

若有收获,就点个赞吧
0 人点赞
